https://blog.tensorflow.org/2019/05/auto-classification-of-naver-shopping.html?hl=vi
https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEjHxos52TtDHaPKO7bDttkTwe8NpMudFMLe48466cQ03TcqMFByRccJNjBW-Dbgb8ZC4dsLXn5gFzKwCv_cVXQOXT7gZxSgLcxpv0aoj-obcQJtkd1-Qu4U4JN3mhguX_d5MocLeJ6EDpk/s1600/mainscreen.png
A guest post by the NAVER engineering team
NAVER Shopping is a shopping portal service provided by
NAVER. NAVER Shopping matches products to categories in order to organize products systematically and allow easier searching for users. Of course, the task of matching over 20 million newly registered products a day to around 5,000 categories is impossible to do manually.
This article introduces the process of automatically matching NAVER Shopping product categories using TensorFlow, and explains how we solved a few problems arising during the process of applying machine learning to actual data used by our service.
NAVER Shopping and Product Category
NAVER Shopping is a Shopping Portal Service that provides product search, category classification, price comparison, and shopping content so that users can easily access sellers registered on NAVER Shopping, as well as the products in the
NAVER Smart Store.
 |
| The Main screen of NAVER Shopping |
The number of products registered on NAVER Shopping started with less than 100 million in 2005, exceeded 100 million in 2011, and has reached 1.5 billion as of April 2019. Currently, an average of twenty million products are newly registered every day.
NAVER Shopping organizes products systematically and classifies the products into categories, to allow easier searching for users. Categories are divided into
Upper category > Middle category > Lower category, for example
Fashion goods > Women’s shoes > Flat shoes > Loafer.
Currently, there are about 5,000 categories managed by NAVER Shopping. When a user enters a keyword to search for a product on NAVER Shopping, it identifies the category of the keyword entered, and then the products matching the keyword category are listed according to search logic. In order for users to find a product fast and get the desired search results, products should be matched to the appropriate categories.
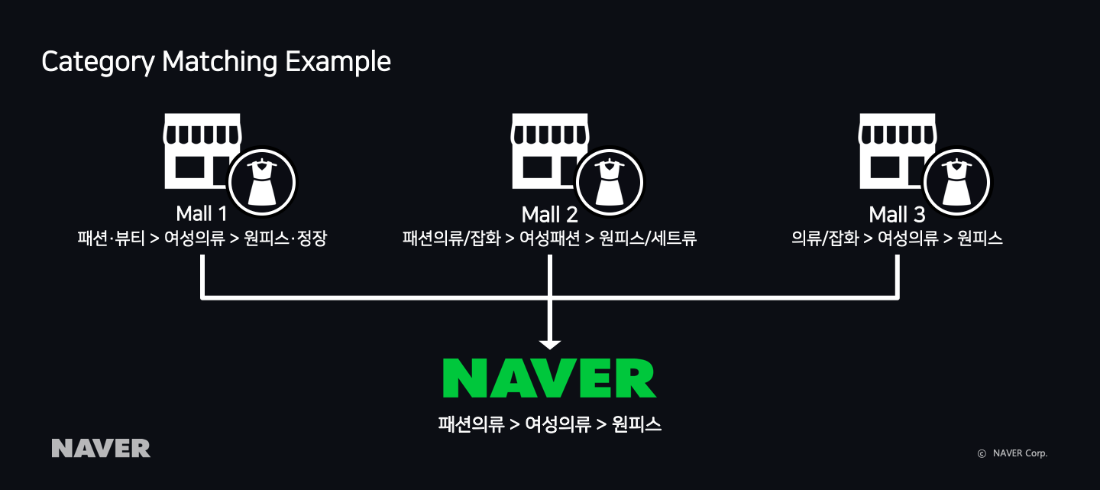 |
| An example of category matching |
Sellers registered on NAVER Shopping create the various product information in a test file, including the seller’s category information according to
EP(Engine Page) Guide, which is the data form for product registration on NAVER Shopping, and send it to NAVER Shopping.
Among the various product information sent to NAVER Shopping, the category system used by sellers can vary. So, as shown in the above category matching example, the same dress can have very different category information.
To improve shopping search quality by increasing search accuracy, it is necessary to match the category used by a seller to a category that fits NAVER Shopping. The problem is that it is not possible for a person to match new products to the 500 categories of NAVER Shopping one by one.
Although we also used rule-based category matching, such as how a seller’s “desktop HDD” category is mapped to NAVER Shopping’s “HDD” category, we are unable to use the rule-based category anymore, as the number of sellers and products increases, and as the categories in NAVER Shopping are frequently reorganized. Instead, category matching can be automated by applying technologies such as natural language processing (NLP) and computer vision.
There are few things to consider when adapting NLP for Naver Shopping service. In most cases, attributes of product (e.g. 300ml/500GB) or code names (e.g. SL-M2029, PIXMA-MX922) are classified as stop words and ignored during the process, when using off the shelf software. However, these terms are meaningful for commerce service. In order to analyze these words, NLP process should be customized to satisfy the needs of the service.
Category Auto-Matching System Architecture
Currently, NAVER Shopping uses the architecture as follows for learning and classification in the category auto-matching system.
 |
| Category Auto-Matching System Architecture |
About 1.5 billion pieces of product information in the Relational Database are provided to users as Search Results Sets. The Monitoring Center finds products matched to an incorrect category among the search results and matches them to the correct category. Since the data of a product matched by the Monitoring Center is checked by a person, it is regarded as refined data and is then extracted as learning data from the Distributed Database. In addition to refined data, learning data is extracted by considering various characteristics of the product.
Training servers train the model by reading data from the Distributed Database, and the enhanced model is distributed to the Inference Server. An Inference Server reads the information (products not yet matched to a NAVER category) of about 20 million products every day to match the categories, followed by updating to the database.
Category Auto-Matching Model
Category Auto-Matching Model of NAVER Shopping analyzes the features of the product data and train a model through the following process.
- Find Product’s feature: Find useful features from product information.
- Morphology Analysis: Analyze and extract terms from product information.
- Word Embedding: Convert product features into vector.
- CNN-LSTM Model — Product Name: Apply CNN-LSTM model to product name.
- MobileNetV2 — Product Image: Apply MobileNetV2 model to product image.
- Multi Input Model: Concatenates models by various data from the product to enhance accuracy.
Product features
The marked parts in the following picture are the features to be used in category auto-matching.
 |
| Product features used in category auto-matching. |
From the above example, the product name does not mention whether it is a t-shirt for women or a t-shirt for another category. However, as it is easy to see by looking at the image, “product name” and “image” are the elements that users look at first when purchasing a product. Product name and image should be carefully looked at by the monitoring center to move the product to the correct category when a product with incorrect category matching is found from search results.
So, the product name and image are also used as main features in category auto-matching. Not only the product name and image, but the category used by the seller, lowest price of product, brand, maker, original image proportion are also used as additional features in the dozens of pieces of product information provided by sellers.
Morphology Analysis
Product names to be used as main features have the following characteristics.
Product names made of nouns:
Product names mixing Korean and English:

Product names that include product/model code of combined letters and numbers:
Product names that include words to describe the product concept (e.g.
loose fit)
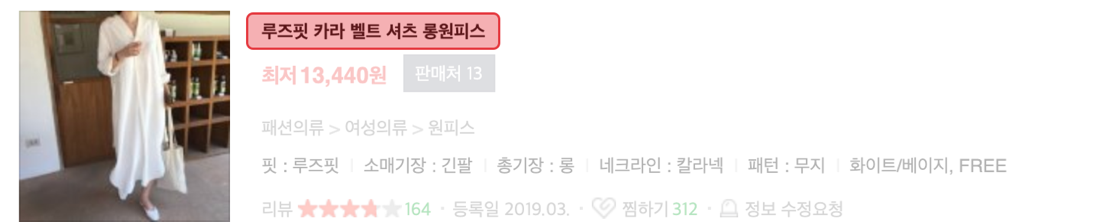
Product names with no spacing. Meaning can be understood even without spacing due to the characteristics of Korean:
For the product name to have the meaning that fits the shopping domain, the words, model code, and product properties describing the concept should not be separated, while the product name without spacing is extracted in units of terms.
Next is an example of analyzing morphemes using the NAVER language processing system followed by extracting a term from a product name. Before extracting a term, special characters are removed from the product name in the normal expression method. (However, dashes (-), which are frequently used in model codes, are not removed)
 |
| An example of the result in extracting term from product name. |
Word Embeddings
We thought about the method of effectively inserting the product without losing much information with the input of the model since product name is specialized in the shopping domain. As Random Sequence Method that assigns numbers after making the words dictionary (E.g. For girls=1000, for boys =1001) is similarly activated in the model, making it easy to lose the meaning and the relations of the words, we used a method that maps the words to a higher-order and expresses them with vectors.
We tried to use a pre-trained vector with the content of
Wikipedia, but thought that the characteristics of the product data were not considered for the building of
word embeddings. So we built word embedding that includes characteristics of the product data using the
Word2vec method firsthand.
Whether the embedding vector, the result of Word2vec, is built correctly or not can be explored with
TensorBoard, the visualization tool of TensorFlow. Below is the result of visualizing a vector of 4,000 categories
CNN-LSTM Model — Product Name
Learn by applying CNN-LSTM model in the following order for the product name, which is text data.
- CNN model: Extract features of specific text area from product name.
- LSTM model: Identify meaning of current word based on nearby words from the long product name.
- CNN-LSTM model: Local features extracted by CNN are sequentially integrated in LSTM.
CNN model
The Convolution Neural Network (CNN) model is a network originally developed for image processing. This model extracts an image’s features as the filter moves, regardless of the location of objects in the image.
 |
| A CNN (Convolutional Neural Network) |
There have been many efforts to apply the CNN algorithm in NLP as well as images. According to the paper
Convolutional Neural Networks for Sentence Classification, CNN filters can extract the features of a specific image area in image processing and extract the features of a specific text area in text processing.
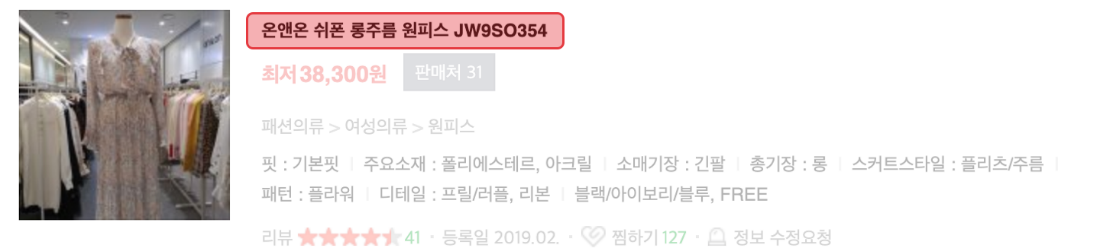
In NAVER Shopping’s product name, you can see the main keywords of the product that appear regardless of the location as follows.
- Adidas Original Women Trefoil **Dress**
- On and On Chiffon Long Pleated **Dress** JW9SO354
LSTM model
The Long-Term Short Term Memory (LSTM) model is a network based on Recurrent Neural Networks (RNN).
 |
| LSTM (Long Short-Term Memory) |
An RNN is a network that makes the information gained from the previous stage last, by remembering the previous input data from the current input data. However, RNN could not solve the long-term dependencies issue (for example, it predicts words well in short sentences, but cannot predict the words in long sentences). LSTM is a model that solved this issue.
Normally, the meaning of words in a text (irony, for example) is understood based on the words nearby (words before and after). This being so, the LSTM model is known as a model suitable for data processing that appears sequentially as in the article.
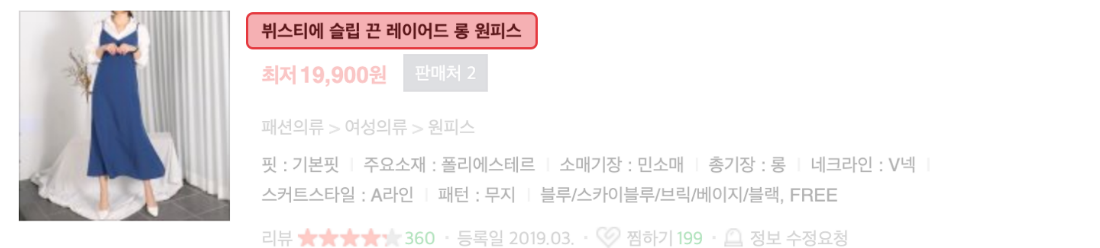
In the product name of NAVER Shopping, you can see the product names that can be classified only when looking at the keywords around, as follows.
- **bustier** Slip Strap Layered Long **Dress**
- **Shirts** Loose-fit Collar Long **Dress**
CNN-LSTM model
Next is the architecture of CNN-LSTM model suggested in the paper
Dimensional Sentiment Analysis Using a Regional CNN-LSTM Model.
 |
| CNN-LSTM Model |
CNN-LSTM Model shows much superior performance. It is a method that passes through convolution layer and max pooling layer by inputting word embedding (vector) to extract local characteristics and then integrates the features sequentially using the LSTM model.
A CNN model can extract the specific local information by dividing the input data into many areas, but cannot determine the dependency between words in long sentences. Such limitations can be solved by combining the CNN model with the LSTM model to sequentially integrate the local information in the sentence.
MobileNetV2 — Product Image
MobileNet is a model that is available for image classification and object detection.
 |
| MobileNet - Depthwise Convolution Filter |
VGG, a model that came out before MobileNet, is a Deep Neural Net composed of various layers. It has great performance, enough to come 2nd in one
Large Scale Visual Recognition Challenge, but it is a model difficult to use in computers with limited capacity and resources due to having many parameters.
With the continuing research to balance performance and efficiency, in April 2017, Google disassembled Standard Convolution and announced
MobileNets that uses a Depth-wise Convolutional Filter. In April 2018, one year later, it announced
MobileNetV2 that used Linear Bottlenecks structure and Residual Connection.
The accuracy of MobileNet is similar when compared to VGG. However, MobileNet has 1/10 the number of computations and parameters compared to VGG, making it suitable for a server without GPU equipment or services requiring real-time performance.
Multi Input Model — Product misc. Information
For the auto-matching of categories, models using the product name and those using the product image may be trained separately. However, as product names and images are the property of a singular product, integrated training actually improves the model’s accuracy.
If you perform integrated training of not only a product name and image, but also a brand, maker, original image proportion, categories used in business operations, and the lowest price of the product, all added in as seen in the picture below, you can then train the correlation of properties related to products.
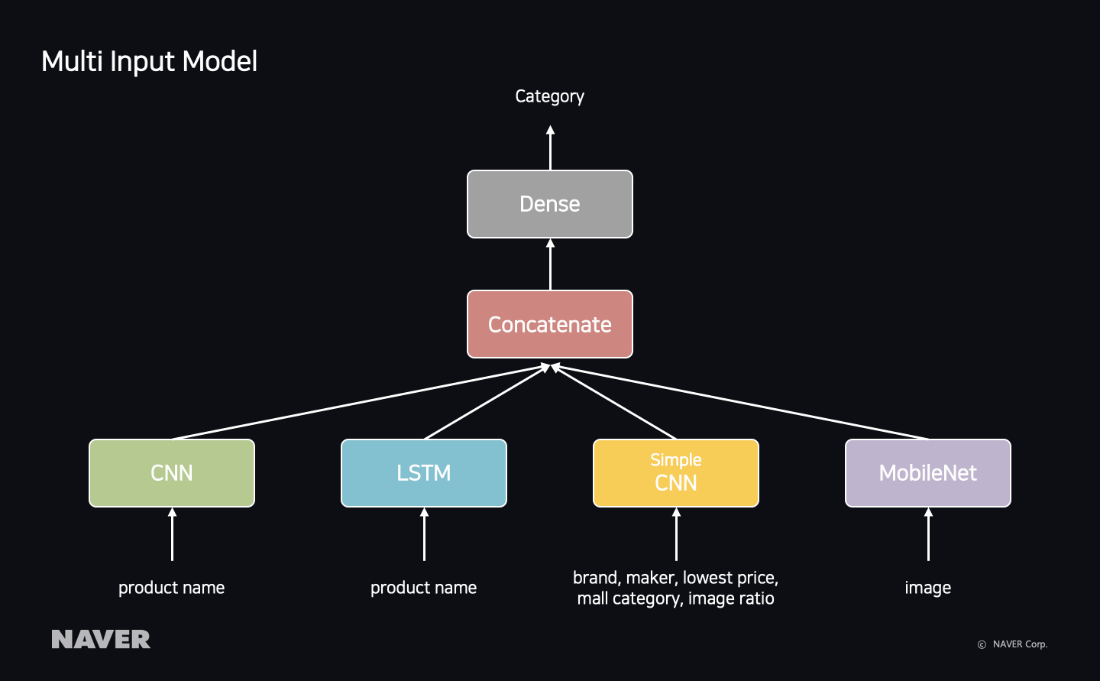 |
| Multi Input Model |
Problems found in Category Auto-Matching and solutions
A few problems have been found while applying category auto-matching to actual service data.
Feature Visualization
Prior to the application of category auto-matching, there must be a way to verify whether matching results have been properly distributed. If you upload the feature vector and label suited for the TensorFlow’s embedding projector, category distribution and the distance between categories can be readily checked. Next, you can see the visualization results of approximately 4,000 category vectors.
 |
| Feature Visualization |
By clicking one point (category), you can see what the points (similar categories) near that point is. If the point is located nearby in the visualization result, but not the related category at all, it means it is a category with a high probability of incorrect matching.
You can find a tutorial to do this yourself
here.
Data Normalization
The ratio of product quantity between
Fashion clothing > Women’s clothing > Dress, which is a popular category on NAVER Shopping, and
Living/Health > DVD > Culture/Documentary, which is not a popular category is about 1000:1, making the data highly unbalanced. If trained using learning data in an unbalanced product distribution like this, it can cause issues where appropriate results become biased toward a category with more numerous products to increase the overall accuracy.
The bottom left graph is before applying data normalization, and the product distribution by category shows a shape of index function. So we applied a log function as follows to learning data for data normalization:

By applying data normalization, the number of products has been distributed evenly by category as shown in the graph on the right, and the issue with appropriate results being biased toward popular categories has been solved.
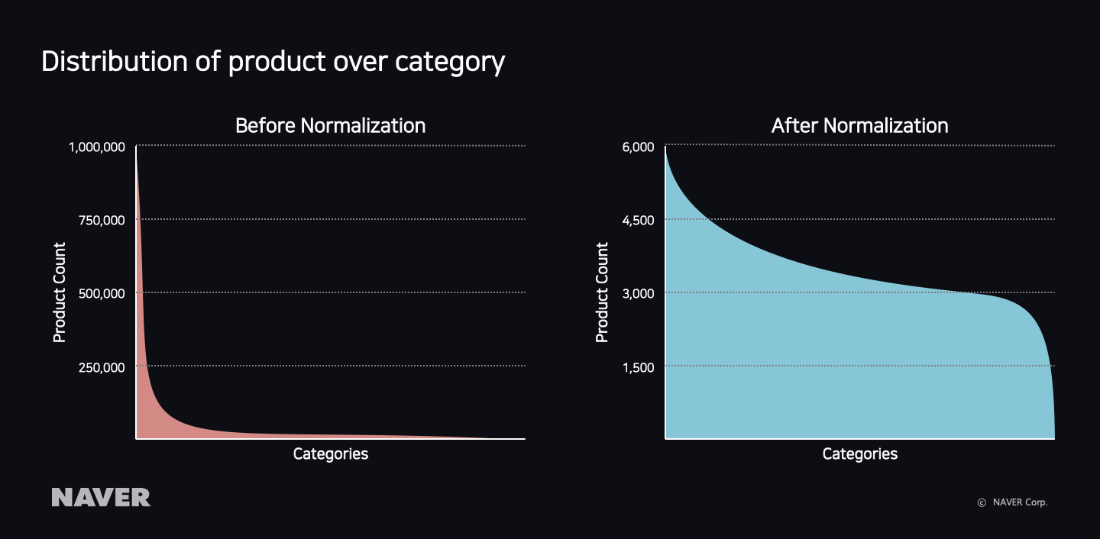 |
| Product Distribution by Category |
Reflecting Trends
Products in online shopping malls have short lifespans and are very sensitive to trends. In particular, since products like clothing are produced for each season, there is a tendency for products to be continuously deleted and created. For example, a model that has only learned using text will find it difficult to understand what category it is only by reading the words when there is a new trend product added, such as “Anorak”. A model that learned text and image together can classify it as a Jacket when there is a new product called “Anorak” added, by using the image.
In this case, we should analyze Long-Term Accuracy, like the following graph, to verify whether the model can continue to predict accurately, and let it follow the trend of products while constantly updating the learning data and the model to meet the trend.
 |
| Long-Term Accuracy Analysis |
Training Data Pipeline
Generally, to update the learning data, we must extract through SQL syntax from HDFS to be saved as a file in the learning server, followed by loading the data in the code and retraining the model. In this general method, the time taken to save as a file and load becomes longer, as the learning data becomes larger, as well as taking up much disc space of the service, making it inefficient.
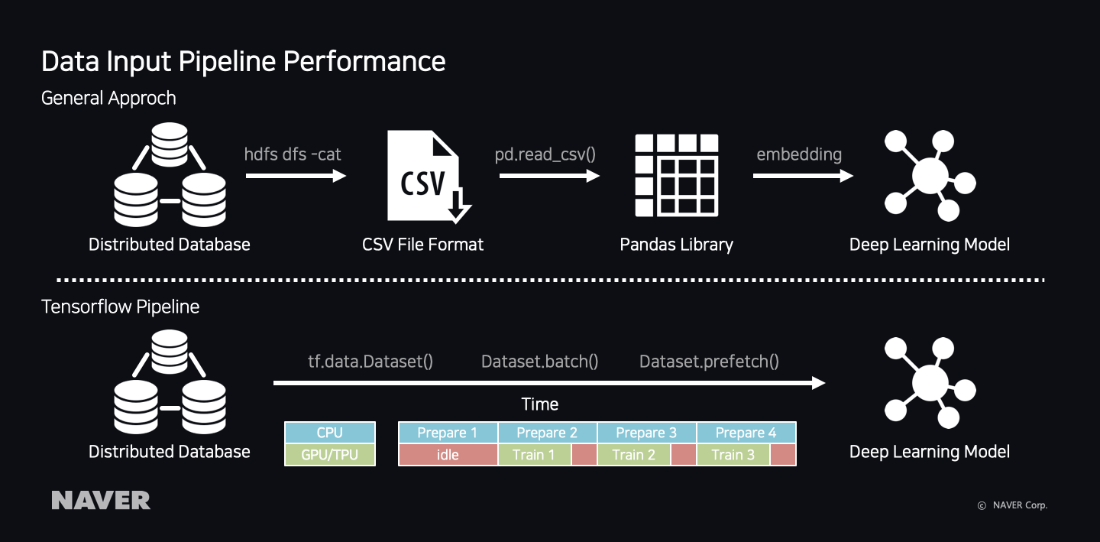
Data Pipeline Performance Comparison
TensorFlow provides a method that directly reads learning data from HDFS using the
tf.data pipeline. When using the
Dataset.prefetch() method, as used by the example below, since it reads the data in chunks, it can prepare the 2nd data in the CPU while learning the first data in the GPU, reducing the idle state of resources.
Remaining Tasks
Although we tried to improve the category auto-matching model while solving issues that arose in actual data, there are matters yet to be improved.
Ambiguous Categories
The categories of NAVER Shopping are structured for user convenience, and it is hard to distinguish the upper categories due to many lower categories of the same name. Since it is not a good structure to allow the model to learn, it is necessary to either select categories requiring additional learning to change to a structure that is easy for the model to learn, or manage the standard categories (e.g.
UNSPSC, The United Nations Standard Products & Services Code) in the commerce environment separately and let it learn.
 |
| Ambiguous Categories |
Incorrect information from the seller
There are cases where the seller sends product information by matching the product category to the NAVER Shopping category first hand. This information is also a condition to be used for learning data, since it is data matched by a person. However, sometimes the main product elements used for learning contain errors. To remove the erroneous data from learning data, we should use methods such as giving more weight in learning by choosing sellers who send high-quality product information.
 |
| Example of incorrect information from seller |
Wrapping up
We have discussed the category auto-matching model operated in NAVER Shopping as well as related problems and solutions.First, we found useful features from products, analyzed morphemes in the case of text data, and used CNN and LSTM models. For image data, we used MobileNet model to develop the category auto-matching model.
In addition, we also looked at data visualization using TensorBoard, as well as how to use the pipeline of data normalization and TensorFlow.
While delivering this project, we have been able to more fully understand the problems of machine learning and deep learning, in the process of identifying other issues that exist, rather than only looking at the accuracy of the model, when applying the model in a real service environment.
Currently, the accuracy of auto-matching is about 85%. We aim to continue to improve the model to achieve higher accuracy by using various methods, such as date refinement of product name, efficiency of image feature extraction, and accurate verification set building.





