https://blog.tensorflow.org/2020/06/responsible-ai-with-tensorflow.html?hl=es_419
https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEj9UrK4PYtWtQM0EcUx67uXAJv-9AFy94HhODhDoBZtFgy9iB_4iBpJXAKnzznisZloSFcchWNkk1cQWQteJnZg1SgzJCi_KxG3Do2qfBfWDaZ5ENEC_Moo1MSXz9v-ihny1SPyY80_8pA/s1600/flowchart+5.gif
Posted by Tulsee Doshi, Andrew Zaldivar
As billions of people around the world continue to use products or services with AI at their core, it becomes more important than ever that AI is deployed
responsibly: preserving trust and putting each individual user’s well-being first. It has always been our highest priority to build products that are inclusive, ethical, and accountable to our communities, and in the last month, especially as the US has grappled with its history of systemic racism, that approach has been, and continues to be, as important as ever.
Two years ago, Google introduced its
AI Principles, which guide the ethical development and use of AI in our research and products. The AI principles articulate
our Responsible AI goals around
privacy,
accountability,
security, fairness and
interpretability. Each of these is a critical tenant in ensuring that AI-based products work well for every user.
As a Product Lead and Developer Advocate for Responsible AI at Google, we have seen first-hand how developers play an important role in building for Responsible AI goals using platforms like
TensorFlow. As one of the most popular ML frameworks in the world, with millions of downloads and a global developer community, TensorFlow is not only used across Google, but around the globe to solve challenging real-world problems. This is why we’re continuing to expand the Responsible AI toolkit in the TensorFlow ecosystem, so that developers everywhere can better integrate these principles in their ML development workflows.
In this blog post, we will outline ways to use TensorFlow to build AI applications with Responsible AI in mind. The collection of tools here are just the beginning of what we hope will be a growing toolkit and library of lessons learned and resources to apply them.
You can find all the tools discussed below at
TensorFlow’s collection of Responsible AI Tools.
Building Responsible AI with TensorFlow: A Guide
Building into the workflow
While every TensorFlow pipeline likely faces different challenges and development needs, there is a consistent workflow that we see developers follow as they build their own products. And, at each stage in this flow, developers face different Responsible AI questions and considerations. With this workflow in mind, we are designing our Responsible AI Toolkit to complement existing developer processes, so that Responsible AI efforts are directly embedded into a structure that is already familiar.
You can see a full summary of the workflow and tools at:
tensorflow.org/resources/responsible-ai
To simplify our discussion, we’ll break the workflow into 5 key steps:
- Step 1: Define the problem
- Step 2: Collect and prepare the data
- Step 3: Build and train the model
- Step 4: Evaluate performance
- Step 5: Deploy and monitor

In practice, we expect that developers will move between these steps frequently. For example, a developer may train the model, identify poor performance, and return to collect and prepare additional data to account for these concerns. Likely, a model will be iterated and improved numerous times once it has been deployed and these steps will be repeated.
Regardless of when and the order in which you reach these steps, there are critical Responsible AI questions to ask at each phase—as well as related tools available to help developers debug and identify critical insights. As we go through each step in more detail, you will see several questions listed along with a set of tools and resources we recommend looking into in order to answer the questions raised. These questions, of course, are not meant to be comprehensive; rather, they serve as examples to stimulate thinking along the way.
Keep in mind that many of these tools and resources can be used throughout the workflow—not just exclusive for the step in which it is being featured.
Fairness Indicators and
ML Metadata, for example, can be used as standalone tools to respectively evaluate and monitor your model for unintended biases. These tools are also integrated in
TensorFlow Extended, which provides a pathway for developers to not only put their model into production, but also equipping them with a unified platform to iterate through the workflow in a more seamless way.
Step 1: Define the Problem
What am I building? What is the goal?
Who am I building this for?
How are they going to use it? What are the consequences for the user when it fails?
The first step in any development process is the definition of the problem itself. When is AI actually a valuable solution, and what problem is it addressing? As you define your AI needs, make sure to keep in mind the different users you might be building for, and the different experiences they may have with the product.
For example, if you are building a medical model to screen individuals for a disease, as is done in this
Explorable, the model may learn and work differently for adults versus children. When the model fails, it may have critical repercussions that both doctors and users need to know about.
How do you identify the important questions, potential harms, and opportunities for all users? The Responsible AI Toolkit in TensorFlow has a couple tools to help you:
PAIR Guidebook
The People + AI Research (PAIR) Guidebook, which focuses on designing human-centered AI, is a companion as you build, outlining the key questions to ask as you develop your product. It's based on insights from Googlers across 40 product teams. We recommend reading through the key questions—and use the helpful worksheets!—as you define the problem, but referring back to these questions as development proceeds.
AI Explorables
A set of lightweight interactive tools, the Explorables provide an introduction to some of the key Responsible AI concepts.
Step 2: Collect & Prepare Data
Who does my dataset represent? Does it represent all my potential users?
How is my dataset being sampled, collected, and labeled?
How do I preserve the privacy of my users?
What underlying biases might my dataset encode?
Once you have defined the problem you seek to use AI to solve, a critical part of the process is collecting the data that best takes into account the societal and cultural factors necessary to solve the problem in question. Developers wanting to train, say, a speech detection model based on a very specific dialect might want to consider obtaining their data from sources that have gone through efforts in accommodating languages lacking linguistic resources.
As the heart and soul of an ML model, a dataset should be considered a product in its own right, and our goal is to equip you with the tools to understand who the dataset represents and what gaps may have existed in the collection process.
TensorFlow Data Validation
You can utilize
TensorFlow Data Validation (TFDV) to analyze your dataset and slice across different features to understand how your data is distributed, and where there may be gaps or defects. TFDV combines tools such as
TFX and
Facets Overview to help you quickly understand the distribution of values across the features in your dataset. That way, you don’t have to create a separate codebase to monitor your training and production pipelines for skewness.
 |
| Example of a Data Card for the Colombian Spanish speaker dataset. |
Analysis generated by TFDV can be used to create
Data Cards for your datasets when appropriate. You can think about a Data Card as a
transparency report for your dataset—providing insight into your collection, processing, and usage practices. As an example,
one of our research-driven engineering initiatives focused on creating datasets for regions with both low resources for building natural language processing applications and rapidly growing Internet penetration. To help other researchers that desire to explore speech technology for these regions, the team behind this initiative created Data Cards for different Spanish speaking countries to start with, including
the Colombian Spanish speaker dataset shown above, providing a template for what to expect when using their dataset.
Details on Data Cards, a framework on how to create them, and guidance on how to integrate aspects of Data Cards into processes or tools you use will be published soon.
Step 3: Build and Train the Model
How do I preserve privacy or think about fairness while training my model?
What techniques should I use?
Training your TensorFlow model can be one of the most complex pieces of the development process. How do you train it in such a way that it performs optimally
for everyone while still preserving user privacy? We’ve developed a set of tools to simplify aspects of this workflow, and enable integration of best practices while you are setting up your TensorFlow pipeline:
TensorFlow Federated
Federated learning is a new approach to machine learning that enables many devices or clients to jointly train machine learning models while keeping their data local. Keeping the data local provides benefits around privacy, and helps protect against risks of centralized data collection, like theft or large-scale misuse. Developers can experiment with applying federated learning to their own models by using the
TensorFlow Federated library.
[New] We recently released a
tutorial for running high-performance simulations with TensorFlow Federated using Kubernetes clusters.
TensorFlow Privacy
You can also support privacy in training with
differential privacy, which adds noise in your training to hide individual examples in the datasets. TensorFlow Privacy provides a set of optimizers that enable you to train with differential privacy, from the start.
TensorFlow Constrained Optimization and TensorFlow Lattice
In addition to building in privacy considerations when training your model, there may be a set of metrics that you want to configure and use in training machine learning problems to achieve desirable outcomes. Creating more equitable experiences across different groups, for example, is an outcome that may be difficult to achieve unless you consider taking into account a combination of metrics that satisfy this real-world requirement. The
TFCO and
TensorFlow
Lattice are libraries that provide a number of different research-based methods, enabling constraint-based approaches that could help you address broader societal issues such as fairness.
In the next quarter, we hope to develop and offer more Responsible AI training methods, releasing infrastructure that we have used in our own products to work towards remediating fairness concerns. We’re excited to continue to build a suite of tools and case studies that show how different methods may be more or less suited to different use cases, and to provide opportunities for each case.
Step 4: Evaluate the Model
Is my model privacy preserving?
How is my model performing across my diverse user base?
What are examples of failures, and why are these occurring?
Once a model has been initially trained, the iteration process begins. Often, the first version of a model does not perform the way a developer hopes it would, and it is important to have easy to use tools to identify where it fails. It can be particularly challenging to identify what the right metrics and approaches are for understanding privacy and fairness concerns. Our goal is to support these efforts with tools that enable developers to evaluate privacy and fairness, in partnership with traditional evaluations and iteration steps.
[New] Privacy Tests
Last week, we announced a
privacy testing library as part of TensorFlow Privacy. This library is the first of many tests we hope to release to enable developers to interrogate their models and identify instances where a single datapoint’s information has been memorized and might warrant further analysis on the part of the developer, including the consideration to train the model to be differentially private.
Evaluation Tool Suite: Fairness Indicators, TensorFlow Model Analysis, TensorBoard, and What-If Tool
You can also explore TensorFlow’s suite of evaluation tools to understand fairness concerns in your model and debug specific examples.
Fairness Indicators enables evaluation of common fairness metrics for classification and regression models on extremely large datasets. The tool is accompanied by a
series of case studies to help developers easily identify appropriate metrics for their needs and set up Fairness Indicators with a TensorFlow model. Visualizations are available via the widely popular
TensorBoard platform that modelers already use to track their training metrics. Most recently, we launched a
case study highlighting how Fairness Indicators can be used with pandas, to enable evaluations over more datasets and data types.
Fairness Indicators is built on top of
TensorFlow Model Analysis (TFMA), which contains a broader set of metrics for evaluating common metrics across concerns.
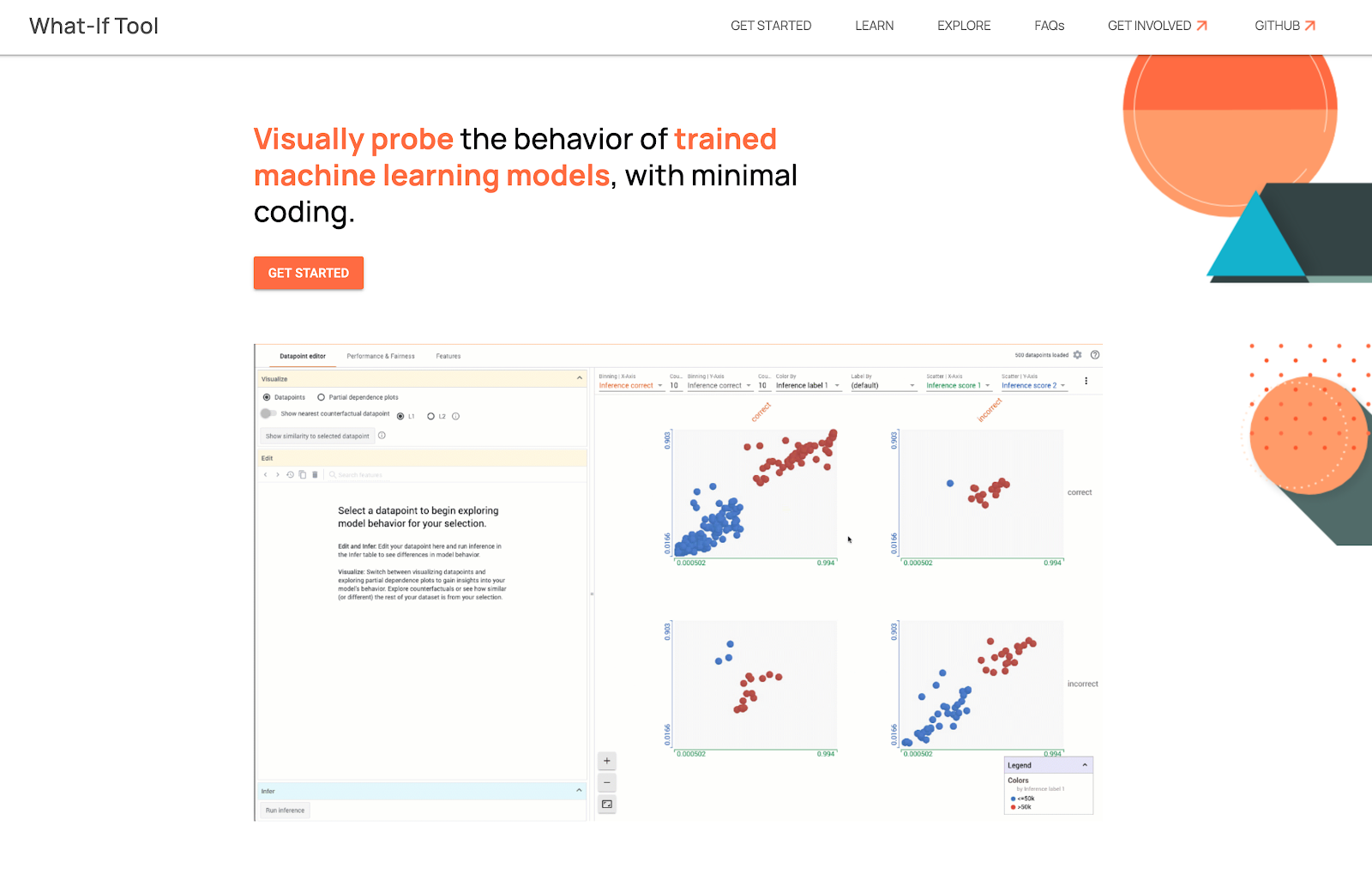 |
| The What-If Tool lets you test hypothetical situtations on datapoints. |
Once you’ve identified a slice that isn’t performing well or want to understand and explain errors more carefully, you can further evaluate your model with the
What-If Tool (WIT), which can be used
directly from Fairness Indicators and TFMA. With the What-if Tool, you can deepen your analysis on your specific slice of data by inspecting the model predictions at the datapoint level. The tool offers a large range of features, from testing hypothetical situations on datapoint, such as “what if this datapoint was from a different category?”, to visualizing the importance of different data features to your model's prediction.
Beyond the integration in Fairness Indicators, the What-If Tool can also be used in other user flows as a standalone tool and is accessible from
TensorBoard or in
Colaboratory,
Jupyter and
Cloud AI Platform notebooks.
[New] Today, to help WIT users get started faster, we’re releasing
a series of new educational tutorials and demos to help our users better use the tool’s numerous capabilities, from
making good use of counterfactuals to interpret your model behaviors, to
exploring your features and identifying common biases.
Explainable AI
Google Cloud users can take WIT’s capabilities a step further with Explainable AI, a toolkit that builds upon WIT to introduce additional interpretability features including
Integrated Gradients, which identify the features that most significantly impacted model performance.
Tutorials on TensorFlow.org
You may also be interested in these tutorials for handling
imbalanced datasets, and for explaining an image classifier using
Integrated Gradients, similar to that mentioned above.
 |
| Using the tutorial above to explain why this image was classified as a fireboat (it’s likely because of the water spray). |
Step 5: Deploy and Monitor
How does my model perform overtime?
How does it perform in different scenarios?
How do I continue to track and improve its progress?
No model development process is static. As the world changes, users change, and so do their needs. The model
discussed earlier to screen patients, for example, may no longer work effectively during a pandemic. It’s important that developers have tools that enable tracking of models, and clear channels and frameworks for communicating helpful details about their models, especially to developers who may inherit a model, or to users and policy makers who seek to understand how it will work for various people. The TensorFlow ecosystem has tools to help with this kind of lineage tracking and transparency:
ML Metadata
As you design and train your model, you can allow ML Metadata (MLMD) to generate trackable artifacts throughout your development process. From your training data ingestion and any metadata around the execution of the individual steps, to exporting your model with evaluation metrics and accompanying context such as changelists and owners, the MLMD API can create a trace of all the intermediate components of your ML workflow. This ongoing monitoring of progress that MLMD provides helps identify security risks or complications in training.
Model Cards
As you deploy your model, you could also accompany its deployment with a
Model Card—a document structured in a format that serves as an opportunity for you to communicate the values and limitations of your model. Model Cards could enable developers, policy makers, and users to understand aspects about trained models, contributing to the larger developer ecosystem with added clarity and explainability so that ML is less likely to be used in contexts for which it is inappropriate. Based on a framework proposed in an
academic paper by Google researchers published in early 2019, Model Cards have since been released with
Google Cloud Vision API models, including their Object and Face Detection APIs, as well as a number of open source models.
Today, you can get inspiration from the paper and
existing examples to develop your own Model Card. In the next two months, we plan to combine ML Metadata and the Model Card framework to provide developers with a more automated way of creating these important artifacts. Stay tuned for our Model Cards Toolkit, which we will add to the Responsible AI Toolkit collection.
It’s important to note that while Responsible AI in the ML workflow is a critical factor, building products with AI ethics in mind is a combination of technical, product, policy, process, and cultural factors. These concerns are multifaceted and fundamentally
sociotechnical. Issues of fairness, for example, can often be traced back to histories of bias in the world’s underlying systems. As such, proactive AI responsibility efforts not only require measurement and modelling adjustments, but also policy and design changes to provide transparency, rigorous review processes, and a diversity of decision makers who can bring in multiple perspectives.
This is why many of the tools and resources we covered in this post are founded in the sociotechnical research work we do at Google. Without such a robust foundation, these ML and AI models are bound to be ineffective in benefiting society as they could erroneously become integrated into the entanglements of decision-making systems. Adopting a cross-cultural perspective, grounding our work in human-centric design, extending transparency towards all regardless of expertise, and operationalizing our learnings into practices—these are some of the steps we take to responsibly build AI.
We understand Responsible AI is an evolving space that is critical, which is why we are hopeful when we see how the TensorFlow community is thinking about the issues we’ve discussed—and more importantly, when the community takes action. In our latest
Dev Post Challenge, we asked the community to build something great with TensorFlow incorporating AI Principles. The
winning submissions explored areas of fairness, privacy, and interpretability, and showed us that Responsible AI tools should be well integrated into TensorFlow ecosystem libraries. We will be focusing on this to ensure these tools are easily accessible.
As you begin your next TensorFlow project, we encourage you to use the tools above, and to provide us feedback at
tf-responsible-ai@google.com. Share your learnings with us, and we’ll continue to do the same, so that we can together build products that truly work well for everyone.






