https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEiup2URfcncYQMHf4s9RLeCd1yc5SpP8eEACgKLBcoNHbCiJTyQ9bHsm0Xm1wChFAD94GNcOQUwCL1AuIPh-S43GYI12PDNcuAQVVxAwkI7LUCwt5bAVT0WDonJ_QN7XtCVNg6H8mJLatM/s1600/pruning.png
Posted by Rina Panigrahy
Matrix Compression
Tensors and matrices are the building blocks of machine learning models -- in particular deep networks. It is often necessary to have tiny models so that they may fit on devices such as phones, home assistants, auto, thermostats -- this not only helps mitigate issues of
network availability, latency and power consumption but is also desirable by end users as user data for the inference doesn’t need to leave the device which gives a stronger sense of
privacy. Since such devices have a lower storage, compute and power capacity, to make models fit one often needs to cut corners such as limiting the vocabulary size or compromising the quality. For this purpose it is useful to be able to compress matrices in the different layers of a model. There are several popular techniques for compressing matrices such as pruning, low-rank-approximation, quantization, and random-projection. We will argue that most of these methods can be viewed as essentially factoring a matrix into two factors by some type of factorization algorithm.
Compression Methods
Pruning: A popular approach is
pruning where the matrix is sparsified by dropping (zeroing) the small entries---very often large fractions of the matrix can be pruned without affecting its performance.
 Low Rank Approximation:
Low Rank Approximation: Another common approach is
low rank approximation where the original matrix A is factored into two thinner matrices by minimizing the
Frobenius error |A-UV
T|
F where U, V are low rank (say rank k) matrices. This minimization can be solved optimally by using
SVD (Singular Value Decomposition)..
 Dictionary Learning
Dictionary Learning: A variant of low rank approximation is sparse factorization where the factors are sparse instead of being thin (note that thin matrix can be viewed as a special case of sparse as a thin matrix is also like a bigger matrix zero entries in the absent columns). A popular form of sparse factorization is
dictionary learning; this is useful for embedding tables that are tall and thin and thus already have a low rank to begin with -- dictionary learning exploits the possibility that even though the number of embedding entries may be large there may be a smaller dictionary of basis vectors such that each embedding vector is some sparse combination of a few of these dictionary vectors -- thus it decomposes the embedding matrix into a product of smaller dictionary table and a sparse matrix that specifies which dictionary entries are combined for each embedding entry.

The commonly used
random projections which involves using a random projection matrix to project the input into a smaller dimensional vector and then training a thinner matrix is simply a special case of matrix factorization where one of the factors is random.
Quantization: Another popular method is
quantization where each entry or a block of entries is quantized by possibly rounding the entries into a small number of bits so that each entry (or a block of entries) gets replaced by a quantized code. Thus the original matrix gets decomposed into a codebook and an encoded representation; each entry in the original matrix is obtained by looking up the code in the encoding matrix in the codebook. Thus it can again be viewed as a special product of the codebook and the encoding matrix. The codebook can be computed by some clustering algorithm (such as k-means) on the entries or blocks of entries of the matrix. This is in fact a special case of dictionary learning with sparsity one as each block is being expressed as one of the vectors in the codebook (which can be viewed as the dictionary) instead of a sparse combination. Pruning can also be viewed as a special case of quantization where each entry or block is pointing to a codebook entry that is either zero or itself.
Thus there is a continuum from pruning to quantization to dictionary learning and they are all forms of matrix factorization just as low-rank-approximation.

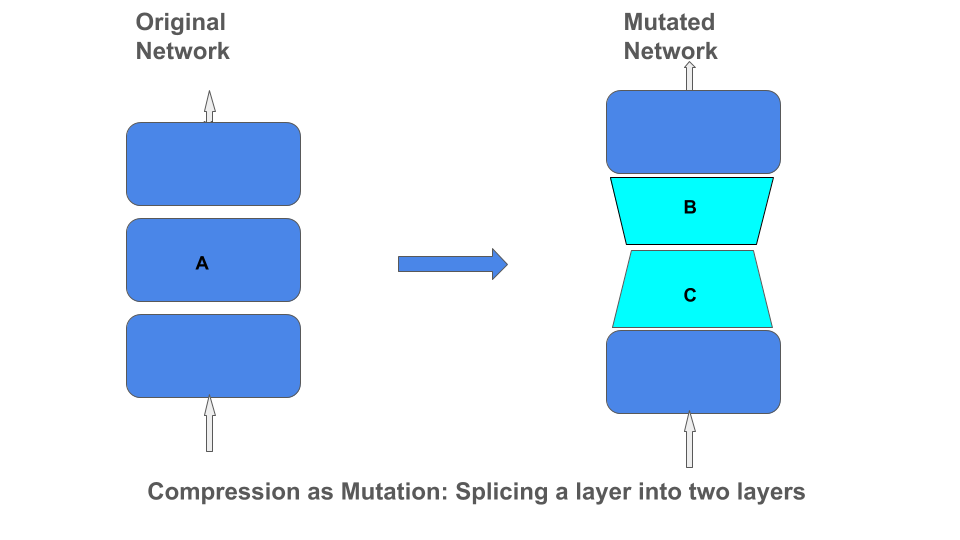
Factorization as Mutation
Applying these different types of matrix factorizations can be viewed as mutating the network architecture by splicing a layer into a product of two layers.
Tensorflow Matrix Compression operator
Given the wide variety of matrix compression algorithms it would be convenient to have a simple operator that can be applied on a tensorflow matrix to compress the matrix using any of these algorithms during training. This saves the overhead of first training the full matrix, applying a factorization algorithm to create the factors and then creating another model to possibly retrain one of the factors. For example, for pruning once the mask matrix M has been identified one may still want to continue training the unmasked entries. Similarly in dictionary learning one may continue training the dictionary matrix.
We have
open sourced such a compression operator that can take any custom matrix factorization method specified in a certain MatrixCompressor Class. Then to apply a certain compression method one simply calls apply_compression(M, compressor = myCustomFactorization). The operator dynamically replaces a single matrix A by a product of two matrices B*C that is obtained by factoring A by the specified custom factorization algorithm. The operator in real time lets the matrix A train for some time and at a certain training snapshot applies the factorization algorithm and replaces A by the factors B*C and then continues training the factors (the product ‘*’ need not be the standard matrix multiplication but can be any custom method specified in the compression class). The Compression operator can take any of a number of factorization methods mentioned before.
For the dictionary learning method we even have an
OMP based implementation of dictionary learning that is faster than the
scikit implementation. We also have an improved
gradient based pruning method that not only takes into account the magnitude of the entries to decide which ones to prune but also its effect on the final loss by measuring the gradient of the loss with respect to the entry.
Thus we are performing a mutation of the network in real time where in the beginning there is only one matrix and in the end this produces two matrices in the layer. Our factorization methods need not even be gradient based but may involve more discrete style algorithms such as hashing,
OMP for dictionary learning, or clustering for k-means. Thus our operator demonstrates that it is possible to mix continuous gradient based methods with more traditional discrete algorithms. The experiments also included a method based on random projections called
simhash -- the matrix to be compressed is multiplied by a random projection matrix and the entries are rounded to binary values -- thus it is a factorization into one random projection matrix and a binary matrix. The following plots show how these algorithms perform on compressing models for
CIFAR10 and
PTB. The results show that while low-rank-approximation beats simhash and k-means on CIFAR10, on PTB dictionary learning is slightly better than low-rank-approximation.
CIFAR10

PTB

Conclusion
We developed an operator that can take any matrix compression function given as a factorization and create a tensorflow API to apply that compression dynamically during training on any tensorflow variable. We demonstrated its use via a few different factorization algorithms including dictionary learning and showed experimental results on models for CIFAR10 and PTB. This also demonstrates how we one can dynamically combine discrete procedures (such as sparse matrix factorization and k-means clustering) with continuous processes such as gradient descent.
Acknowledgements
This work was made possible by the contributions of several people including Xin Wang, Badih Ghazi, Khoa Trinh, Yang Yang, Sudeshna Roy and Lucine Oganesian. Also thanks to Zoya Svitkina and Suyog Gupta for their help.






