https://blog.tensorflow.org/2019/04/the-power-of-building-on-accelerating-platform-deep-variant.html?hl=ca
https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEhwvgsFzKuEwY4Icf7PRxrtzF3XQVdI8HPrRWffKe7BvbM7DIaYe0qZOrssAc52jTePss8_sWGRY9zX8NPX3V_do8_oOBPAE0adzlbEHmrB8jqbF-d-wC80NAHMG3otnwU9Lg8FFgtnIXM/s1600/fig1.png
The Power of Building on an Accelerating Platform: How DeepVariant Uses Intel’s AVX Optimizations
Posted by Andrew Carroll, Lizzie Dorfman
Editorial Note: This post is published with identical content on the
Google DeepVariant blog.
The
Genomics team at Google Brain develops
DeepVariant, an open-source tool for analyzing the DNA sequence of individuals. DeepVariant is built on top of
TensorFlow.
The prior release (v0.7) of DeepVariant featured a three-fold improvement in end-to-end speed and a corresponding decrease in cost relative to the previous version (v0.6). Much of this speed improvement comes by enabling DeepVariant to take advantage of new
Intel® Advanced Vector eXtensions (AVX-512) instruction set. The use of AVX-512 illustrates how latest advances in systems and platforms help accelerate and impact applied research.
xWhat are the AVX-512 Instruction Sets and TF-MKL?
Intel CPUs provide the computational execution for many individual and large-scale systems, and are used widely in
Google Cloud Platform. Processing units have a register that they can fill with data. The processing unit can apply only one type of operation to the contents of the register at a time. As a result, a vast amount of optimization goes into organizing the items that need the same operation and loading them into the register at the same time.
You can think of this like an active transit terminal, with buses constantly leaving to different destinations. The terminal must decide which buses to send in order to maximize the people on each bus without any of them waiting too long to get a ride.
The size of the register and the ability to fill it meaningfully limits the rate of processing. The AVX-512 instruction set is a specially designed way of packing this register to allow a processor to operate on more information at once. In the analogy, it corresponds to having larger buses for common destinations. See the
Intel documentation for further details.
The processes for training and applying deep learning models in TensorFlow involve a great deal of the same types of vector/matrix operations. The
Intel Math Kernel Library for Deep Neural Networks developed by Intel allows TensorFlow applications to efficiently fill these larger registers, which in turn allows Intel CPUs to compute faster for these applications.
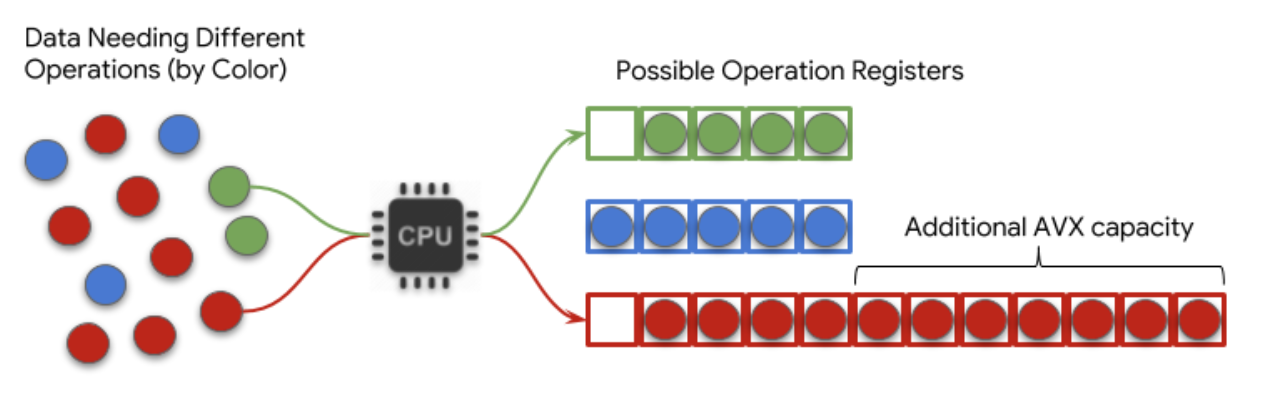 |
| Figure 1. Simplified conceptual schematic of the advantage of AVX-512 in TF-MKL |
Quantifying the Impact of TF-MKL and Intel AVX-512 for DeepVariant
DeepVariant runs three different steps in the process of calling variants in sequencing data (for more details, see
the publication or the
Google AI blog post). The most computationally intensive step is the call_variants
stage, which uses a Convolutional Neural Network to classify whether positions in an individual’s genome data differ from a reference. These results can be used clinically to diagnose and treat patients, and in research for the discovery and development of new medications.
In the prior version of DeepVariant (v0.6), the call_variants step required 11 hours and 11 minutes on a 64-core machine with an Intel Skylake CPU. For the newest release of DeepVariant (v0.7), we optimized DeepVariant’s use of TensorFlow to fully take advantage of the new TF-MKL libraries. By tapping these innovations, the runtime for call_variants when executed on the same 64-core machine is reduced to 3 hours and 25 minutes.
Because DeepVariant v0.6 already used some optimizations from the Intel libraries, we decided that to fairly quantify the acceleration from TF-MKL, we should rebuild the exact same version of DeepVariant (v0.7) with a TensorFlow library that included none of the optimizations. On the same 64-core machine, call_variants requires 14 hours and 7 minutes in this configuration.
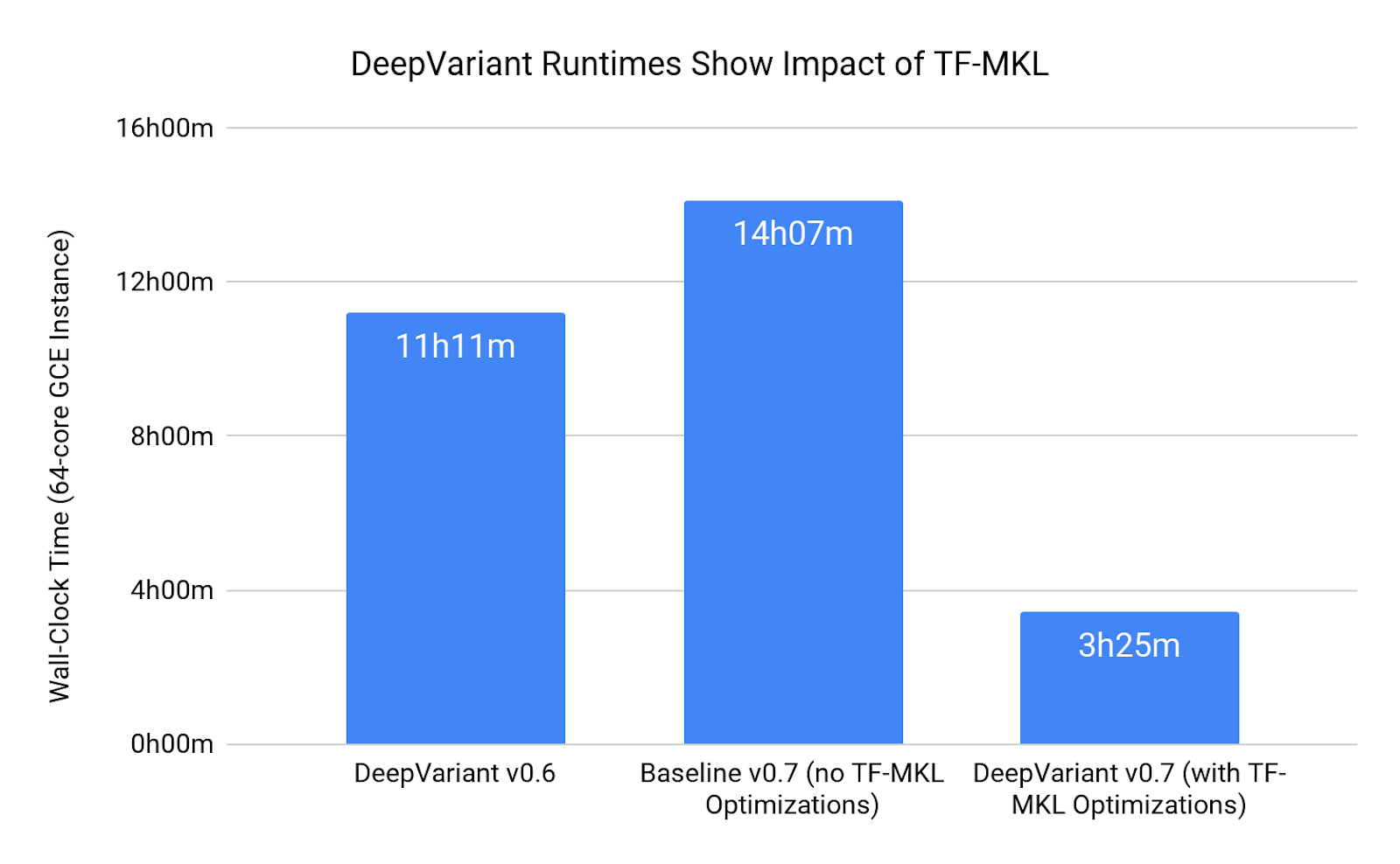 |
| Figure 2. Runtime Speedup in DeepVariant v0.7 by Using TF-MKL |
The
DeepVariant Github page provides instructions on how to use a Docker container that has all of the proper libraries pre-installed so you can run DeepVariant and take advantage of this speed improvement in your local or cloud environments.
This speed improvement, alongside other optimizations we hope to detail later, have a corresponding decrease in cost. In benchmarks on a typical coverage whole genome, DeepVariant costs $2-$3 to run on Google Cloud Platform in DeepVariant v0.7, a three-fold reduction in cost compared to DeepVariant v0.6.
The Power of Building on Rapidly Improving Platforms
This blog details how we continue our work to improve DeepVariant in speed (alongside improvements in
accuracy and
extensibility). This work is made easier by using technologies that naturally give the gift of continual improvement due to the continuing efforts of their developer and user base. The wide adoption of TensorFlow ensures that many groups within Google and outside of it are actively working to make it faster and better. Intel’s work to accelerate TensorFlow for AVX-512 is one fantastic example of that.
Furthermore, the power of AVX-512 has improved substantially with new generations of Intel CPUs. The new Intel Skylake CPUs executes DeepVariant faster than Intel Broadwell CPUs. Since we expect this trend to continue as parallelization of vector operations becomes more important, we also expect DeepVariant’s speed to naturally improve in the next generations of Intel CPUs, even beyond the speed improvement that would be seen for general applications.
This is the advantage of building on platforms undergoing rapid improvement (whether hardware, software, or the technology in between). This is why the intersection of genomics and informatics is such an exciting place to be. As our
capability to sequence genomes grows exponentially, the hardware and software to analyze these genomes must rise to meet it.






