https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEgJurdq1EtyB-O_OnJxklEWsWg2SGWUsaE7A7lYzkahS2PpgV3YY5qie6AoFztS9H62xHE-2KEEWsevDS4MJqAfDiHEkTQM8ynbdx1IdosFQX93fXjeKosO-2sZr1wrhXRS-uGOnK7JWtU/s1600/tensorflowcloud.png
TensorFlow 2 MLPerf submissions demonstrate best-in-class performance on Google Cloud
Posted by Pankaj Kanwar, Peter Brandt, and Zongwei Zhou from the TensorFlow Team
MLPerf, the industry standard for measuring machine learning performance, has released the
latest benchmark results from the MLPerf Training v0.7 round. We’re happy to share that Google’s submissions demonstrate leading top-line performance (fastest time to reach target quality), with the ability to scale up to 4,000+ accelerators and the flexibility of the TensorFlow 2 developer experience on Google Cloud.

In this blog post, we’ll explore the TensorFlow 2 MLPerf submissions, which showcase how enterprises can run valuable workloads that MLPerf represents on cutting-edge ML accelerators in Google Cloud, including widely deployed generations of GPUs and Cloud TPUs. Our accompanying
blog post highlights our record-setting large-scale training results.
TensorFlow 2: designed for performance and usability
At the TensorFlow Developer Summit earlier this year, we highlighted that TensorFlow 2 would emphasize usability and real-world performance. When competing to win benchmarks, engineers have often relied on low-level API calls and hardware-specific code that may not be practical in everyday enterprise settings. With TensorFlow 2, we aim to provide high performance out of the box with more straightforward code, avoiding the significant issues that low-level optimizations can cause with respect to code reusability, code health, and engineering productivity.
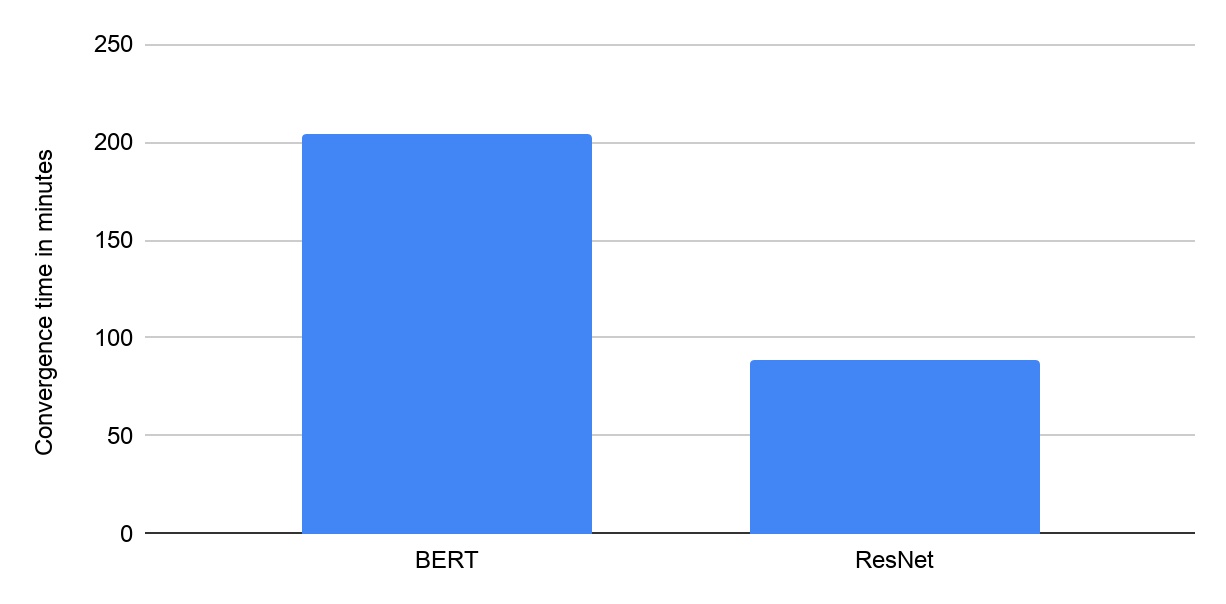 |
| Time to converge (in minutes) using Google Cloud VMs with 8 NVIDIA V100 GPUs from Google’s MLPerf Training v0.7 Closed submission in the “Available” category. |
TensorFlow’s Keras APIs (see this collection of
guides) offer usability and portability across a wide array of hardware architectures. For example, model developers can use the
Keras mixed precision API and
Distribution Strategy API to enable the same codebase to run on multiple hardware platforms with minimal friction. Google’s MLPerf submissions in the Available-in-Cloud category were implemented using these APIs. These submissions demonstrate that near-identical TensorFlow code written using high level Keras APIs can deliver high performance across the two leading widely-available ML accelerator platforms in the industry: NVIDIA’s V100 GPUs and Google’s Cloud TPU v3 Pods.
Note: All results shown in the charts are retrieved from www.mlperf.org on July 29, 2020. MLPerf name and logo are trademarks. See www.mlperf.org for more information. Results shown: 0.7-1 and 0.7-2.
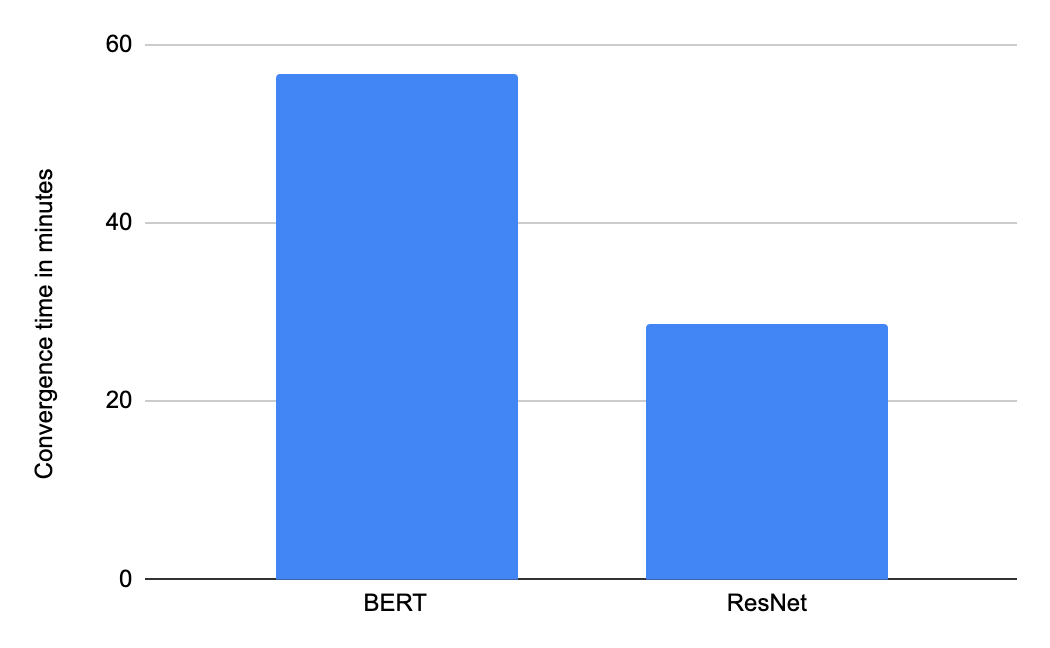 |
| Time to convergence (in minutes) using Google Cloud TPU v3 Pod slices containing 16 TPU chips from Google’s MLPerf Training v0.7 Closed submission in the “Available” category. |
Looking under the hood: performance enhancements with XLA
Google’s submissions on GPUs and on Cloud TPU Pods leverage the
XLA compiler to optimize TensorFlow performance. XLA is a core part of the TPU compiler stack, and it can optionally be enabled for GPU. XLA is a graph-based just-in-time compiler that performs a variety of different types of whole-program optimizations, including extensive
fusion of ML operations.
Operator fusion reduces the memory capacity and bandwidth requirements for ML models. Furthermore, fusion reduces the launch overhead of operations, particularly on GPUs. Overall, XLA optimizations are general, portable, interoperate well with cuDNN and cuBLAS libraries, and can often provide a compelling alternative to writing low-level kernels by hand.
Google’s TensorFlow 2 submissions in the Available-in-Cloud category use the @tf.function API introduced in TensorFlow 2.0. The @tf.function API offers a simple way to
enable XLA selectively, providing fine-grained control over exactly which functions will be compiled.
The performance improvements delivered by XLA are impressive: on a Google Cloud VM with 8 Volta V100 GPUs attached (each with 16 GB of GPU memory), XLA boosts
BERT training throughput from 23.1 sequences per second to 168 sequences per second, a ~7x improvement. XLA also increases the runnable batch size per GPU by 5X. Reduced memory usage by XLA also enables advanced training techniques such as gradient accumulation.
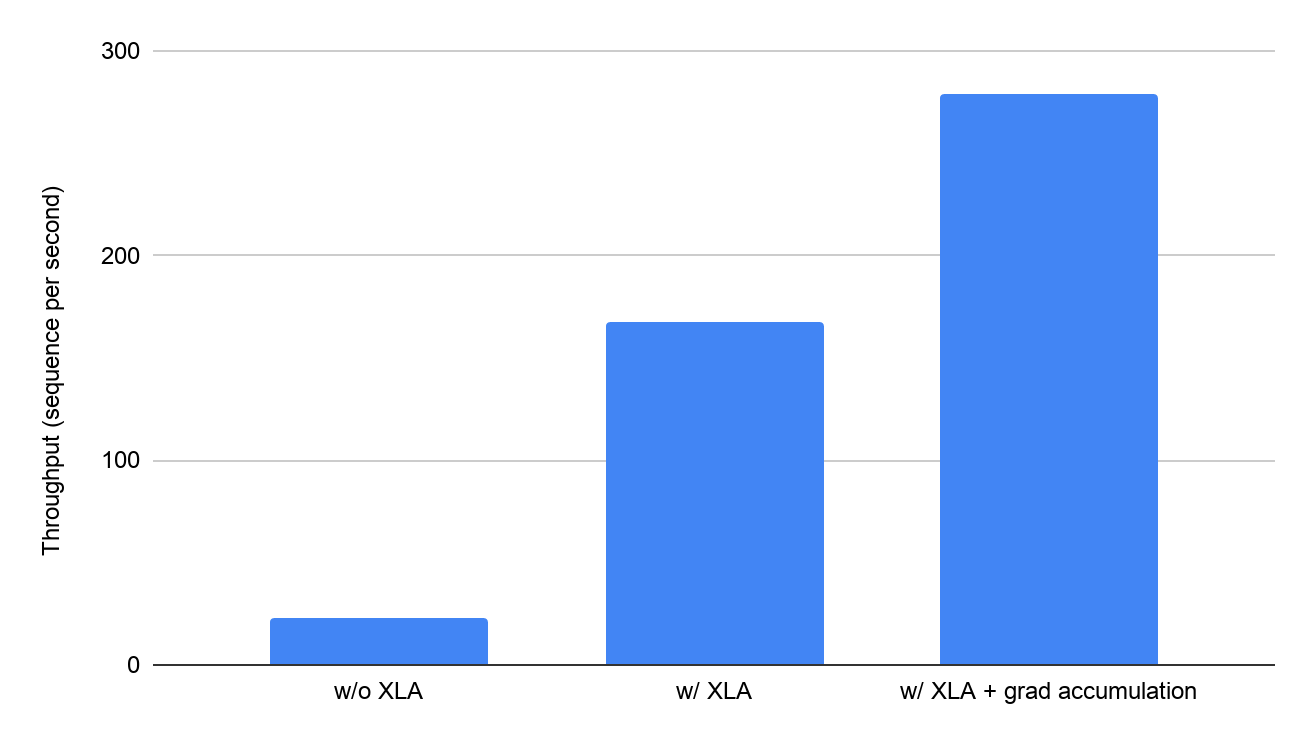 |
| Impact of enabling XLA (in minutes) on the BERT model using 8 V100 GPUs on Google Cloud as demonstrated by Google’s MLPerf Training 0.7 Closed submission compared to unverified MLPerf results on the same system with optimization(s) disabled. |
State-of-the-art accelerators on Google Cloud
Google Cloud is the only public-cloud platform that provides access to both state-of-the-art
GPUs and
Cloud TPUs, which allows AI researchers and data scientists the freedom to choose the right hardware for every task.
Cutting-edge models such as
BERT, which are extensively used within Google and industry-wide for a variety of natural language processing tasks, can now be trained on Google Cloud leveraging the same infrastructure that is used for training internal workloads within Google. Using Google Cloud, you can train BERT for 3 million sequences on a Cloud TPU v3 Pod slice with 16 TPU chips in under an hour at a total cost of under $32.
Conclusion
Google's MLPerf 0.7 Training submissions showcase the performance, usability, and portability of TensorFlow 2 across state-of-the-art ML accelerator hardware. Get started today with the usability and power of TensorFlow 2 on
Google Cloud GPUs,
Google Cloud TPUs, and
TensorFlow Enterprise with
Google Cloud Deep Learning VMs.
Acknowledgements
The MLPerf submission on GPUs is the result of a close collaboration with NVIDIA. We’d like to thank all engineers at NVIDIA who helped us with this submission.






