https://blog.tensorflow.org/2018/09/introducing-model-optimization-toolkit.html?hl=ur
https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEgwXP7BuHot2koArH9S5nPmWm-wx-tdexWb-dMz2MV-zFMAwzc0noIgku3leoqWVxXg5wuLthrPvj2zE_RYpCbaOlNXPXdq0u7nhevDxB4vNckle9aaIIXF3-wTxM1ej6EWslT7FK7bJL4/s1600/watermelon.gif
We are excited to introduce a new optimization toolkit in TensorFlow: a suite of techniques that developers, both novice and advanced, can use to optimize machine learning models for deployment and execution.
While we expect that these techniques will be useful for optimizing any TensorFlow model for deployment, they are particularly important for TensorFlow Lite developers who are serving models on devices with tight memory, power constraints, and storage limitations. If you haven’t tried out TensorFlow Lite yet, you can find out more about it here.
 |
| Optimize models to reduce size, latency and power for negligible loss in accuracy |
The first technique that we are adding support for is post-training quantization to the TensorFlow Lite conversion tool. This can result in up to 4x compression and up to 3x faster execution for relevant machine learning models.
By quantizing their models, developers will also gain the additional benefit of reduced power consumption. This can be useful for deployment in edge devices, beyond mobile phones.
Enabling post-training quantization
The post-training quantization technique is integrated into the TensorFlow Lite conversion tool. Getting started is easy: after building their TensorFlow model, developers can simply enable the ‘post_training_quantize’ flag in the TensorFlow Lite conversion tool. Assuming that the saved model is stored in saved_model_dir, the quantized tflite flatbuffer can be generated:
converter=tf.contrib.lite.TocoConverter.from_saved_model(saved_model_dir)
converter.post_training_quantize=True
tflite_quantized_model=converter.convert()
open(“quantized_model.tflite”, “wb”).write(tflite_quantized_model)
Our
tutorial walks you through how to do this in depth. In the future, we aim to incorporate this technique into general TensorFlow tooling as well, so that it can be used for deployment on platforms not currently supported by TensorFlow Lite.
Benefits of post-training quantization
- 4x reduction in model sizes
- Models, which consist primarily of convolutional layers, get 10–50% faster execution
- RNN-based models get up to 3x speed-up
- Due to reduced memory and computation requirements, we expect that most models will also have lower power consumption
See graphs below for model size reduction and execution time speed-ups for a few models (measurements done on Android Pixel 2 phone using a single core).
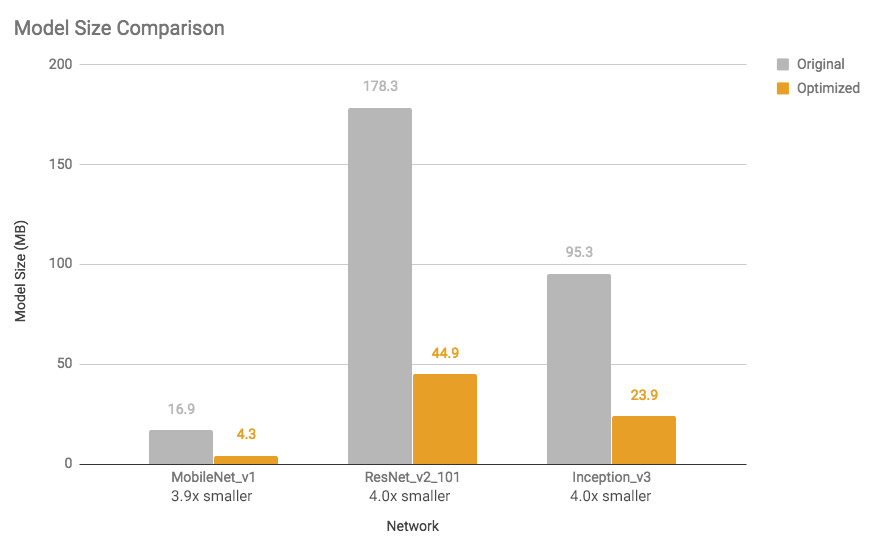 |
| Figure 1: Model Size Comparison: Optimized models are almost 4x smaller |
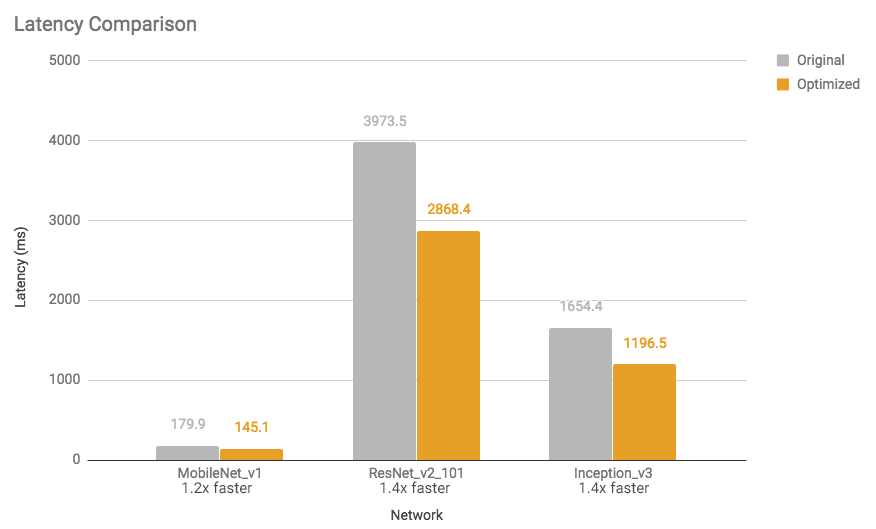 |
| Figure 2: Latency Comparison: Optimized models are 1.2 to 1.4x faster |
These speed-ups and model size reductions occur with little impact to accuracy. In general, models that are already small for the task at hand (for example, mobilenet v1 for image classification) may experience more accuracy loss. For many of these models we provide
pre-trained fully-quantized models.
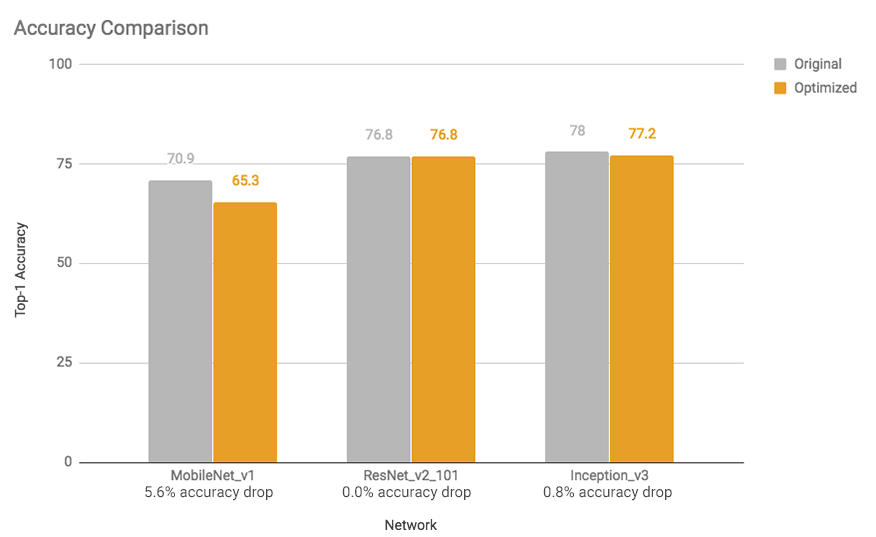
We expect to continue improving our results in the future, so please see the
model optimization guide for the latest measurements.
How post-training quantization works
Under the hood, we are running optimizations (otherwise referred to as quantization) by lowering the precision of the parameters (i.e. neural network weights) from their training-time 32-bit floating-point representations into much smaller and efficient 8-bit integer ones. See the
post-training quantization guide for more details.
These optimizations will make sure to pair the reduced-precision operation definitions in the resulting model with kernel implementations that use a mix of fixed- and floating-point math. This will execute the heaviest computations fast in lower precision, but the most sensitive ones with higher precision, thus typically resulting in little to no final accuracy losses for the task, yet a significant speed-up over pure floating-point execution. For operations where there isn’t a matching “hybrid” kernel, or where the Toolkit deems it necessary, it will reconvert the parameters to the higher floating point precision for execution. Please see the
post-training quantization page for a list of supported hybrid operations.
Future work
We will continue to improve post-training quantization as well as work on other techniques which make it easier to optimize models. These will be integrated into relevant TensorFlow workflows to make them easy to use.
Post-training quantization is the first offering under the umbrella of the optimization toolkit that we are developing. We look forward to getting developer feedback on it.
Please file issues at
GitHub and ask questions at
Stack Overflow.
Acknowledgements
We would like to acknowledge core contributions from Raghu Krishnamoorthi, Raziel Alvrarez, Suharsh Sivakumar, Yunlu Li, Alan Chiao, Pete Warden, Shashi Shekhar, Sarah Sirajuddin and Tim Davis. Mark Daoust helped create the colab tutorial. Billy Lamberta and Lawrence Chan helped with the creation of the website.






