https://blog.tensorflow.org/2020/03/part-1-fast-scalable-and-accurate-nlp-tensorflow-deploying-bert.html?hl=es_419
https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEhWJ2AwUPtnioab3hD6MxsgPzNCLWuy3B_HGH99oqrMSPBvg0Kx9E_xXP8P5TeGpnOsppDacTE1ajQuTzkTPyqZfyFWIzduupu3-UHTncTb1dckkge8t-wYgpDEZHAYnhKkRPUZLjsb7Kg/s1600/figure1.png
Part 1: Fast, scalable and accurate NLP: Why TFX is a perfect match for deploying BERT
Posted by Guest author Hannes Hapke, Senior Machine Learning Engineer at SAP’s Concur Labs. Edited by Robert Crowe on behalf of the TFX team.
Transformer models, especially the
BERT model, have revolutionized NLP and broken new ground on tasks such as sentiment analysis, entity extractions, or question-answer problems. BERT models allow data scientists to stand on the shoulders of giants. When the models have been pre-trained on large corpora by corporations, data scientists can apply transfer learning to these multi-purpose trained transformer models and achieve groundbreaking results for their domain-specific problems.
At
SAP’s Concur Labs, we wanted to join the party and use BERT for new problems in the travel and expense domain. We wanted to simplify our BERT inferences. Unfortunately, the solutions we tried never felt perfect.
By collaborating with the Google/TensorFlow team, and using their latest developments, we were finally able to achieve our goal of consistent, simple, and especially fast BERT model inferences. With the proposed implementation, we achieve predictions from raw text to a classification in a few milliseconds. Let’s take a look at how the various TensorFlow libraries and components have helped us reach that milestone.
This blog post will provide you an overview of how the TensorFlow ecosystem can be used to achieve a scalable, fast, and efficient BERT deployment. If you are interested in a deep dive into the implementation, check out
Part Two of this blog post on the details of the implementation steps. If you want to try out our demo deployment, check out our
demo page at Concur Labs showcasing our sentiment classification project.
A note about Serving
The approach discussed in this blog post will allow developers to train TensorFlow models using TensorFlow Extended (TFX) v0.21 or later. However, support for the tf.text ops which are included in the resulting trained model is not yet included in the current release of TensorFlow Serving (v2.1), but is included in the nightly docker release and will be included in the v2.2 release.
Want to jump ahead to the code?
If you would like to jump to the complete example,
check out the Colab notebook. It showcases the entire TensorFlow Extended (TFX) pipeline to produce a deployable BERT model with the preprocessing steps as part of the model graph.
The current state of BERT deployments
The recent developments of transformer models have been astonishing. But unfortunately, taking the models to production never felt simple or perfect. Ideally, we’d like to send the raw text to a server, but the BERT model requires preprocessing of the input text before we can get predictions from the actual model. Some existing solutions have solved this problem by preprocessing the text on the client-side, while other solutions have implemented an intermediate step on the server-side to manipulate the input data. Both options never felt quite right, since they require additional deployment coordination (e.g. during the client-server handoff) or make the inferences less efficient (e.g. complicated prediction batching capabilities due to the intermediate transformation step).
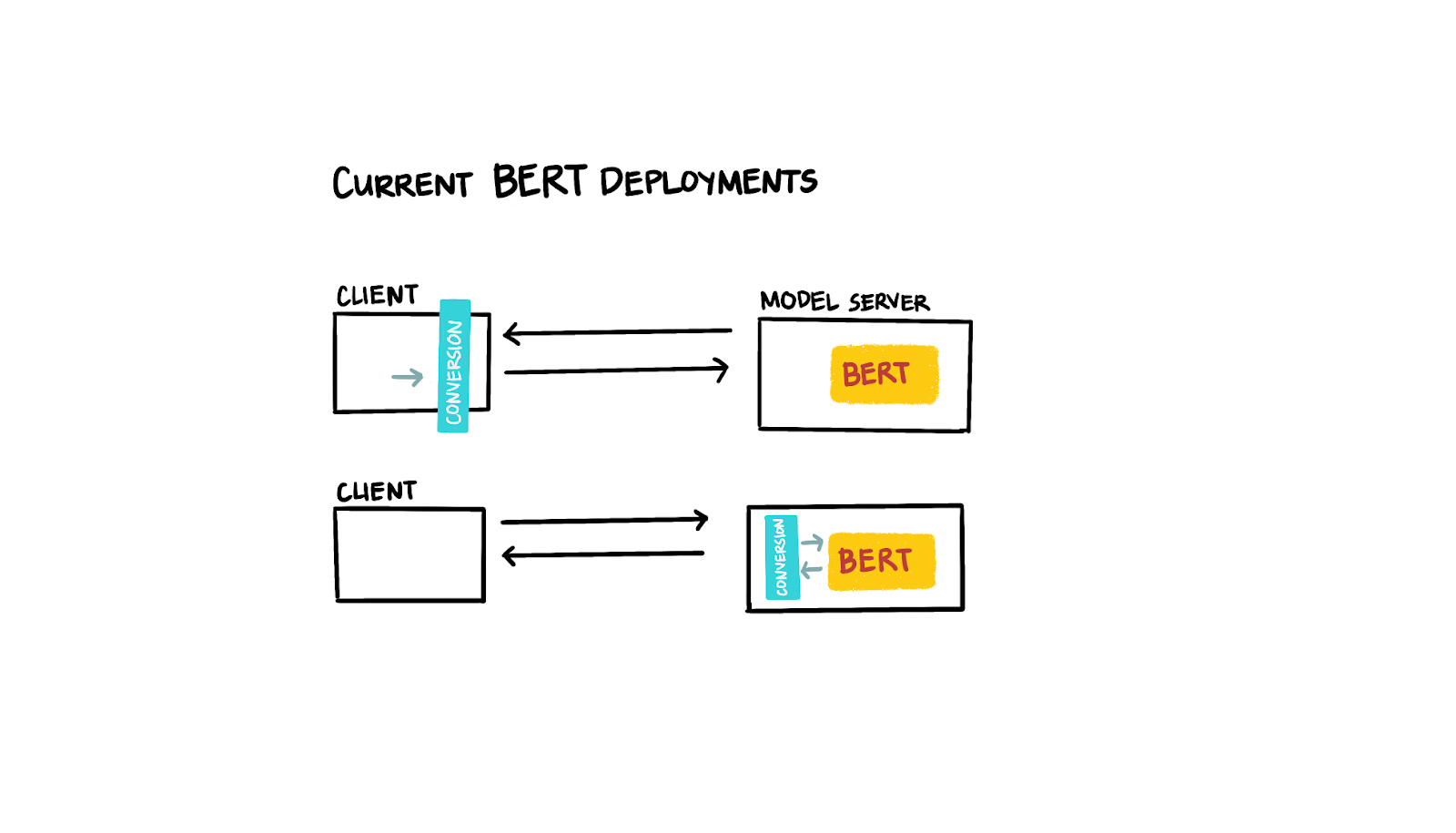 |
| Figure 1: Current BERT deployments |
What does the optimal deployment look like?
When it comes to deploying models, simpler is better. We wanted to deploy transformer models with the preprocessing as part of the model graph. Because the preprocessing is integrated into the model graph, we are able to simply deploy a single model to our model server, remove any other deployment dependencies (client or intermediate preprocessing), and take advantage of the full benefits of model servers (e.g. batching prediction requests for the optimal usage of our inference hardware).
Deploying BERT with the TensorFlow Ecosystem
TensorFlow has been a very productive framework for us because it isn’t just a machine learning framework, but it also provides an extensive ecosystem of supporting packages and tools. A tool that has been useful to us is
TensorFlow Serving. It provides simple, consistent, and
scalable model deployments.
Another ecosystem project we follow very closely is
TensorFlow Transform. It provides us the opportunity to build our model preprocessing steps as graphs which we can then export together with actual deep learning models. TensorFlow Transform requires that all preprocessing steps are expressed as TensorFlow ops. This is why the most recent developments of
TensorFlow Text were extremely helpful. Not only did the implementation of
RaggedTensors open up new implementations, but the library also provided the needed functionality to implement natural language preprocessing steps.
One of the new capabilities of TensorFlow Text,
presented at TensorFlowWorld 2019, is the complete implementation of a
BERT Tokenizer. Because of this, we were able to express our preprocessing steps with a few lines of TensorFlow code. We also achieved our goal of consistent model pipelines and deployments by utilizing one more TensorFlow tool:
TensorFlow Extended (TFX). TFX allows us to express our entire ML pipelines in a reproducible way and therefore helps us deploy consistent machine learning models.
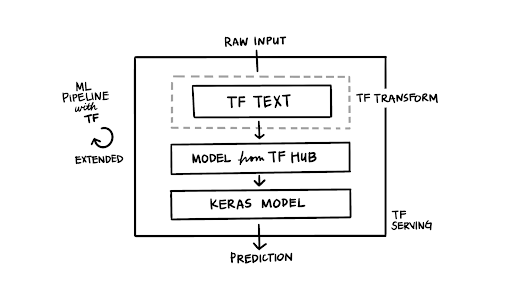 |
| Figure 2: TFX pipeline with tf.Text |
Writing the preprocessing steps with TensorFlow ops
The ideal model deployment accepts raw text as an input to the model and provides the model predictions in return. The key to the simplification of our BERT deployments is the expression of the preprocessing steps as TensorFlow ops. The BERT model requires that the raw input text to be tokenized into token IDs, an accompanying data structure of an input mask, and generated input type IDs. With the help of TensorFlow Text, we can now achieve this with far fewer lines of code. In the second part of this blog post, we are discussing the details of the conversion from raw text to the BERT specific data structures, including the adding of the BERT specific tokens.
vocab_file_path = load_bert_layer().resolved_object.vocab_file.asset_path
bert_tokenizer = text.BertTokenizer(vocab_lookup_table=vocab_file_path,
token_out_type=tf.int64,
lower_case=do_lower_case)
...
input_word_ids = tokenize_text(text)
input_mask = tf.cast(input_word_ids > 0, tf.int64)
input_mask = tf.reshape(input_mask, [-1, MAX_SEQ_LEN])
zeros_dims = tf.stack(tf.shape(input_mask))
input_type_ids = tf.fill(zeros_dims, 0)
input_type_ids = tf.cast(input_type_ids, tf.int64)
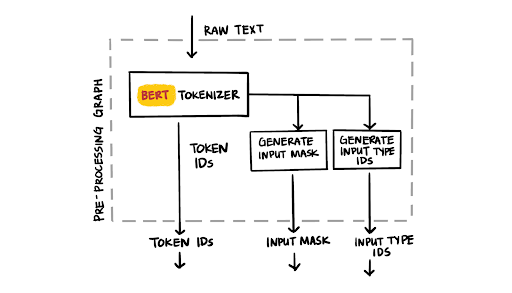 |
| Figure 3: BERT tokenizer |
Using TensorFlow Transform and the code above, the preprocessing graph can then be exported together with the trained TensorFlow model. With the latest updates to TensorFlow Serving, our deployed BERT model can now accept the raw text as inputs. Voila! No additional deployment dependencies.
Using TensorFlow Transform provided us a few practical benefits. On the one hand, we can organizationally split the responsibilities between the data preprocessing and the model architecture work. On the other hand, we can easily debug, test and generate statistics of the preprocessing output. The transform component outputs the transformed training sets (as TFRecords), which can be easily inspected. During the “debugging” of the Transform output, we discovered small bugs that wouldn’t have failed the training of the model, but probably influenced its performance (e.g. an offset in the [SEP] token). TensorFlow Transform technically isn’t required here. Since each example preprocessing happens independently from the entire corpus, we could have easily built it directly into the model graph. But we found it easier to construct and debug the pipeline this way.
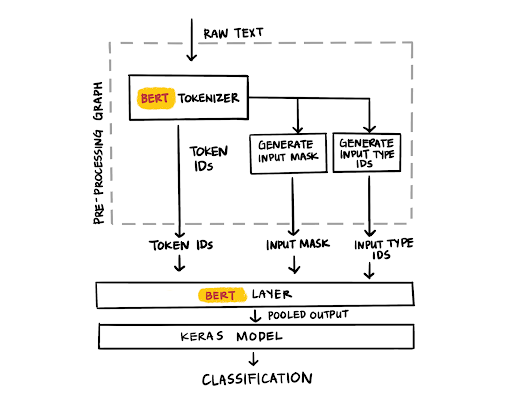 |
| Figure 4: BERT layer |
If you are interested in a deep dive into the implementation, we recommend part two of this blog post with an in-depth look at the implementation.
The ideal deployment?
Simplified development
By utilizing a variety of TensorFlow tools, we were able to deploy BERT models in a simple and concise way. Integrating the preprocessing steps into the model graph reduces the risk of skew between the training and inference data. The deployed model requires no additional client or server dependencies, which further reduces the risk of model errors. We can deploy our BERT models consistently with TensorFlow Serving while also taking advantage of the model optimizations like batch inferences.
Inference performance
Our initial performance tests are looking very promising. Inferences on our demo BERT model graph containing the preprocessing steps and the model average to around 15.5 ms per prediction (measured on a single V100 GPU, max 128 tokens, gRPC requests, non-optimized TensorFlow Serving build for GPUs, uncased Base BERT model). Previous deployments with the BERT tokenization on the client-side and the classification model being hosted with TensorFlow Serving averages to about the same inference time. Of course depending on your machine (and model), you may see different results.
For more information
If you are interested in a deep dive into the implementation, we recommend part two of this blog post. If you would like to dive into the code,
check out the Colab notebook with an example implementation of a sentiment classification model using a pre-trained BERT model. If you want to try out our demo deployment, check out our
demo page at Concur Labs showcasing our sentiment classification project.
If you are interested in the inner workings of TensorFlow Extended (TFX) and TensorFlow Transform, dive into the
TFX User Guide and check out this upcoming O’Reilly publication “
Building Machine Learning Pipelines, Automating Model Life Cycles With TensorFlow” (pre-release available online).
To learn more about TFX, check out the
TFX website, join the
TFX discussion group, dive into other posts in the
TFX blog, watch our
TFX playlist on YouTube, and
subscribe to the TensorFlow channel.
Acknowledgments
This project wouldn’t have been possible without the tremendous support from Catherine Nelson, Richard Puckett, Jessica Park, Robert Reed, and the
Concur Labs team. Thanks also goes out to Robby Neale, Robert Crowe, Irene Giannoumis, Terry Huang, Zohar Yahav, Konstantinos Katsiapis, Arno Eigenwillig, and the rest of the TensorFlow team for discussing implementation details and for providing updates to the TensorFlow libraries. Big thanks also to Cole Howard from Talenpair for always enlightening discussions about Natural Language Processing.






