https://blog.tensorflow.org/2019/01/what-are-symbolic-and-imperative-apis.html?hl=th
https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEjUWHnA_7lacHU7_YN1pyossotQN6g0udFkz7Y8qrFrpI9aTmrikKwiH6m0zLR4cawYIuvkClpO6uIlAJyCHiEGwYVx0vogaXbda9SyKXtgh5c7FbNELTzjwcLBPFFOthhYCwEk1Hv5P8Q/s1600/mentalmodel.png
Posted by Josh Gordon
One of my favorite things about TensorFlow 2.0 is that it offers multiple levels of abstraction, so you can choose the right one for your project. In this article, I’ll explain the tradeoffs between two styles you can use to create your neural networks. The first is a symbolic style, in which you build a model by manipulating a graph of layers. The second is an imperative style, in which you build a model by extending a class. I’ll introduce these, share notes on important design and usability considerations, and close with quick recommendations to help you choose the right one.
Symbolic (or Declarative) APIs
The mental model we normally use when we think of a neural network is a “graph of layers”, illustrated in the image below.
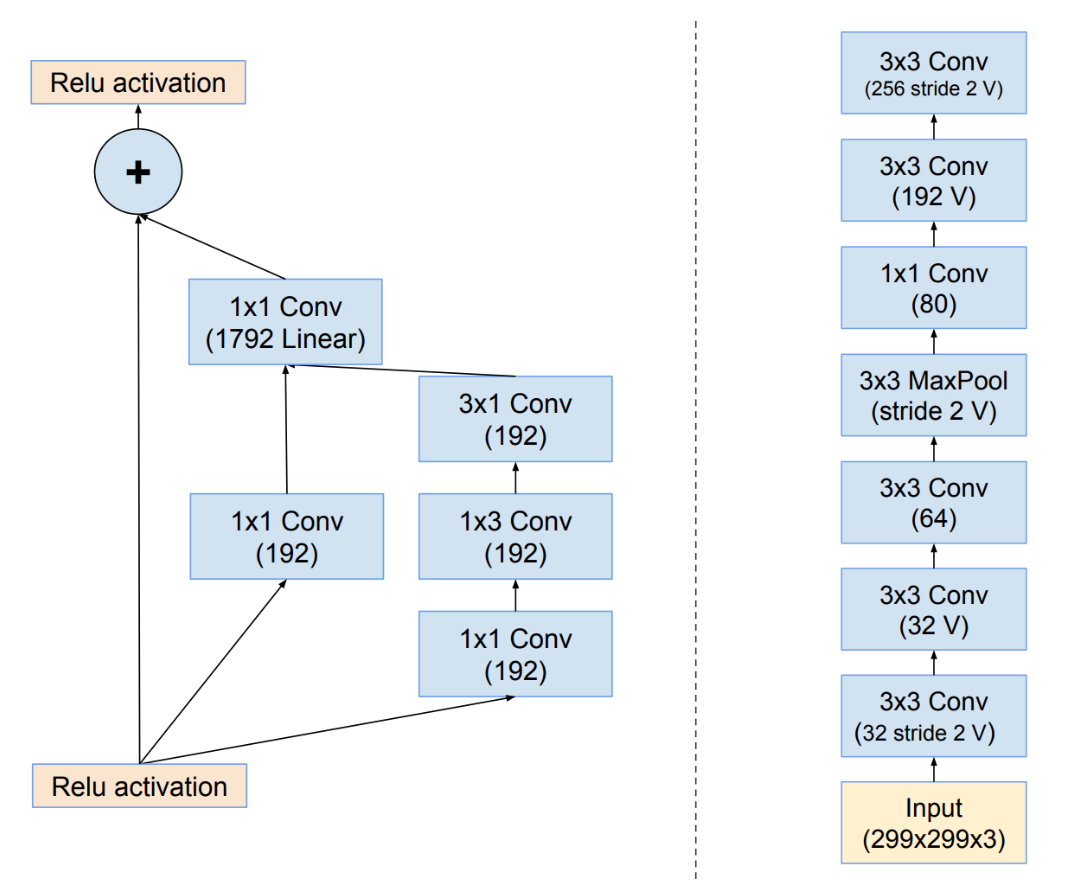 |
| The mental model we normally use when we think of neural networks is a graph of layers (images are schemas for Inception-ResNet). |
This graph can be a DAG, shown on the left, or a stack, shown on the right. When we build models symbolically, we do so by describing the structure of this graph.
If that sounds technical, it may surprise you to learn you have experience doing so already, if you’ve used Keras. Here’s a quick example of building a model symbolically, using the
Keras Sequential API.
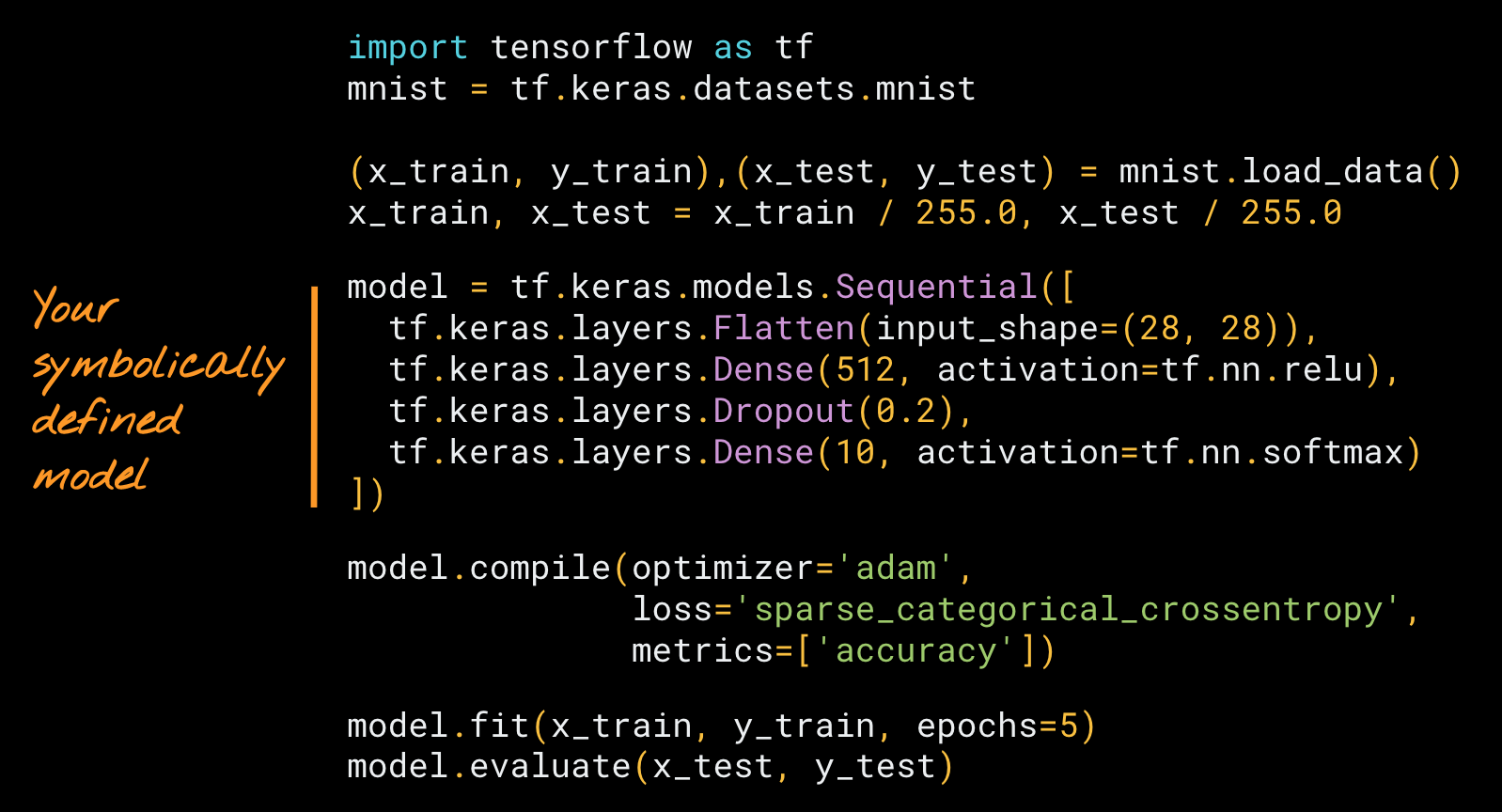 |
| A neural network built symbolically using the Keras Sequential API. You can run this example here. |
In the above example, we’ve defined a stack of layers, then trained it using a built-in training loop,
model.fit.
Building a model with Keras can feel as easy as “plugging LEGO bricks together.” Why? In addition to matching our mental model, for technical reasons covered later, models built this way easy to debug by virtue of thoughtful error messages provided by the framework.
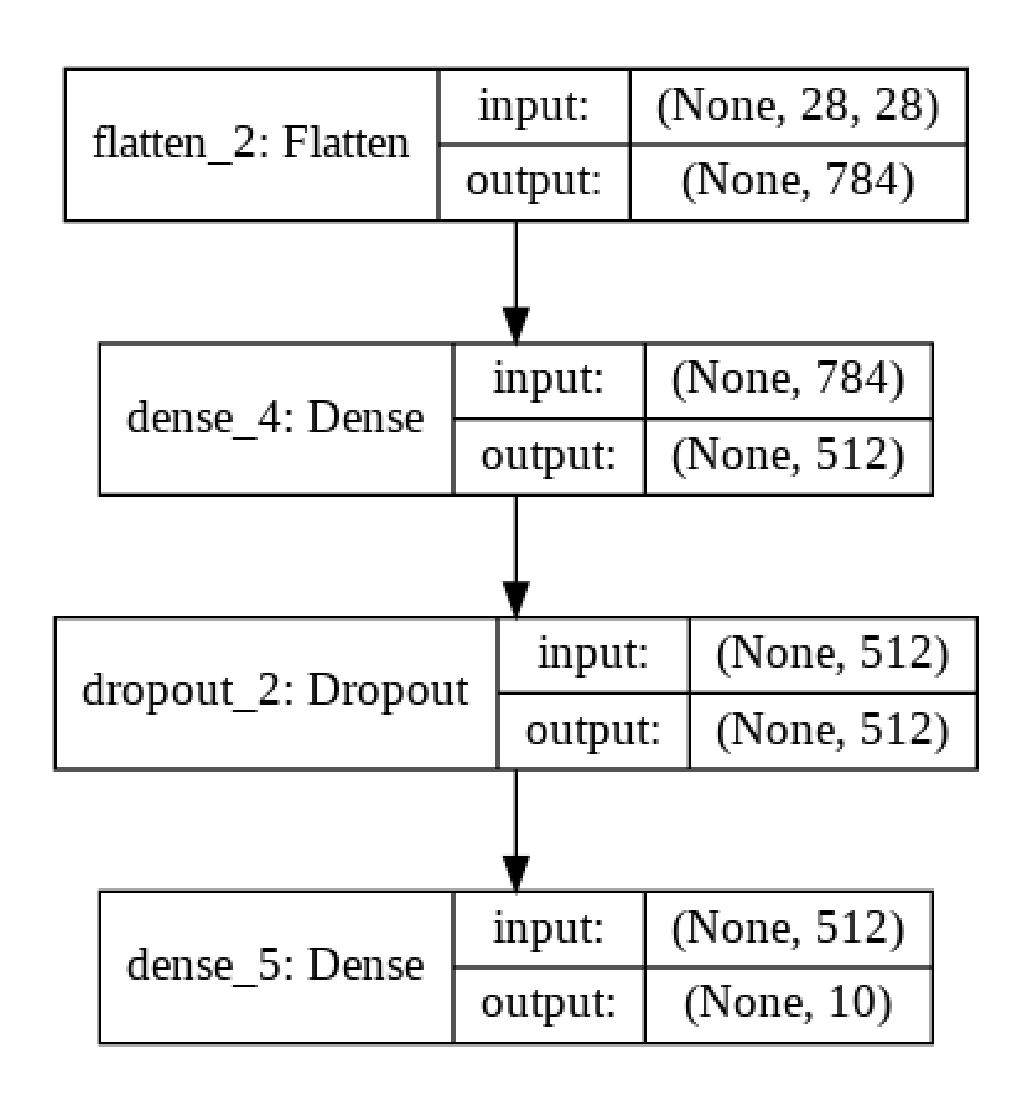 |
| A graph that shows the model created by the code above (built with plot_model, there’s a code snippet you can reuse in the next example in this post). |
TensorFlow 2.0 provides another symbolic model-building APIs: Keras Functional. Sequential is for stacks, and as you’ve probably guessed, Functional is for DAGs.
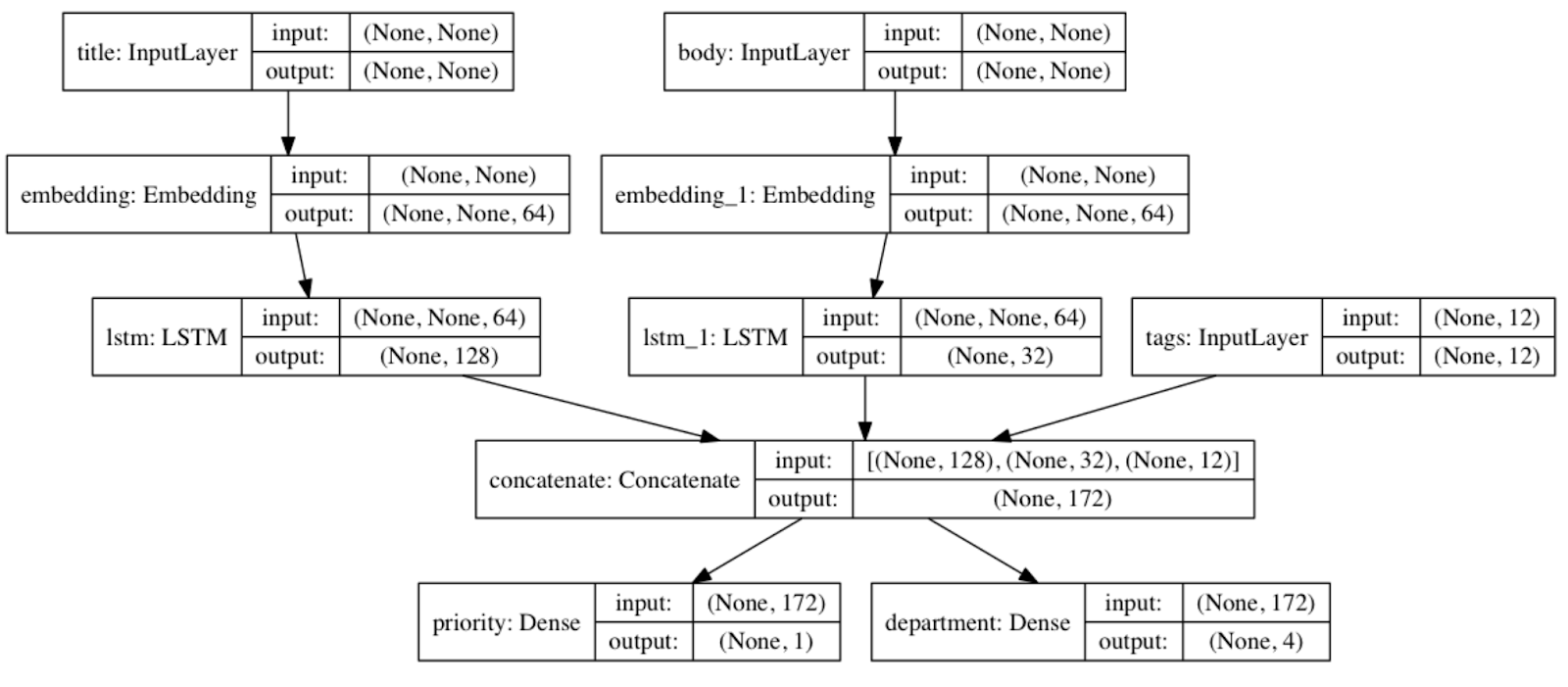 |
| A quick example of using the Functional API to create a multiple inputs / multiple outputs model. |
The Functional API is a way to create more flexible models. It can handle non-linear topology, models with shared layers, and models with multiple inputs or outputs. Basically, the Functional API is a set of tools for building these graphs of layers. We’re working a couple new tutorials in this style for you now.
There are other symbolic APIs you may have experience with. For example, TensorFlow v1 (and Theano) provided a much lower level API. You’d build models by creating a graph of ops, which you compile and execute. At times, using this API could feel like you were interacting with a compiler directly. And for many (including the author) it was difficult to work with.
By contrast, in Keras the level of abstraction matches our mental model: a graph of layers, plugged together like Lego bricks. This feels natural to work with, and it’s one of the model-building approaches we’re standardizing on in TensorFlow 2.0. There’s another one I’ll describe now (and there’s a good chance you’ve used this too, or will have a chance to give it a try soon).
Imperative (or Model Subclassing) APIs
In an imperative style, you write your model like your write NumPy. Building models in this style feels like Object-Oriented Python development. Here’s a quick example of a subclassed model:
From a developer perspective, the way this works is you extend a Model class defined by the framework, instantiate your layers, then write the forward pass of your model imperatively (the backward pass is generated automatically).
TensorFlow 2.0 supports this out of the box with Keras
Subclassing API. Along with the Sequential and Functional APIs, it’s one of the recommended ways you develop models in TensorFlow 2.0.
Although this style is new for TensorFlow, it may surprise you to learn that it was introduced by
Chainer in 2015 (time flies!). Since then, many frameworks have adopted a similar approach, including Gluon, PyTorch, and TensorFlow (with Keras Subclassing). Surprisingly, code written in this style in different frameworks can appear so similar, it may be difficult to tell
apart!
This style gives you great flexibility, but it comes with a usability and maintenance cost that’s not obvious. More on that in a bit.
Training loops
Models defined in either the Sequential, Functional, or Subclassing style can be trained in two ways. You can use either a built-in training routine and loss function (see the first example, where we use
model.fit and
model.compile), or if you need the added complexity of a custom training loop (for example, if you’d like to write your own gradient clipping code) or loss function, you can do so easily as follows:
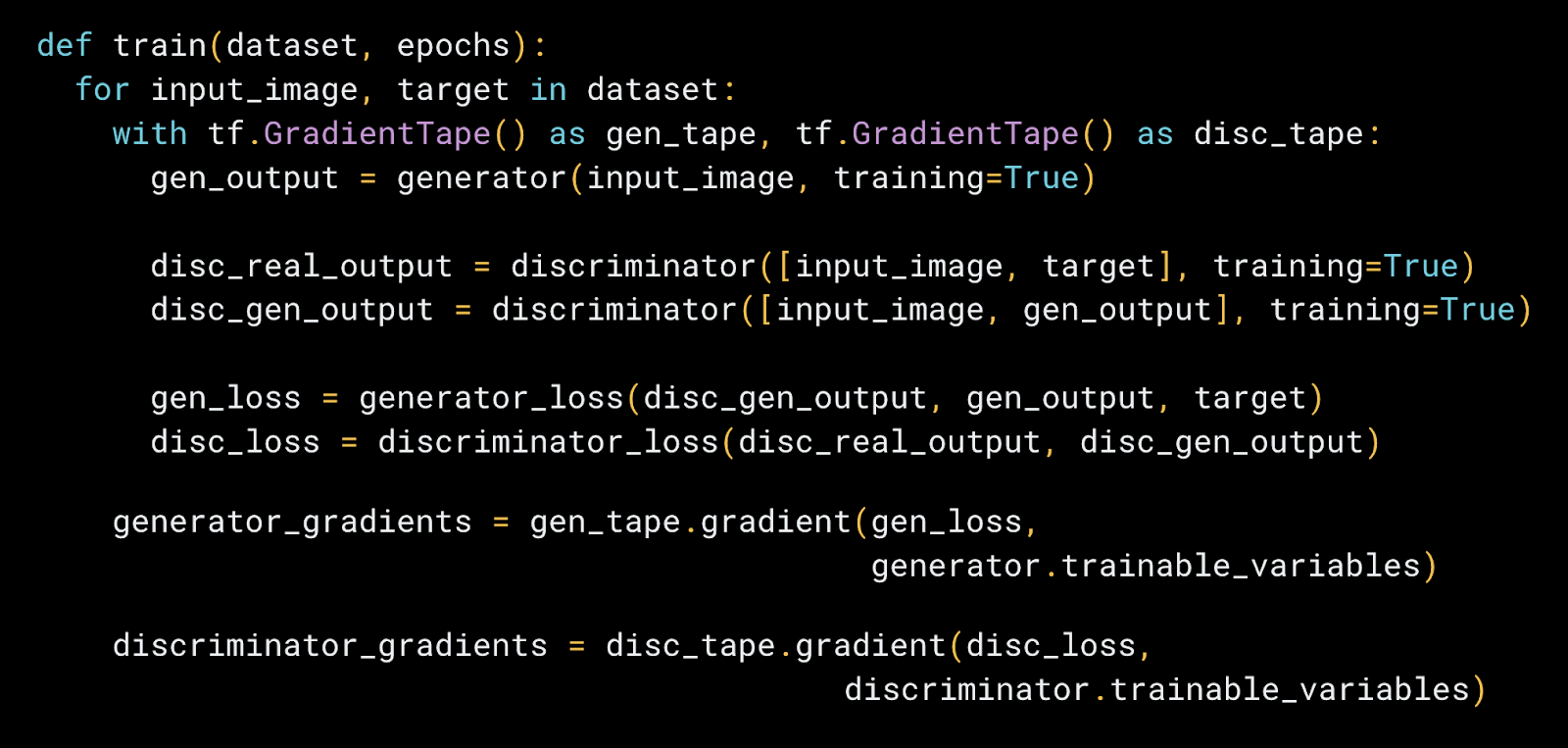 |
| An example of a custom training loop and loss function for Pix2Pix. |
Having both these approaches available is important, and can be handy to reduce code complexity and maintenance costs. Basically, you can use additional complexity when it’s helpful, and when it’s unnecessary — use the built-in methods and spend your time on your research or project.
Now that we have a sense for symbolic and imperative styles, let’s look at the tradeoffs.
Benefits and Limitations of Symbolic APIs
Benefits
With Symbolic APIs your model is a graph-like data structure. This means your model can be inspected, or summarized.
- You can plot it as an image to display the graph (using
keras.utils.plot_model) , or simply use model.summary() or to see a description of the layers, weights, and shapes.
Likewise, when plugging together layers, library designers can run extensive layer compatibility checks (while building the model, and before execution).
- This is similar to type-checking in a compiler, and can greatly reduce developer errors.
- Most debugging will happen during the model definition phase, not during execution. You have the guarantee that any model that compiles, will run. This enables faster iteration, and easier debugging.
Symbolic models provide a consistent API. This makes them simple to reuse and share. For example, in transfer learning you can access intermediate layer activations to build new models from existing ones, like this:
from tensorflow.keras.applications.vgg19 import VGG19
base = VGG19(weights=’imagenet’)
model = Model(inputs=base.input,
outputs=base_model.get_layer(‘block4_pool’).output)
image = load(‘elephant.png’)
block4_pool_features = model.predict(image)
Symbolic models are defined by a data structure that makes them natural to copy or clone.
- For example, the Sequential and Functional APIs give you
model.get_config(), model.to_json(), model.save(), clone_model(model), with the ability to recreate the same model from just the data structure (without access to the original code used to define and train the model).
While a well-designed API should match our mental model for neural networks, it’s equally important to match the mental model we have as programmers. For many of us, that’s an imperative programming style. In a symbolic API you’re manipulating “symbolic tensors” (these are tensors that don’t yet hold any values) to build your graph. The Keras Sequential and Functional API “feel” imperative. They’re designed such that many developers don’t realize they’ve been defining models symbolically.
Limitations
The current generation of symbolic APIs are best suited to developing models that are directed acyclic graphs of layers. This accounts for the majority of use-cases in practice, though there are a few special ones that don’t fit into this neat abstraction, for example, dynamic networks like tree-RNNs, and recursive networks.
That’s why TensorFlow also provides an imperative model-building API style (Keras Subclassing, shown above). You get to use all the familiar layers, initializers, and optimizers from the Sequential and Functional APIs. The two styles are fully interoperable as well, so you can mix and match (for example, you can nest one model type in another). You take a symbolic model and use it as a layer in a subclassed model, or the reverse.
Benefits and Limitations of Imperative APIs
Benefits
Your forward pass is written imperatively, making it easy to swap out parts implemented by the library (say, a layer, activation, or loss function) with your own implementation. This feels natural to program, and is a great way to dive deeper into the nuts and bolts of deep learning.
- This makes it easy to try new ideas quickly (the DL development workflow becomes identical to object-oriented Python), and is especially helpful for researchers.
- It’s also easy to specify arbitrary control flow within the forward pass of your model, using Python.
Imperative APIs gives you maximum flexibility, but at a cost. I love writing code in this style as well, but want to take a moment to highlight the limitations (it’s good to be aware of the tradeoffs).
Limitations
Importantly, when using an imperative API, your model is defined by the body of a class method. Your model is no longer a transparent data structure, it is an opaque piece of bytecode. When using this style, you’re trading usability and reusability to gain flexibility.
Debugging happens during execution, as opposed to when you’re defining your model.
- There are almost no checks run on inputs or inter-layer compatibility, so a lot of the debugging burden moves from the framework to the developer when using this style.
Imperative models can be more difficult to reuse. For example, you cannot access intermediate layers or activations with a consistent API.
- Instead, the way to extract activations is to write a new class with a new call (or forward) method. This can be fun to write initially, and simple to do, but can be a recipe for tech debt without standards.
Imperative models are also more difficult to inspect, copy, or clone.
- For example,
model.save(), model.get_config(), and clone_model do not work for subclassed models. Likewise, model.summary() only gives you a list of layers (and doesn’t provide information on how they’re connected, since that’s not accessible).
Technical debt in ML systems
It’s important to remember model-building is only a tiny fraction of working with machine learning in practice. Here’s one of my favorite illustrations on the topic. The model itself (the part of the code where you specify your layers, training loop, etc.) is the tiny box in the middle.
Symbolically defined models have advantages in reusability, debugging, and testing. For example, when teaching — I can immediately debug a student’s code if they’re using the Sequential API. When they’re using a subclassed model (regardless of framework), it takes longer (bugs can be more subtle, and of many types).
Closing thoughts
TensorFlow 2.0 supports both of these styles out of the box, so you can choose the right level of abstraction (and complexity) for your project.
- If your goal is ease of use, low conceptual overhead, and you like to think about your models as graphs of layers: use the Keras Sequential or Functional API (like plugging together LEGO bricks) and the built-in training loop. This is the right way to go for most problems.
- If you like to think about your models as an object-oriented Python/Numpy developer, and you prioritize flexibility and hackability, Keras Subclassing is the right API for you.
I hope this was a helpful overview, and thanks for reading! To learn more about the TensorFlow 2.0 stack, beyond these model building APIs, check out
this article. To learn more about the relationship between TensorFlow and Keras, head
here.








