https://blog.tensorflow.org/2019/12/example-on-device-model-personalization.html?hl=nb
https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEg8Ry3mIRwvSC71u52LEpb0i26vhZHX7VbagjiP_7FIB0EzbSb3XD5i72gsZof2tPTWVkS2g80xrd_-_50uktgZ44qRsHR95rMRFGxITATKHvClTrLnECtRSqFaselGlUuHMmgn7JCU8eI/s1600/imageLikeEmbed.png
Posted by Pavel Senchanka, Software Engineering Intern at Google
TensorFlow Lite is an industry-leading solution for on-device inference with machine learning models. While a complete training solution for TensorFlow Lite is still in progress, we're delighted to share with you a new on-device transfer learning example. This illustrates a way of personalizing your machine learning models on-device that you can utilize right now. Let’s dive in and explore the problems that transfer learning can solve and how it works.
Why personalized machine learning is useful
Machine learning solutions for a lot of problems today rely on an enormous amount of training data. Image recognition, object detection, speech, and language models are carefully trained on high-quality datasets so that they can be as generic and unbiased as possible. This scale solves many problems, but it is not customized to individual user needs.
Suppose that you want to get the best user experience possible by adjusting the model to users’ needs. Sending user data to the cloud to train the model requires a lot of care to prevent potential privacy breaches. It's not always practical to send data to a central server for training---issues like power, data caps, and privacy can be problematic. However, training directly on device is a strong approach with many benefits: Privacy-sensitive data stays on the device so it saves bandwidth, and it works without an internet connection.
This poses a challenge: Training can require a non-trivial number of data samples which is hard to get on-device. Training a deep network from scratch can take days on the cloud so it's not suitable on device. Instead of training a whole new model from scratch, we can retrain an already trained model to adapt to a similar problem through a process called transfer learning.
What is transfer learning?
Transfer learning is a technique that involves using a pre-trained model for one “data-rich” task and retraining a part of its layers (typically the last ones) to solve another, “data-poor” task.
For example, you can take an image classification model (e.g. MobileNet) that is pre-trained on one set of classes (e.g. those provided in ImageNet) and retrain the last few layers for another task. Transfer learning is not limited to images; you can apply a similar technique to text or speech as well.
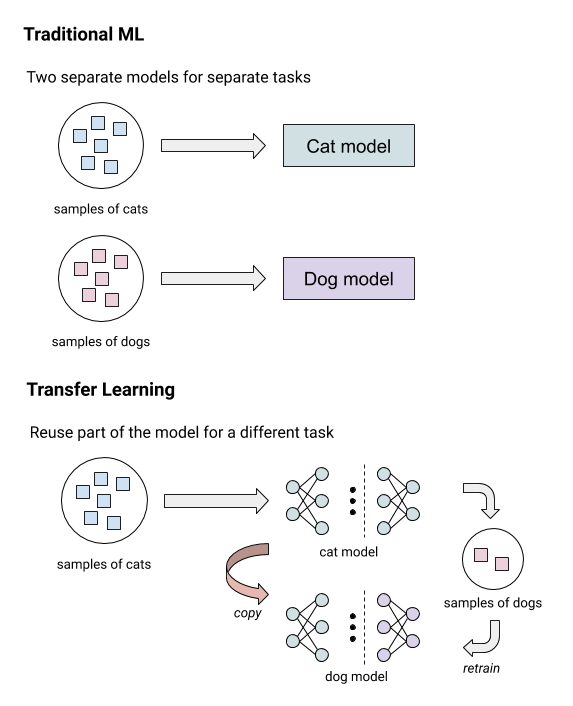 |
| This illustration shows the conceptual difference between traditional ML and transfer learning. |
Using transfer learning, you can easily train personalized models on-device even with limited training data and computational resources, all while preserving user privacy.
Train an image classifier on your Android device
The example project that we released includes an Android application that learns to classify camera images in real-time. The training is performed on-device by taking sample photos of different target classes.

The app uses transfer learning on a quantized MobileNetV2 model pre-trained on ImageNet with the last few layers replaced by a trainable softmax classifier. You can train the last layers to recognize any four new classes. Accuracy depends on how “hard” the classes are to capture. We have observed that even just tens of samples can be enough to achieve good results. (Compare this to ImageNet, which has 1.3 million samples!).
The app can run on any reasonably recent Android device (5.0+), so we encourage you to try it out. The published example includes project configuration compatible with Android Studio. To run it, simply import the project in Android Studio, connect your device, and click “Run.” The project
README file includes more detailed instructions. Share your experience with us using #TFLite, #TensorFlow, and #PoweredByTF!
Use our transfer learning pipeline to solve your own task
The new GitHub example includes a set of easily reusable tools that make it easy to create and use your own personalizable models. The example includes three distinct and isolated parts, each of them responsible for a single step in the transfer learning pipeline.

Converter
To generate a transfer learning model for your task, you need to pick two models that will form it:
- Base model that is typically a deep neural network pre-trained on a generic data-rich task.
- Head model that takes the features produced by the base model as inputs and learns from them to solve the target (personalized) task. This is typically a simpler network with a few fully-connected layers.
You can either define your models in TensorFlow or use some of the convenience shortcuts that come included with the converter. In particular,
SoftmaxClassifier is a shortcut for the head model containing one fully-connected layer and a softmax activation, which is specifically optimized to work better with TensorFlow Lite.
The transfer learning converter provides a CLI, as well as a Python API, so you can use it from your programs or notebooks.
Android library
The transfer learning model produced by the transfer learning converter cannot be used directly with the TensorFlow Lite interpreter. An intermediate layer is required to handle the non-linear lifecycle of the model. We currently only provide an Android implementation of this intermediate layer.
The Android library is hosted as a part of the example, but it lives in a stand-alone Gradle module so it can be easily integrated into any Android application.
To learn more about the transfer learning pipeline, check out the detailed description in the
README.
Future work
The evolution of the transfer learning pipeline in the future is likely to be coupled with the development of the full training solution in TensorFlow Lite. Today we provide the transfer learning pipeline as a separate example on GitHub, and in the future we plan to support full training. The transfer learning converter would then be adapted to produce a single TensorFlow Lite model that would be able to run without an additional runtime library.
Thanks so much for reading! Please tell us about any projects you make with this at
TensorFlow Lite Google Group.
Acknowledgements
This project was a team effort and was made possible thanks to Yu-Cheng Ling and Jared Duke who guided me through the process, Eileen Mao and Tanjin Prity, fellow interns, and everyone else from the TensorFlow Lite team at Google.






