https://blog.tensorflow.org/2020/08/introducing-semantic-reactor-explore-nlp-sheets.html?hl=vi
https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEhG-602_CZahqVVdo4ONtCzkvmZxISKj5LkWKHhJFLGAdmUf5xXL72sDqEsjlY36CGVPVehroqFwdfbeGIM9cxJj-X9YcwtU3Qi-USK86obGgmWgqbVI2iAwukWn8uIWoKDAFG0YgdvOwM/s1600/semantic_reactor.gif
Posted by Dale Markowitz, Applied AI Engineer
Editor’s note: An earlier version of this article was published on Dale’s blog.
Machine learning can be tricky, so being able to prototype ML apps quickly is a boon. If you’re building a language-powered app -- like a video game with characters players can talk to or a customer service bot -- the Semantic Reactor is a tool that will help you do just that.
The
Semantic Reactor is a new plugin for
Google Sheets that lets you run natural language understanding (NLU) models (variations the
Universal Sentence Encoder) on your own data, right from a spreadsheet.
In this post, I’ll show you how to work with the tool and the NLU models it uses, but first, how does NLP actually work? What’s going on under the hood? (Want to skip straight to the tool? Scrolling to the next section.)
Understanding Embeddings
What are Word Embeddings?
One simple (but powerful) technique for building natural-language-powered software is to use “embeddings.”
In machine learning, embeddings are a learned way of representing data in space (i.e. points plotted on an n-dimensional grid) such that the distances between points are meaningful. Word vectors are one popular example:
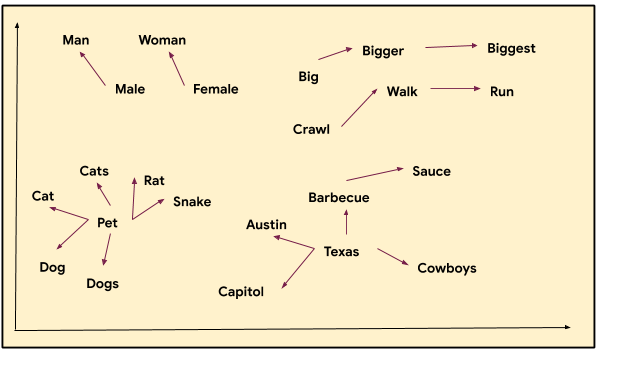
The picture above is a rough visual example of how words can be closer or further away from each other. Note that the words “Austin,” “Texas,” and “barbecue” have a close relationship with each other, as do “pet” and “dog,” and “walk” and “run.” Each word is represented by a set of coordinates (or a vector) and are placed on a graph where we can see relationships. For instance, we can see that the word “rat” is close to both “pet” and also “cat”.
Where do these numbers come from? They’re learned by a machine learning model through many bits of conversational and language data. By showing all those examples, the model learns which words tend to occur in the same spots in sentences.
Consider these two sentences:
- “My mother gave birth to a son.”
- “My mother gave birth to a daughter.”
Because the words “daughter” and “son” are often used in similar contexts, the model will learn that they should be represented close to each other in space. Word embeddings are useful in natural language processing. They can be used to find synonyms (“semantic similarity”), to solve analogies, or as a preprocessing step for a more complicated model. You can quickly train your own basic word embeddings with TensorFlow
here.
What are Sentence Embeddings?
It turns out that entire sentences (and even short paragraphs) can be effectively embedded in space too, using a type of model called a
universal sentence encoder. Using sentence embeddings, we can figure out if two sentences are similar. This is useful, for example, if you’re building a chatbot and want to know if a question a user asked (i.e. “When will you wake me up?”) is semantically similar to a question you – the chatbot programmer – have anticipated and written a response to (“What time is my alarm?”).
Semantic Reactor: Prototype using NLP in a Google Sheet
Alright, now onto the fun part: Building things! There are three NLP models available in the Semantic Reactor:
- Local - A small TensorFlow.js version of the Universal Sentence Encoder that can run entirely within a webpage.
- Basic Online - A full sized, general-use version of the Universal Sentence Encoder.
- Multilingual Online - A full-sized Universal Sentence Encoder model trained on question/answer pairs in 16 languages.
Each model offers two ranking methods:
- Semantic Similarity: How similar are two blocks of text?
Great for applications where you can anticipate what users might ask, like an FAQ bot. (Many customer service bots use semantic similarity to help deliver good answers to users.)
- Input / Response: How good of a response is one block of text to another?
Useful for when you have a large, and constantly changing, set of texts and you don’t know what users might ask. For instance, Talk to Books, a semantic search tool for a regularly updated collection of 100,000 books, uses input / response.
You can use the Semantic Reactor to test a response list against each model and ranking method. Sometimes it takes a good bit of experimenting before you get your response list and model selection to one you think will work for your application. The good news is that doing that work in a Google Sheet makes it fast and easy.
Once you have your response list, model selection and ranking method decided on, you can then begin writing code, and if you want to keep all operations within a website or on device (without requiring online API calls), you can use the newly updated
TensorFlow.js model.
As mentioned, there are lots of great uses for NLU tech, and more interesting applications come out almost everyday. Every digital assistant, customer service bot, and search engine is likely using some flavor of machine learning. Smart Reply and Smart Compose in Gmail are two well-used features that make good use of semantic tech.
However, it’s fun and helpful to play with the tech within applications where the quality demands aren’t so high, where failure is okay and even entertaining. To that end, we’ve used the same tech that’s within the Semantic Reactor to create a couple of example games.
Semantris is a word association game that uses the input-response ranking method, and
The Mystery of the Three Bots uses semantic similarity.
Playing those two games, and finding out where they work and where they don’t, might give you ideas on what experiences you might create.
 |
| Semantris, a word-association game powered by word embeddings. |
One of the coolest applications of this tech comes from
Anna Kipnis, a former game designer at Double Fine who now works with Stadia. She used Semantic Reactor to prototype a video game world that infers how the environment should react to player inputs using ML. Check out our conversation
here.
In Anna’s game, players interact with a virtual fox by asking any question they think of:
- “Fox, can I have some coffee?”
Then, using Semantic ML, the game engine (or the
utility system) considers all of the possible ways the game might respond:
- “Fox turns on lights.“
- “Fox turns on radio.“
- “Fox move to you.“
- “Fox brings you mug.“
Using a sentence encoder model, the game decides what the best response is and executes it (in this case, the best response is “Fox brings you a mug,” so the game animates the Fox bringing you a mug). If that sounds a little abstract, definitely watch the video linked above.
Let’s see how you might build something like Anna’s game with Semantic Reactor (for all the nitty gritties of the fox demo, check out her
original post).
First, create a new Google sheet and write some sentences in the first column. I put these sentences in the first column of my Google sheet:
- I grab a ball
- I go to you
- I play with a ball
- I go to school.
- I go to the mug.
- I bring you the mug.
- I turn on music.
- I take a nap.
- I go for a hike.
- I tell you a secret.
- I snuggle with you.
- I ask for a belly rub.
- I send a text.
- I answer the phone.
- I make a sandwich.
- I drink some water.
- I play a board game.
- I do some coding.
You’ll have to use your imagination here and think of these “actions” that a potential character (e.g. a chatbot or an actor in a video game) might take.
Once you’ve applied for and been given access to Semantic Reactor, you’ll be able to enable it by clicking on “Add-ons -> Semantic Reactor -> Start”.
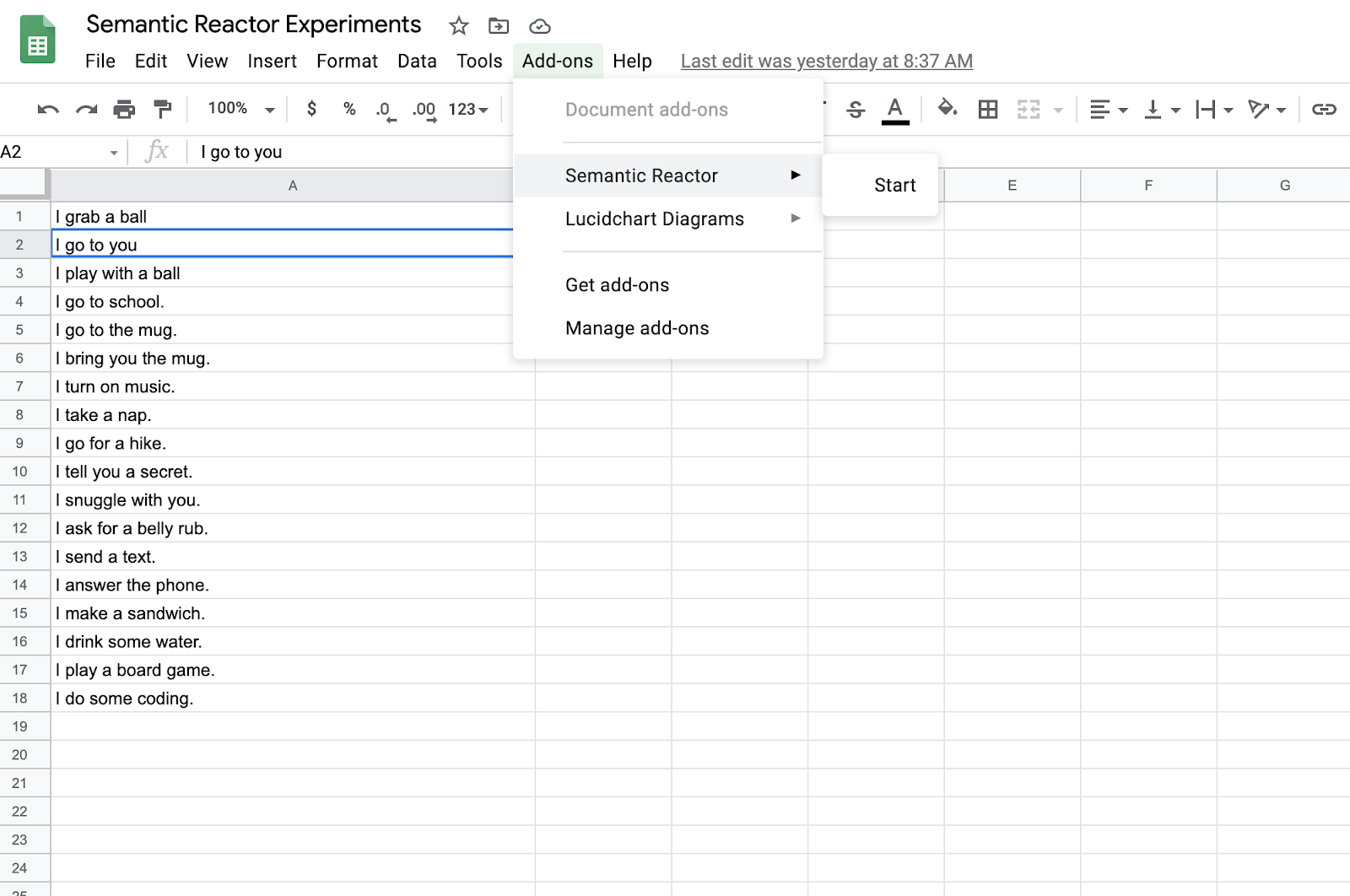
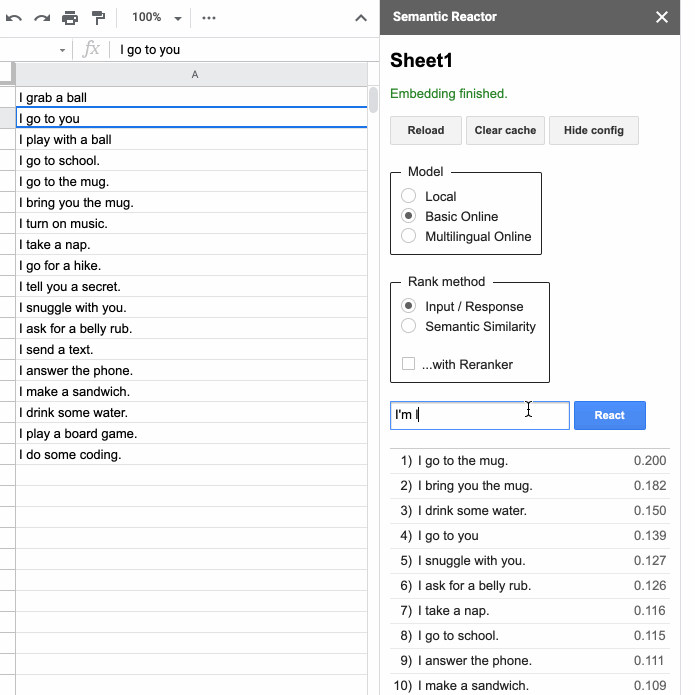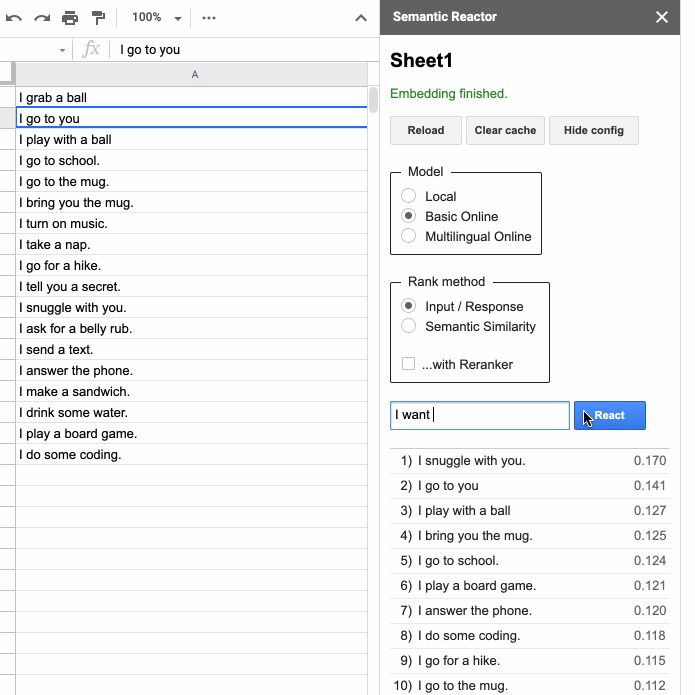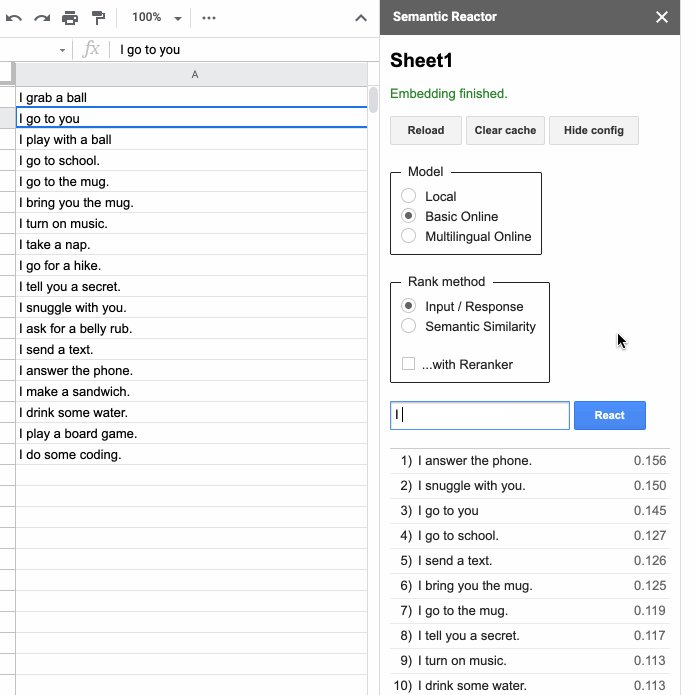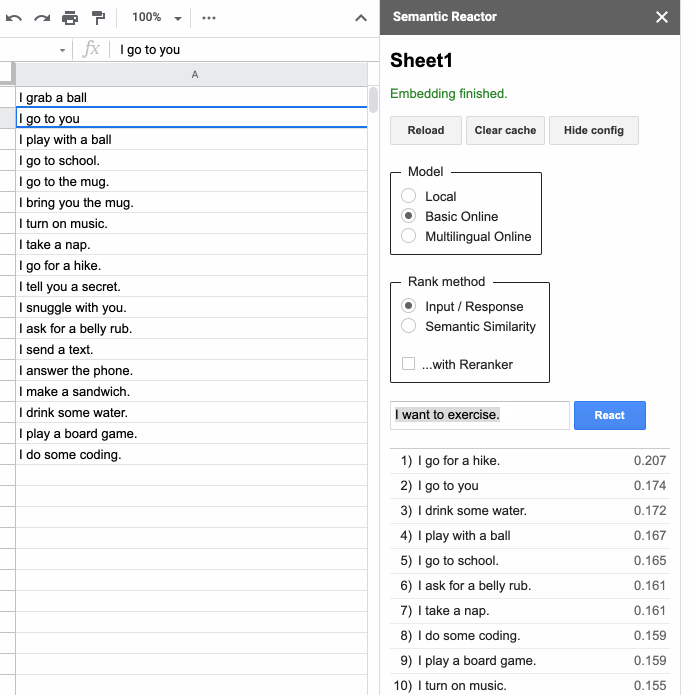
Clicking “Start” will open a panel that allows you to type in an input and hit “React”:
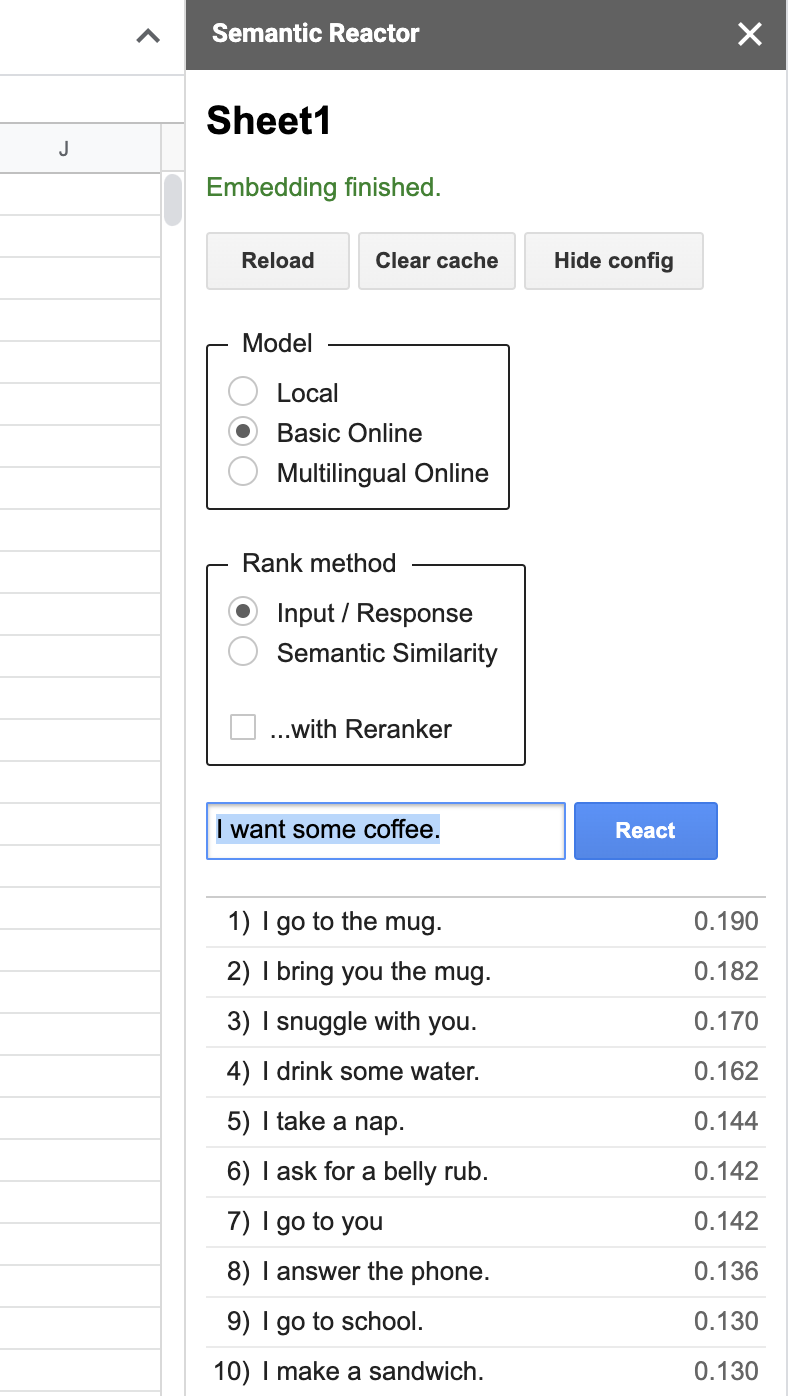
When you hit “React”, Semantic Reactor uses a model to embed all of the responses you’ve written in that first column, calculate a score (how good a response is this sentence to the query?), and sort the results. For example, when my input was “I want some coffee,” the top ranked responses from my spreadsheet were, “I go to the mug” and “I bring you the mug.” You’ll also notice that there are two different ways to rank sentences using this tool: “Input/Response” and “Semantic Similarity.” As the name implies, the former ranks sentences by how good they are as responses to the given query, whereas “Semantic Similarity” simply rates how similar the sentences are to the query.
From Spreadsheet to Code with TensorFlow.js
Underneath the hood, Semantic Reactor is powered by the open-source TensorFlow.js models found
here.
Let’s take a look at how to use those models in JavaScript, so that you can convert your spreadsheet prototype into a working app.
1 - Create a new Node project and install the module:
npm init
npm install @tensorflow/tfjs @tensorflow-models/universal-sentence-encoder
2 - Create a new file (use_demo.js) and require the library:
require('@tensorflow/tfjs');
const encoder = require('@tensorflow-models/universal-sentence-encoder');
3 - Load the model:
const model = await encoder.loadQnA();
4 - Encode your sentences and query:
const input = {
queries: \["I want some coffee"\],
responses: \[
"I grab a ball",
"I go to you",
"I play with a ball",
"I go to school.",
"I go to the mug.",
"I bring you the mug."
\]
};
const embeddings = await model.embed(input);
5 - Voila! You’ve transformed your responses and query into vectors. Unfortunately, vectors are just points in space. To rank the responses, you’ll want to compute the distance between those points (you can do this by computing the
dot product, which gives you the squared
Euclidean distance between points):
//zipWith :: (a -> b -> c) -> \[a\] -> \[b\] -> \[c\]
const zipWith =
(f, xs, ys) => {
const ny = ys.length;
return (xs.length <= ny ? xs : xs.slice(0, ny))
.map((x, i) => f(x, ys\[i\]));
}
// Calculate the dot product of two vector arrays.
const dotProduct = (xs, ys) => {
const sum = xs => xs ? xs.reduce((a, b) => a + b, 0) : undefined;
return xs.length === ys.length ?
sum(zipWith((a, b) => a * b, xs, ys))
: undefined;
}
If you run this code, you should see output like:
[
{ response: 'I grab a ball', score: 10.788130270345432 },
{ response: 'I go to you', score: 11.597091717283469 },
{ response: 'I play with a ball', score: 9.346379028479209 },
{ response: 'I go to school.', score: 10.130473646521292 },
{ response: 'I go to the mug.', score: 12.475453722603106 },
{ response: 'I bring you the mug.', score: 13.229019199245684 }
]
Check out the full code sample
here.
And that’s it–that’s how you go from a Semantic ML spreadsheet to code fast!
An earlier version of this post was published at
https://daleonai.com/semantic-ml.







