https://blog.tensorflow.org/2020/09/introduction-to-tflite-on-device-recommendation.html?hl=th
https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEj5BMVPH54Ew1ruG_-Aj__N4daZwh8pPLmgtwBLPDyF8Fu0tBFDE4X7FT1In-nP_rEL3-vb6X7ZLYTcOf9pQK4rCGkuebq33Q0978WjA3NXAr76IldId7K_hXcKJoF7QzEiblcDSpNLY_A/s1600/model.png
Posted by Ellie Zhou, Tian Lin, Cong Li, Shuangfeng Li and Sushant Prakash
Introduction & Motivation
We are excited to
open source an end-to-end solution for TFLite on-device recommendation tasks. We invite developers to build on-device models using our solution that provides personalized, low-latency and high-quality recommendations, while preserving users’ privacy.
Generating personalized high-quality recommendations is crucial to many real-world applications, such as music, videos, merchandise, apps, news, etc. Currently, a typical recommender system is fully constructed at the server side, including collecting user activity logs, training recommendation models using the collected logs, and serving recommendation models.
While purely server-based recommender systems have been proven to be powerful, we explore and showcase a more lightweight approach to serve an recommendation model by deploying it on device. We demonstrate that such an on-device recommendation solution enjoys low latency inference that is orders of magnitude faster than server-side models. It enables user experiences that cannot be achieved by traditional server-based recommender systems, such as updating rankings and UI responding to every user tap or interaction.
Moreover, on-device model inference respects user privacy without sending user data to a server to do predictions, instead keeping all needed data on the device. It is possible to train the model on public data or via an existing proxy dataset to avoid collecting user data for each new use case, which is demonstrated in our solution. For on-device training, we would refer interested readers to
Federated Learning or
TFLite model personalization as an alternative.
Please find
our solution includes the following components:
- Source code that constructs and trains high quality personalized recommendation models for on-device scenarios.
- A movie recommendation demo app that runs the model on device.
- We also provided source code for preparing training examples and a pretrained model in Github repo.
Model
Recommendation problems are typically formulated as future-activity prediction problems. A recommendation model is therefore trained to predict the user’s future activities, given their previous activities happened before. Our published model is constructed with the following architecture:
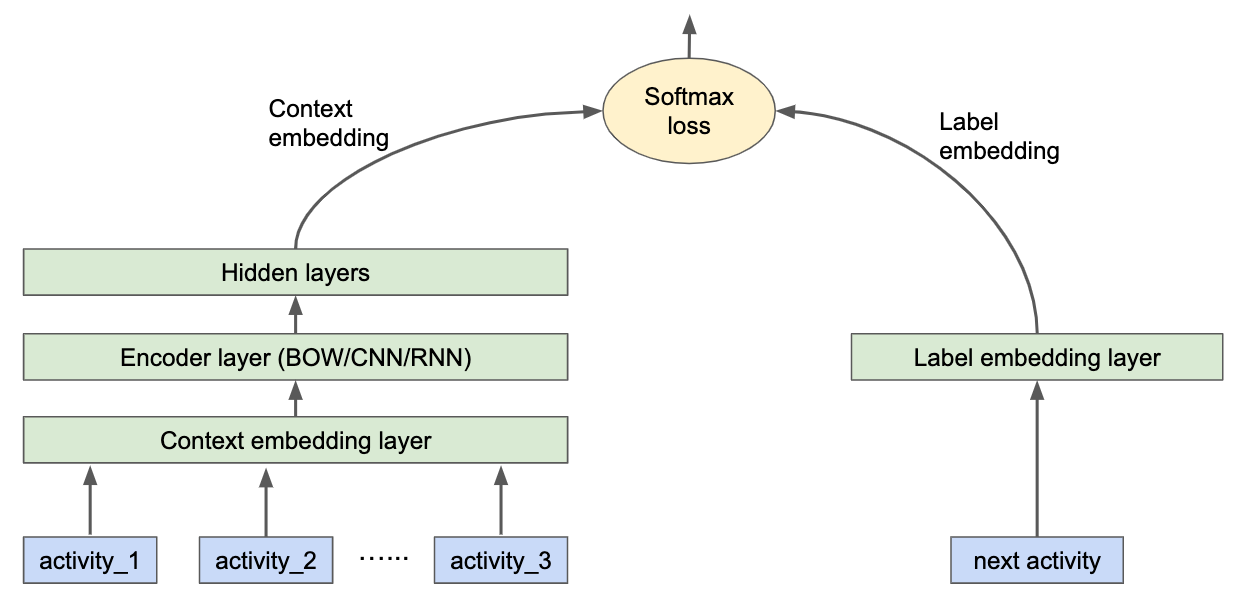
At the context side, each user activity, such as a movie watch, is embedded into an embedding vector. Embedding vectors from past user activities are aggregated by the encoder to generate the context embedding. We support three different types of encoders:
- Bag-of-Words: activity embeddings are simply averaged.
- CNN: 1-D convolution is applied to activity embeddings followed by max-pooling.
- RNN: LSTM is applied to activity embeddings.
At the label side, the label item, such as the next movie that the user watched or is interested in, is considered as “positive”, while all other items (e.g. all other movies the user didn’t watch) are considered as “negative” through negative sampling. Both positive and negative items are embedded, and the dot product combines the context embedding to produce logits and feed to the loss of softmax cross entropy. Other modeling situations where labels are not binary will be supported in future. After training, the model can be exported and deployed on device for serving. We take the top-K recommendations which are simply the K-highest logits between the context embedding and all label embeddings.

Example
To demonstrate the quality and the user experience of an on-device recommendation model, we trained an example movie recommendation model using the
MovieLens dataset and developed a demo app. (Both the model and the app are for demonstration purposes only.) The MovieLens 1M dataset contains ratings from 6039 users across 3951 movies, with each user rating only a small subset of movies. For simplification, we ignore the rating score, and train a model to predict which movies will get rated given N previous movies, where N is referred to as the
history length.
The model’s performance on all the three encoders with different history lengths is shown below:

We can find that all models achieve high recall metric, while CNN and RNN models usually perform better for a longer history length. In practice, developers may conduct experiments with different history lengths and encoder types, and find out the best for the specific recommendation problem they want to solve.
We want to highlight that all the published on-device models have very low inference latency. For example, for the CNN model with N=10 which we integrated with our demo app, the inference latency on Pixel 4 phones is only
0.05ms in our experiment. As stated in the introduction, such a low latency allows developing immediate and smooth response to every user interaction on the phone, as is demonstrated in our app:

Future Work
We welcome different kinds of extensions and contributions. The currently open sourced model does not support more than one feature column to represent each user’s activity. In the
next version, we are going to support multiple features as the activity representation. Moreover, we are planning more advanced user encoders, such as Transformer-based (Vaswani, A., et al., 2017).
References
Vaswani, A., et al. "Attention is all you need. arXiv 2017." arXiv preprint arXiv:1706.03762 (2017),
https://arxiv.org/abs/1706.03762.






