https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEg25vPFZpB8Ft58BZNTbqt-9CSrL0mEhHeXVFB_VEqJOf9E90PSV54Jmp61RehNkZdKtCAnuFodx2T4k5kn_1SNjwvPpRV15K_Kr35JZ71Eqd4o_Ny9kbV-acdlDPjqq_Aq1OAZnBbwF70/s1600/data.png
A guest article by Anton Dmitriev, software engineer at GridGain Systems.
Any deep learning starts with data. It’s a key point. Without data we can’t train a model, can’t estimate model quality and can’t make predictions. Therefore the datasource is very important. Doing research, inventing new neural network architectures and making experiments we get used to using the simplest local datasource, usually files in different formats. This approach is very efficient for sure. But at some point, we need to get closer to a production environment. It becomes very important to simplify and speed up production data feeding and be able to work with big data. And at this moment, Apache Ignite comes into play.
Apache Ignite is a memory-centric distributed database, caching, and processing platform for transactional, analytical, and streaming workloads, delivering in-memory speeds at petabyte scale. The existing integration between Apache Ignite and TensorFlow allows you to use Apache Ignite as a datasource for neural network training and inference andas a checkpoint storage and cluster manager for distributed training.
Distributed In-Memory Datasource
Apache Ignite is a memory-centric distributed database that provides fast data access. It allows you to avoid hard drive limitations, storing and operating with as much data as you need in a distributed cluster. You can utilize these benefits of Apache Ignite by using Ignite Dataset.
Note that Apache Ignite is not just a step of ETL pipeline between a database or a data warehouse and TensorFlow. Apache Ignite is an
HTAP (hybrid transactional/analytical processing) system. By choosing Apache Ignite and TensorFlow, you are getting a single system for transactional and analytical processing and, at the same time, an ability to use your operational and historical data for neural network training and inference.
The following benchmark results demonstrate that Apache Ignite is well-suited for a single node data storage use case. It allows you to achieve more than 850 MB/s throughput if storage and client are placed on the same node. If storage is on a remote node in regards to client the throughput is about 800 MB/s.
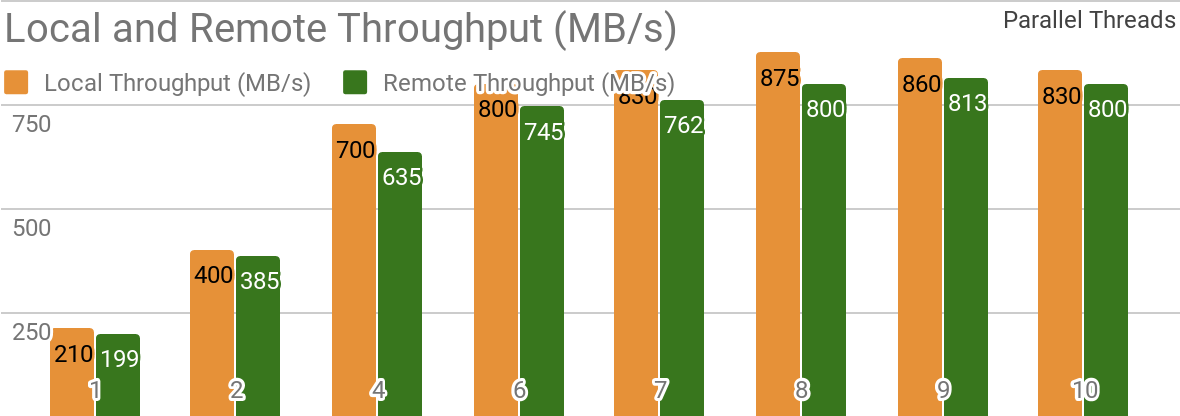 |
| Ignite Dataset throughput in case of one local Apache Ignite Node. This benchmark was prepared on 2x Xeon E5–2609 v4 1.7GHz with 16Gb memory and 10 Gb/s network (1MB rows and 20MB page size). |
Another benchmark demonstrates how the Ignite Dataset works with distributed Apache Ignite cluster. This is the default use case for Apache Ignite as an HTAP system and it allows you to achieve more than 1 GB/s reading throughput on 10 Gb/s network cluster for a single client.
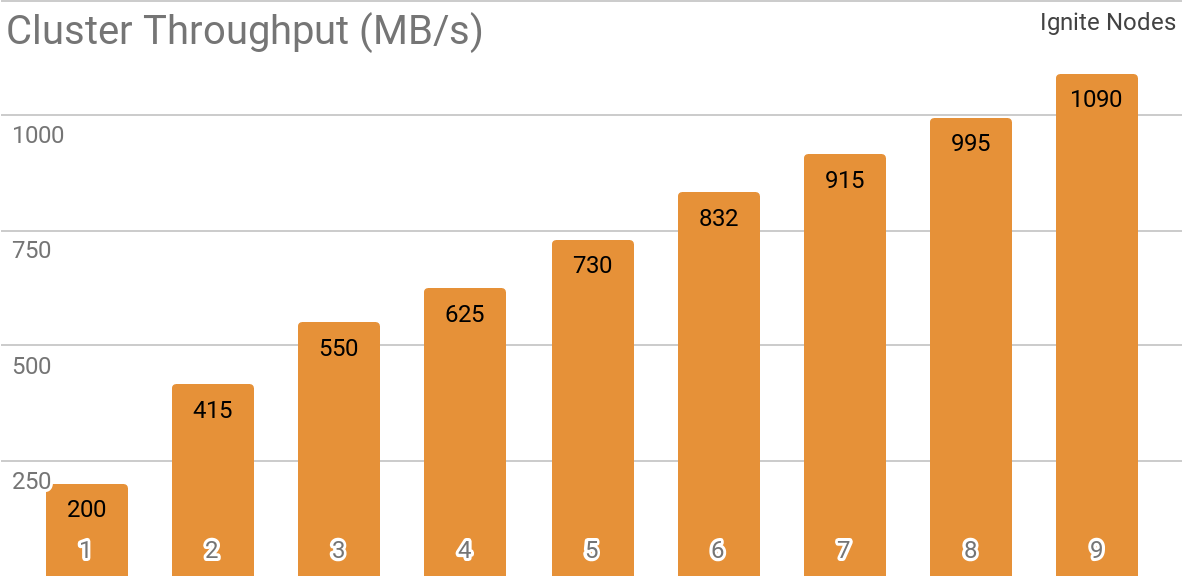 |
| Ignite Dataset throughput in case of distributed Apache Ignite cluster with various number of nodes (from 1 to 9). This benchmark was prepared on 2x Xeon E5–2609 v4 1.7GHz with 16Gb memory and 10Gb/s network (1MB rows and 20MB page size). |
Tested use case is following: Apache Ignite cache (with various number of partitions in the first set of tests and with 2048 partitions in the second one) is filled with 10K rows of 1MB each and after that TensorFlow client reads all data using Ignite Dataset. All nodes are represented by 2x Xeon E5–2609 v4 1.7GHz with 16Gb memory and connected by 10Gb/s network. Each node runs Apache Ignite with default
configuration.
It’s easy to use Apache Ignite as a classical database with SQL interface and as a TensorFlow datasource at the same time.
apache-ignite/bin/ignite.sh
apache-ignite/bin/sqlline.sh -u "jdbc:ignite:thin://localhost:10800/"
CREATE TABLE KITTEN_CACHE (ID LONG PRIMARY KEY, NAME VARCHAR);
INSERT INTO KITTEN_CACHE VALUES (1, 'WARM KITTY');
INSERT INTO KITTEN_CACHE VALUES (2, 'SOFT KITTY');
INSERT INTO KITTEN_CACHE VALUES (3, 'LITTLE BALL OF FUR');
import tensorflow as tf
from tensorflow.contrib.ignite import IgniteDataset
tf.enable_eager_execution()
dataset = IgniteDataset(cache_name="SQL_PUBLIC_KITTEN_CACHE")
for element in dataset:
print(element)
{'key': 1, 'val': {'NAME': b'WARM KITTY'}}
{'key': 2, 'val': {'NAME': b'SOFT KITTY'}}
{'key': 3, 'val': {'NAME': b'LITTLE BALL OF FUR'}}
Structured Objects
Apache Ignite allows you to store any type of objects. These objects can have any hierarchy. Ignite Dataset provides an ability to work with such objects.
import tensorflow as tf
from tensorflow.contrib.ignite import IgniteDataset
tf.enable_eager_execution()
dataset = IgniteDataset(cache_name="IMAGES")
for element in dataset.take(1):
print(element)
{
'key': 'kitten.png',
'val': {
'metadata': {
'file_name': b'kitten.png',
'label': b'little ball of fur',
width: 800,
height: 600
},
'pixels': [0, 0, 0, 0, ..., 0]
}
}
Neural network training and other computations require transformations that can be done as part of
tf.data pipeline if you use Ignite Dataset.
import tensorflow as tf
from tensorflow.contrib.ignite import IgniteDataset
tf.enable_eager_execution()
dataset = IgniteDataset(cache_name="IMAGES").map(lambda obj: obj['val']['pixels'])
for element in dataset:
print(element)
[0, 0, 0, 0, ..., 0]
Distributed Training
TensorFlow is a machine learning framework that
natively supports distributed neural network training, inference and other computations. The main idea behind the distributed neural network training is the ability to calculate gradients of loss functions (squares of the errors, for example) on every partition of data (in terms of horizontal partitioning) and then sum them to get loss function gradient of the whole dataset. Using this ability we can calculate gradients on the nodes the data is stored on, reduce them and then finally update model parameters. It allows you to avoid data transfers between nodes and thus to avoid network bottlenecks.
Apache Ignite uses horizontal partitioning to store data in a distributed cluster. When we create Apache Ignite cache (or table in terms of SQL), we can specify the number of partitions the data will be partitioned on. For example, if an Apache Ignite cluster consists of 100 machines and we create a cache with 1000 partitions, then every machine will maintain approximately 10 data partitions.
Ignite Dataset allows using these two aspects of distributed neural network training (using TensorFlow) and Apache Ignite partitioning. Ignite Dataset is a computation graph operation that can be performed on a remote worker. The remote worker can override Ignite Dataset parameters (such as
host,
port or
part) by setting correspondent environment variables for worker process (such as
IGNITE_DATASET_HOST, IGNITE_DATASET_PORT or
IGNITE_DATASET_PART). Using this overriding approach, we can assign a specific partition to every worker so that one worker handles one partition and, at the same time, transparently work with a single dataset.
import tensorflow as tf
from tensorflow.contrib.ignite import IgniteDataset
dataset = IgniteDataset("IMAGES")
# Compute gradients locally on every worker node.
gradients = []
for i in range(5):
with tf.device("/job:WORKER/task:%d" % i):
device_iterator = tf.compat.v1.data.make_one_shot_iterator(dataset)
device_next_obj = device_iterator.get_next()
gradient = compute_gradient(device_next_obj)
gradients.append(gradient)
# Aggregate them on master node.
result_gradient = tf.reduce_sum(gradients)
with tf.Session("grpc://localhost:10000") as sess:
print(sess.run(result_gradient))
Apache Ignite also allows you to run distributed training using TensorFlow high-level
Estimator API. This functionality is based on so called
standalone client mode of TensorFlow distributed training and Apache Ignite plays the role of datasource and cluster manager. The next article will be fully dedicated on this topic.
Checkpoint Storage
In addition to the database functionality, Apache Ignite provides a distributed file system called
IGFS. IGFS delivers a similar functionality to Hadoop HDFS, but only in-memory. In fact, in addition to its own APIs, IGFS implements Hadoop FileSystem API and can be transparently plugged into Hadoop or Spark deployments. TensorFlow on Apache Ignite provides an integration between IGFS and TensorFlow. The integration is based on
custom filesystem plugin from TensorFlow side and
IGFS Native API from Apache Ignite side. It has numerous use cases, for example:
- Checkpoints of state can be saved to IGFS for reliability and fault-tolerance.
- Training processes communicate with TensorBoard by writing event files to a directory, which TensorBoard watches. IGFS allows this communication to work even when TensorBoard runs in a different process or machine.
This functionality is released in TensorFlow 1.13 and will be released as part of
tensorflow/io in TensorFlow 2.0 as well.
SSL Connection
Apache Ignite allows you to protect data transfer channels by
SSL and authentication. Ignite Dataset supports both SSL connection with and without authentication. For more information, please refer to the
Apache Ignite SSL/TLS documentation.
import tensorflow as tf
from tensorflow.contrib.ignite import IgniteDataset
tf.enable_eager_execution()
dataset = IgniteDataset(cache_name="IMAGES",
certfile="client.pem",
cert_password="password",
username="ignite",
password="ignite")
Windows Support
Ignite Dataset is fully compatible with Windows. You can use it as part of TensorFlow on your Windows workstation as well as on Linux/MacOS systems.
Try it out
The following examples will help you to easily start working with this module.
Ignite Dataset
The simplest way to try Ignite Dataset is to run a
Docker container with Apache Ignite and loaded
MNIST data and after start interacting with it using Ignite Dataset. Such container is available on Docker Hub:
dmitrievanthony/ignite-with-mnist. You need to start this container on your machine:
docker run -it -p 10800:10800 dmitrievanthony/ignite-with-mnist
After that you will be able to work with it following way:

IGFS
TensorFlow support for IGFS is released in TensorFlow 1.13 and will be released as part of
tensorflow/io in TensorFlow 2.0 as well. The simplest way to try IGFS with TensorFlow is to run a
Docker container with Apache Ignite + IGFS and then interact with it using TensorFlow
tf.gfile. Such a container is available on Docker Hub:
dmitrievanthony/ignite-with-igfs. You can run the container on your machine:
docker run -it -p 10500:10500 dmitrievanthony/ignite-with-igfs
After that you will be able to work with it in the following way:
import tensorflow as tf
import tensorflow.contrib.ignite.python.ops.igfs_ops
with tf.gfile.Open("igfs:///hello.txt", mode='w') as w:
w.write("Hello, world!")
with tf.gfile.Open("igfs:///hello.txt", mode='r') as r:
print(r.read())
Hello, world!
Limitations
Presently, Ignite Dataset works with the assumption that all objects in the cache have the same structure (homogeneous objects) and the cache contains at least one object required to retrieve schema. Another limitation concerns structured objects, Ignite Dataset does not support UUID, Maps and Object arrays that might be parts of an object structure. All these limitations are subjects for further development.
Upcoming TensorFlow 2.0
Upcoming changes in TensorFlow 2.0 will lead to separation of this functionality into
tensorflow/io module. This will allow you to make usage of it more flexible. The examples will be slightly changed and our documentation and examples will reflect it.






