A few months ago, while lying in bed one night, a thought flashed through my head — “If voice is the future of computing interfaces, what about those who cannot hear or speak?”. I don’t know what exactly triggered this thought, I myself can speak and hear and have no one close to me who is either deaf or mute, nor do I own a voice assistant. Perhaps it was the countless articles…
A few months ago, while lying in bed one night, a thought flashed through my head — “If voice is the future of computing interfaces, what about those who cannot hear or speak?”. I don’t know what exactly triggered this thought, I myself can speak and hear and have no one close to me who is either deaf or mute, nor do I own a voice assistant. Perhaps it was the countless articles popping up on the proliferance of voice assistants, or the competition between large companies to become your voice activated home assistant of choice, or simply seeing these devices more frequently on the counter tops of friends’ homes. As the question refused to fade from memory, I knew it was an itch I needed to scratch.
It eventually led to this project, a proof of concept where I got an Amazon Echo to respond to sign language — American Sign Language (ASL) to be more precise, since similar to spoken language there are a variety of sign languages as well.
While I could have simply released the code, I instead chose to post a video demonstrating the system, since I feel a lot of machine learning projects lack a visual element, making it difficult for people to relate to and understand them. Also I hoped this approach would help switch the focus away from the tech element of the project and instead shine light on the human element — that it’s not about the underlying tech but the capabilities that such tech provides us as humans.
Now that the video is out, this blog post takes a look at the underlying tech and how the system is built using TensorFlow.js. There’s also a live demo you can play with. I put it together so you can train it on your own set of word and sign/gesture combos. Having an Echo nearby that can respond to your requests is entirely optional.
Early Research:
The broader pieces of the system I wanted to put together for this experiment were quite clear in my head early on. I knew I needed:
A neural network to interpret the signs (i.e. convert video of signing into text).
A text to speech system to speak the interpreted sign to Alexa
A speech to text system to transcribe the response from Alexa for the user
A device (laptop/tablet) to run this system and an Echo to interact with
An interface that ties this all together
I probably spent the most time early on trying to decide what neural net architecture would be best suited for this. I came up with a few options:
1) Since there is both a visual and temporal aspect to a sign, my gut was to combine a CNN with an RNN where the output of the last convolutional layer (before classification) is fed into an RNN as sequences. The technical term for these I later discovered is Long-Term Recurrent Convolutional Networks (LRCN).
2) Use a 3D convolutional network where the convolutions would be applied in three dimensions, with the first two dimensions being the image and the third dimension being time. However these networks require a lot of memory and I was hoping to train whatever I could on my 7 year old macbook pro.
3) Instead of training a CNN on individual frames from a video stream, instead train it only on optical flow representations which would represent the pattern of apparent motion between two consecutive frames. My thinking with this was that it would encode the motion which would lead to a more general model for sign language.
4) Use a Two Stream CNN where the spatial stream would be a single frame (RGB) and the temporal stream would use the optical flow representation.
Further research led me to discover a few papers which had used at least some of the above methods for video activity recognition (most commonly on the UFC101 dataset). However, I soon realized that it wasn’t just my computing power that was limited but also my ability to decipher and implement these papers from scratch and after months of occasional research and regularly dropping the project for other projects I had no promising output to show.
The approach I finally settled on was entirely different.
Enter TensorFlow.js:
The TensorFlow.js team has been putting out fun little browser based experiments both to familiarize people with the concepts of machine learning and also to encourage their use as building blocks for your own projects. For those unfamiliar with it, TensorFlow.js is an open source library that allows you to define, train and run machine learning models directly in the browser using Javascript. Two demos in particular seemed interesting starting points — Pacman Webcam Controller and Teachable Machine.
While they both take an input image from the webcam and output a prediction based on the training data, internally each operates differently:
1) Pacman Webcam — This uses a Convolutional Neural Network (CNN) where it takes an input image (from the webcam) and passes it through a series of convolutional and max pooling layers. Using this it is able to extract the main features of the image and predict its label based on examples it has been trained on. Since training is an expensive process, it uses a pre-trained model called MobileNet for transfer learning. This model is trained on the 1000 ImageNet classes but optimized to run in browsers and mobile apps.
2) Teachable Machine — This uses a kNN(k-Nearest-Neighbours) which is so simple that technically it does not perform any “learning” at all. It takes an input image(from the webcam) and classifies it by finding the label of training examples that are closest to this input image using a similarity function or distance metric. However prior to feeding the kNN, the image is first passed through a small neural network called SqueezeNet. The output from the penultimate layer of this network is then fed into the kNN which allows you to train your own classes. The benefit of doing it this way, instead of directly feeding raw pixel values from the webcam into the kNN is that we can use the high level abstractions that SqueezeNet has already learned, thus training a better classifier.
Now at this point you might be wondering, what about the temporal nature of the signs? Both these systems take an input image every frame and make a prediction with zero consideration for the frames before them. Wasn’t that the entire point of looking at RNN’s earlier? Isn’t that necessary to truly understand a sign? Well, while learning ASL for this project from online resources, I realized that when performing a sign, the start and end gestures and positions of your hand vary greatly from one sign to another. While everything that happens in between might be necessary to communicate with another human, for a machine using just the start and end should be sufficient. Thus contrary to the popular adage, instead of focusing on the journey I decided to look only at the destinations instead.
Deciding to use TensorFlow.js proved helpful for other reasons as well:
I could use these demos to prototype without writing any code. I began early prototyping by simply running the original examples in the browser, training them on gestures I intended to use and see how the system performed — even if the output meant pac-man moving on the screen.
I could use TensorFlow.js to run models directly in the browser. This is huge, from a standpoint of portability, speed of development and ability to easily interact with web interfaces. Also the models run entirely in the browser without the need to send data to a server.
Since it would run in the browser, I could interface it well with Speech-to-Text and Text-to-Speech APIs that modern browsers support and I would need to use.
It made it quick to test, train and tweak which is often a challenge in machine learning.
Since I had no sign language dataset, and the training examples would essentially be me performing the signs repeatedly, the use of the webcam to collect training data was convenient.
After thoroughly testing the two approaches and realizing that both systems performed comparably on my tests, I decided to use the Teachable Machine as my base since:
kNNs can actually perform faster/better than CNNs on smaller datasets. They become memory intensive and performance drops when training with many examples but since I knew my dataset would be small this was a non-issue.
Since kNNs aren’t really learning from examples, they are poor at generalization. Thus the prediction of a model trained on examples made up entirely of one person will not transfer well to another person. This again was a non-issue for me since I would be both training and testing the model by repeatedly performing the signs myself.
The team had open sourced a nice stripped down boilerplate of the project which served as a helpful starting point.
How it works
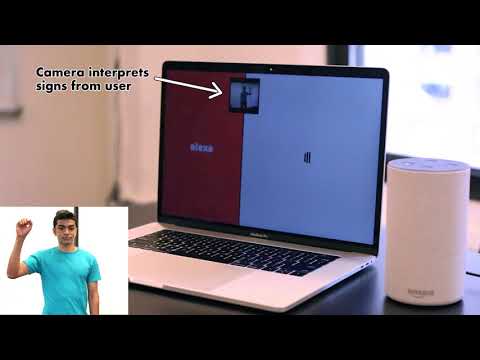
Here’s a high level view at how the system works start to end:
On launching the site in the browser, the first step is to provide training examples. What this means is using the webcam to capture yourself repeatedly performing each sign. This is relatively quick since holding down a particular capture button continuously captures frames till you release it and tags the captured images with the appropriate label. The system I trained contained 14 words which in various combinations would allow me to create a variety of requests for Alexa.
Once training is complete, you enter predict mode. It now uses the input image from a webcam and runs it through the classifier to find its closest neighbours based on the training examples and labels provided in the previous step.
If a certain prediction threshold is crossed, it will append the label on the left hand side of the screen.
I then use the Web Speech API for speech synthesis to speak out the detected label.
If the spoken word is ‘Alexa’ it causes the nearby Echo to awaken and begin listening for a query. Also worth noting — I created an arbitrary sign (right fist up in the air) to denote the word Alexa, since no sign exists for the word in ASL and spelling out A-L-E-X-A repeatedly would be annoying.
Once the entire phrase of signs is completed, I again use the Web Speech API for transcribing the Echo’s response which responds to the query clueless to the fact that it came from another machine. The transcribed response is displayed on the right side of the screen for the user to read.
Signing the wake word again, clears the screen and restarts the process for repeated querying.
I’ve also uploaded all the code on github and included live demo. Feel free to use and modify as you wish.
While the system worked relatively well, it did require some crude hacks to help get desirable results and improve accuracy, such as:
Ensuring no sign is detected unless the wake word Alexa has been said.
Adding an entire catch-all category of training examples which I categorized as ‘other’ for idle states (the empty background, me standing idly with my arms by the side etc). This prevents words from being erroneously detected.
Setting a high threshold before accepting an output to reduce prediction errors.
Reducing the rate of prediction. Instead of predictions happening at maximum frame rate, controlling the amount of predictions per second helped reduce erroneous predictions.
Ensuring a word that has already been detected in that phrase is not considered for prediction again.
Since sign language normally ignores signing articles and instead relies on context to convey the same, I trained the model with certain words that included the appropriate article or preposition e.g the weather, to the list etc.
Another challenge was accurately predicting when a user has finished signing their query. This is necessary for an accurate transcription. If transcription is triggered early (before the user has completed signing), the system will begin transcribing its own speech. A late trigger on the other hand might cause it to miss transcribing part of Alexa’s response. To overcome this, I implemented two independent techniques, each with their own set of pros and cons:
The first option is to tag certain words as terminal words when adding them for training. By a terminal word I mean a word that a user will only sign at the end of a phrase. For example if the query is “Alexa, what’s the weather?” then by tagging “the weather” as a terminal word, transcription can be triggered correctly when that word is detected. While this works well, it means the user has to remember to tag words as terminal during training and also relies on the assumption that this word will only appear at the end of a query. This means restructuring your query to instead ask “Alexa, what’s the weather in New York?” would be an issue. The demo uses this approach.
The second option is to have the user sign a stop-word as a deliberate way of letting the system know they are done with their query. On recognizing this stop-word the system can trigger transcription. So a user would sign Wakeword > Query > Stopword. This approach runs the risk of the user forgetting to sign the stop-word entirely leading to the transcription not being triggered at all. I’ve implemented this approach in a separate github branch where you can use the wake word Alexa as bookends to your query i.e “Alexa, what’s the weather in New York (Alexa)?”.
Of course, this entire problem could be solved if there was a way to accurately differentiate between speech coming from the internal source (the laptop) and speech from the external source (a nearby Echo), but that’s another challenge altogether.
Moving ahead, I think there are a number of other ways to approach this problem, which may serve as good starting points for your own projects to create more robust and general models:
Tensorflow.js also released PoseNet and using this could be an interesting approach. From the machines standpoint, tracking the position of the wrist, elbow and shoulder in the frame should be sufficient to make a prediction for most words. Finger positions tend to matter mostly when spelling something out.
Using the CNN based approach (like the pacman example) might improve accuracy and make the model more resistant to translational invariances. It will also help to better generalize across different people. One could also include the ability to save a model or load a pre-trained Keras model, which is well documented. This would remove the need for training the system every time you restart the browser.
Some combination of a CNN+RNN or PoseNet+RNN to consider the temporal features might lead to a bump in accuracy.
Use the newer reusable kNN classifier that’s included in tensorflow.js.
Since I first posted this project, it’s been shared extensively on social media, written about across the press and even Amazon implemented an accessibility feature (Tap to Alexa) on the Echo Show for those who might find it hard to speak. While I have no evidence if my project led to them implementing the feature (the timing is highly coincidental) it would be super cool if it did. I hope in the future, Amazon Show or other camera & screen based voice assistants, build this functionality right in. To me that’s probably the ultimate use case of what this prototype showed and holds the ability to open up these devices to millions of new people.
Cutting down the complexity of the network and settling on a simple architecture to create my prototype definitely helped to quickly get this project out there. My aim was not to solve the entire sign language to text problem. Rather, it was to initiate a conversation around inclusive design, present machine learning in an approachable light, and to inspire people to explore this problem space — something I hope this project achieved.
You can check out more of my projects on shek.it, follow me @shekitup or find the code for the project on my github
Next post
Community·TensorFlow.js·
Getting Alexa to Respond to Sign Language Using Your Webcam and TensorFlow.js
A few months ago, while lying in bed one night, a thought flashed through my head — “If voice is the future of computing interfaces, what about those who cannot hear or speak?”. I don’t know what exactly triggered this thought, I myself can speak and hear and have no one close to me who is either deaf or mute, nor do I own a voice assistant. Perhaps it was the countless articles…
 2) Teachable Machine — This uses a kNN(k-Nearest-Neighbours) which is so simple that technically it does not perform any “learning” at all. It takes an input image(from the webcam) and classifies it by finding the label of training examples that are closest to this input image using a similarity function or distance metric. However prior to feeding the kNN, the image is first passed through a small neural network called SqueezeNet. The output from the penultimate layer of this network is then fed into the kNN which allows you to train your own classes. The benefit of doing it this way, instead of directly feeding raw pixel values from the webcam into the kNN is that we can use the high level abstractions that SqueezeNet has already learned, thus training a better classifier.
2) Teachable Machine — This uses a kNN(k-Nearest-Neighbours) which is so simple that technically it does not perform any “learning” at all. It takes an input image(from the webcam) and classifies it by finding the label of training examples that are closest to this input image using a similarity function or distance metric. However prior to feeding the kNN, the image is first passed through a small neural network called SqueezeNet. The output from the penultimate layer of this network is then fed into the kNN which allows you to train your own classes. The benefit of doing it this way, instead of directly feeding raw pixel values from the webcam into the kNN is that we can use the high level abstractions that SqueezeNet has already learned, thus training a better classifier.
 Now at this point you might be wondering, what about the temporal nature of the signs? Both these systems take an input image every frame and make a prediction with zero consideration for the frames before them. Wasn’t that the entire point of looking at RNN’s earlier? Isn’t that necessary to truly understand a sign? Well, while learning ASL for this project from online resources, I realized that when performing a sign, the start and end gestures and positions of your hand vary greatly from one sign to another. While everything that happens in between might be necessary to communicate with another human, for a machine using just the start and end should be sufficient. Thus contrary to the popular adage, instead of focusing on the journey I decided to look only at the destinations instead.
Deciding to use TensorFlow.js proved helpful for other reasons as well:
Now at this point you might be wondering, what about the temporal nature of the signs? Both these systems take an input image every frame and make a prediction with zero consideration for the frames before them. Wasn’t that the entire point of looking at RNN’s earlier? Isn’t that necessary to truly understand a sign? Well, while learning ASL for this project from online resources, I realized that when performing a sign, the start and end gestures and positions of your hand vary greatly from one sign to another. While everything that happens in between might be necessary to communicate with another human, for a machine using just the start and end should be sufficient. Thus contrary to the popular adage, instead of focusing on the journey I decided to look only at the destinations instead.
Deciding to use TensorFlow.js proved helpful for other reasons as well:
 Here’s a high level view at how the system works start to end:
Here’s a high level view at how the system works start to end:
 Moving ahead, I think there are a number of other ways to approach this problem, which may serve as good starting points for your own projects to create more robust and general models:
Moving ahead, I think there are a number of other ways to approach this problem, which may serve as good starting points for your own projects to create more robust and general models: