https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEgA97JpZpO2Euak4jUDxUzFmnUa_yCV09uT611Rj4MQ0plGNPQB0pixnWrsvu3qeF-rZCRwDHuW2QSHEojYmmr4DmS6AIAjTGbz00ECDJR_thboAOvoXvgpFlNNnGbP-XSNQG-jeucY5Xs/s1600/0_Bz70Bl42gW3PFnCV.gif
Posted by the TensorFlow team
Running inference on compute-heavy machine learning models on mobile devices is resource demanding due to the devices’ limited processing and power. While converting to a fixed-point model is one avenue to acceleration, our users have asked us for GPU support as an option to speed up the inference of the original floating point models without the extra complexity and potential accuracy loss of quantization.
We listened and we are excited to announce that you will now be able to leverage mobile GPUs for select models (listed below) with the release of developer preview of the GPU backend for
TensorFlow Lite; it will fall back to CPU inference for parts of a model that are unsupported. In the coming months, we will continue to add additional ops and improve the overall GPU backend offering.
This new backend leverages:
Today, we are releasing a precompiled binary preview of the new GPU backend, allowing developers and machine learning researchers an early chance to try this exciting new technology. A full open-source release is planned in later 2019, incorporating the feedback we collect from your experiences.
 |
| Face Contour detection (not facial recognition) using TensorFlow Lite CPU floating point inference today. By leveraging the new GPU backend in the future, inference can be sped up from ~4x on Pixel 3 and Samsung S9 to ~6x on iPhone7. |
GPU vs CPU Performance
At Google, we have been using the new GPU backend for several months in our products, accelerating compute intensive networks that enable vital use cases for our users.
For Portrait mode on Pixel 3, Tensorflow Lite GPU inference accelerates the
foreground-background segmentation model by
over 4x and the
new depth estimation model by
over 10x vs. CPU inference with floating point precision. In
YouTube Stories and
Playground Stickers our
real-time video segmentation model is sped up by 5–10x across a variety of phones.
We found that in general the new GPU backend
performs 2–7x faster than the floating point CPU implementation for a wide range of diverse deep neural network models. Below, we benchmarked 4 public and 2 internal models covering common use cases developers and researchers encounter across a set of Android and Apple devices:
Public models:
- MobileNet v1 (224x224) image classification [download]
(image classification model designed for mobile and embedded based vision applications)
- PoseNet for pose estimation [download]
(vision model that estimates the poses of a person(s) in image or video)
- DeepLab segmentation (257x257) [download]
(image segmentation model that assigns semantic labels (e.g., dog, cat, car) to every pixel in the input image)
- MobileNet SSD object detection [download]
(image classification model that detects multiple objects with bounding boxes)
Google proprietary use cases:
- Face contours as used by MLKit
- Realtime Video Segmentation as used by Playground Stickers and YouTube Stories
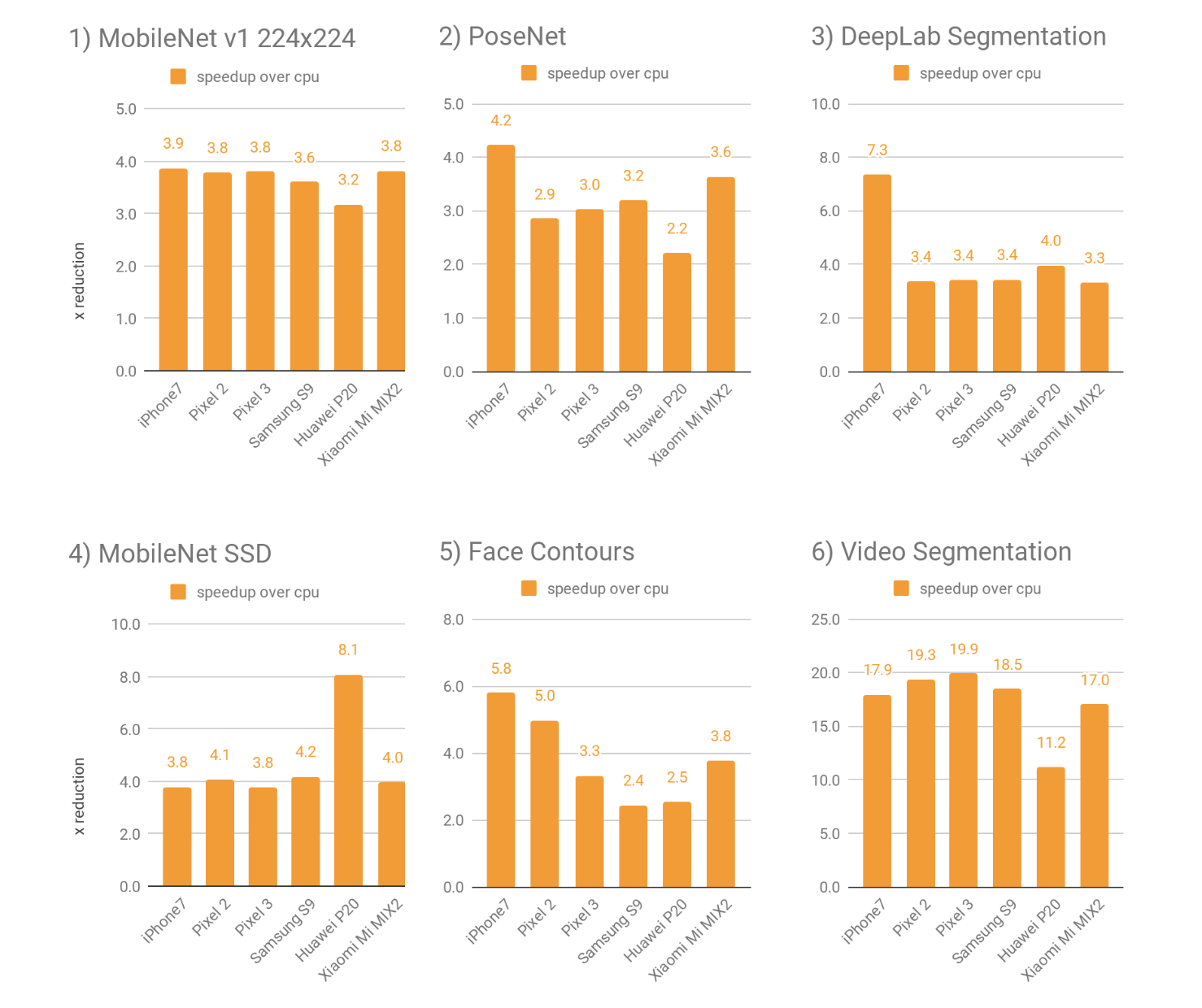 |
| Table 1. Average performance speedups on GPU compared to baseline CPU performance on 6 models across various Android and Apple devices. Higher multiplier is better. |
The GPU speedup is most significant on more complex neural network models that lend themselves better to GPU utilization, such as dense prediction/segmentation or classification tasks. On very small models the speedup might be smaller and the use of the CPU instead could have the benefit to avoid latency costs inherent in memory transfers.
How Can I Use It?
Tutorials
The easiest way to get started is to follow our tutorial on using the TensorFlow Lite demo apps with the GPU delegate. A brief summary of the usage is presented below as well. For even more information see our full documentation.
For a step-by-step tutorial, watch the GPU Delegate videos:
Using Java for Android
We have prepared a complete Android Archive (AAR) that includes TensorFlow Lite with the GPU backend. Edit your gradle file to include this AAR instead of the current release and add this snippet to your Java initialization code.
// Initialize interpreter with GPU delegate.
GpuDelegate delegate = new GpuDelegate();
Interpreter.Options options = (new Interpreter.Options()).addDelegate(delegate);
Interpreter interpreter = new Interpreter(model, options);
// Run inference.
while (true) {
writeToInputTensor(inputTensor);
interpreter.run(inputTensor, outputTensor);
readFromOutputTensor(outputTensor);
}
// Clean up.
delegate.close();
Using C++ for iOS
Step 1. Download the binary release of TensorFlow Lite.
Step 2. Change your code so that it calls
ModifyGraphWithDelegate() after creating your model.
// Initialize interpreter with GPU delegate.
std::unique_ptr interpreter;
InterpreterBuilder(model, op_resolver)(&interpreter);
auto* delegate = NewGpuDelegate(nullptr); // default config
if (interpreter->ModifyGraphWithDelegate(delegate) != kTfLiteOk) return false;
// Run inference.
while (true) {
WriteToInputTensor(interpreter->typed_input_tensor(0));
if (interpreter->Invoke() != kTfLiteOk) return false;
ReadFromOutputTensor(interpreter->typed_output_tensor(0));
}
// Clean up.
interpreter = nullptr;
DeleteGpuDelegate(delegate);
What Is Accelerated Right Now?
The GPU backend currently supports select operations (see
documentation). Your model will run fastest when containing only these operations; unsupported GPU operations will automatically fall back to CPU.
How Does It Work?
Deep neural nets run hundreds of operations in sequence, making them a great fit for GPUs, which are designed with throughput-oriented parallel workloads in mind.
The GPU delegate is initialized when
Interpreter::ModifyGraphWithDelegate() is called in Objective-C++ or indirectly by calling
Interpreter’s constructor with
Interpreter.Options in Java. In this initialization phase, a canonical representation of the input neural network is built based on the execution plan received from the framework. With this new representation, a set of transformation rules are applied. These include, but are not limited to:
- Culling of unneeded ops
- Substitution of ops with other equivalent ops that have better performance
- Merging of ops to reduce the final number of shader programs generated
Based on this optimized graph, compute shaders are generated and compiled; we currently use OpenGL ES 3.1 Compute Shaders on Android and Metal Compute Shaders on iOS. When creating these compute shaders, we also employ various architecture-specific optimizations such as:
- Applying specializations of certain ops instead of their (slower) generic implementations
- Relaxing register pressure
- Picking optimal workgroup sizes
- Safely trimming accuracy
- Reordering explicit math operations
At the end of these optimizations, the shader programs are compiled which can take a few milliseconds up to half a second, just like mobile games. Once the shader programs are compiled, the new GPU inference engine is ready for action.
Upon inference for each input:
- Inputs are moved to the GPU if necessary: The input tensors, if not already stored as GPU memory, are made accessible to the GPU by the framework by creating GL buffers/textures or MTLBuffers while also potentially copying data. As GPUs are most efficient with 4-channel data structures, tensors with channel sizes not equal to 4 are reshaped to a more GPU-friendly layout.
- Shader programs are executed: The aforementioned shader programs are inserted into the command buffer queue and the GPU carries these out. During this step, we also manage GPU memory for intermediate tensors to keep the memory footprint of our backend as small as possible.
- Outputs moved to CPU if necessary: Once the deep neural network has finished processing, the framework copies the result from GPU memory to CPU memory unless the output of the network can be directly rendered on screen and this transfer is not needed.
For the best experience, we recommend optimizing the input/output tensor copy and/or the network architecture. Details on such optimizations can be found at
TensorFlow Lite GPU documentation. For performance best practices, please read this
guide.
How Big Is It?
The GPU delegate will add about 270KB to an Android armeabi-v7a APK and 212KB to iOS per included architecture. However, the backend is optional, and so if you are not using the GPU delegate, you need not include it.
Future Work
This is just the beginning of our GPU support efforts. Along with community feedback, we intend to add the following improvements:
- Expand coverage of operations
- Further optimize performance
- Evolve and finalize the APIs
We encourage you to leave your thoughts and comments on our
GitHub and
StackOverflow pages.
Acknowledgements
Andrei Kulik, Juhyun Lee, Nikolay Chirkov, Ekaterina Ignasheva, Raman Sarokin, Yury Pisarchyk, Matthias Grundmann, Andrew Selle, Yu-Cheng Ling, Jared Duke, Lawrence Chan, Tim Davis, Pete Warden, Sarah Sirajuddin






