Posted by Summer Misherghi and Thomas Greenspan, Software Engineers, Google Research
Last December, we open-sourced Fairness Indicators, a platform that enables sliced evaluation of machine learning model performance. This type of responsible evaluation is a crucial first step toward avoiding bias as it allows us to determine how our models are working for a wide variety of users. When we do identify that our model underperforms on certain slices of our data, we need a strategy to mitigate this to avoid creating or reinforcing unfair bias, in line with Google’s AI Principles.
Today, we’re announcing MinDiff, a technique for addressing unfair bias in machine learning models. Given two slices of data, MinDiff works by penalizing your model for differences in the distributions of scores between the two sets. As the model trains, it will try to minimize the penalty by bringing the distributions closer together. MinDiff is the first in what will ultimately be a larger Model Remediation Library of techniques, each suitable for different use cases. To learn about the research and theory behind MinDiff, please see our post on the Google AI Blog.
MinDiff Walkthrough
You can follow along and run the code yourself in this MinDiff notebook. In this walkthrough, we’ll emphasize important points in the notebook, while providing context on fairness evaluation and remediation.
In this example, we are training a text classifier to identify written content that could be considered “toxic.” For this task, our baseline model will be a simple Keras sequential model pre-trained on the Civil Comments dataset. Since this text classifier could be used to automatically moderate forums on the internet (for example, to flag potentially toxic comments), we want to ensure that it works well for everyone. You can read more about how fairness problems can arise in automated content moderation in this blog post.
To attempt to mitigate potential fairness concerns, we will:
Our purpose is to demonstrate usage of the MinDiff technique for you with a minimal workflow, not to lay out a complete approach to fairness in machine learning. Our evaluation will only focus on one sensitive category and a single metric. We also don’t address potential shortcomings in the dataset, nor tune our configurations.
In a production setting, you would want to approach each of these with more rigor. For example:
For the purpose of this blog post, we’ll skip building and training our baseline model, and jump right to evaluating its performance. We’ve used some utility functions to compute our metrics and we’re ready to visualize evaluation results (See “Render Evaluation Results” in the notebook):
widget_view.render_fairness_indicator(eval_result) 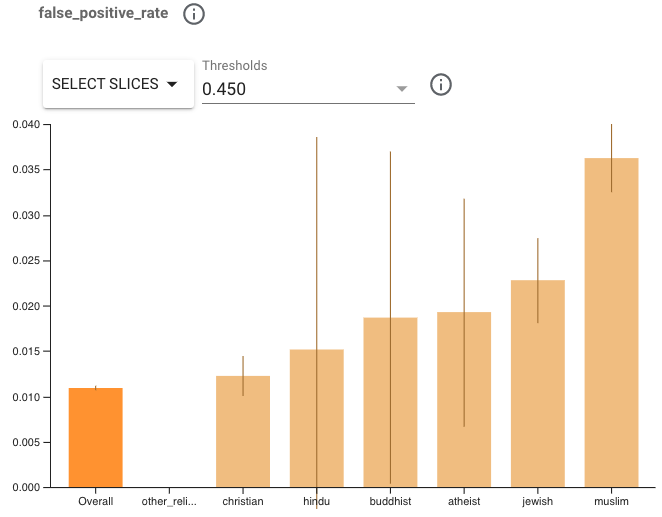
Let’s look at the evaluation results. Try selecting the metric false positive rate (FPR) with threshold 0.450. We can see that the model does not perform as well for some religious groups as for others, displaying a much higher FPR. Note the wide confidence intervals on some groups because they have too few examples. This makes it difficult to say with certainty that there is a significant difference in performance for these slices. We may want to collect more examples to address this issue. We can, however, attempt to apply MinDiff for the two groups that we are confident are underperforming.
We’ve chosen to focus on FPR, because a higher FPR means that comments referencing these identity groups are more likely to be incorrectly flagged as toxic. This could lead to inequitable outcomes for users engaging in dialogue about religion, but note that disparities in other metrics can lead to other types of harm.
Now, we’ll try to improve the FPR for religious groups for which our model underperforms. We’ll attempt to do so using MinDiff, a remediation technique that seeks to balance error rates across slices of your data by penalizing disparities in performance during training. When we apply MinDiff, model performance may degrade slightly on other slices. As such, our goals with MinDiff will be to improve performance for underperforming groups, while sustaining strong performance for other groups and overall.
To use MinDiff, we create two additional data splits:
It’s important to have sufficient examples belonging to the underperforming classes. Based on your model architecture, data distribution, and MinDiff configuration, the amount of data needed can vary significantly. In past applications, we have seen MinDiff work well with at least 5,000 examples in each data split.
In our case, the groups in the minority splits have example quantities of 9,688 and 3,906. Note the class imbalances in the dataset; in practice, this could be cause for concern, but we won’t seek to address them in this notebook since our intention is just to demonstrate MinDiff.
We select only negative examples for these groups, so that MinDiff can optimize on getting these examples right. It may seem counterintuitive to carve out sets of ground truth negative examples if we’re primarily concerned with disparities in false positive rate, but remember that a false positive prediction is a ground truth negative example that’s incorrectly classified as positive, which is the issue we’re trying to address.
To prepare our data splits, we create masks for the sensitive & non-sensitive groups:
minority_mask = data_train.religion.apply(
lambda x: any(religion in x for religion in ('jewish', 'muslim')))
majority_mask = data_train.religion.apply(
lambda x: x == "['christian']") Next, we select negative examples, so MinDiff will be able to reduce FPR for sensitive groups:
true_negative_mask = data_train['toxicity'] == 0
data_train_main = copy.copy(data_train)
data_train_sensitive = (
data_train[minority_mask & true_negative_mask])
data_train_nonsensitive = (
data_train[majority_mask & true_negative_mask])To start training with MinDiff, we need to convert our data to TensorFlow Datasets (not shown here -- see “Create MinDiff Datasets” in the notebook for details). Don’t forget to batch your data for training. In our case, we set the batch sizes to the same value as the original dataset but this is not a requirement and in practice should be tuned.
dataset_train_sensitive = dataset_train_sensitive.batch(BATCH_SIZE)
dataset_train_nonsensitive = (
dataset_train_nonsensitive.batch(BATCH_SIZE))
Once we have prepared our three datasets, we merge them into one MinDiff dataset using a util function provided in the library.
min_diff_dataset = md.keras.utils.pack_min_diff_data(
dataset_train_main,
dataset_train_sensitive,
dataset_train_nonsensitive) To train with MinDiff, simply take the original model and wrap it in a MinDiffModel with a corresponding `loss` and `loss_weight`. We are using 1.5 as the default `loss_weight`, but this is a parameter that needs to be tuned for your use case, since it depends on your model and product requirements. You should experiment with changing the value to see how it impacts the model, noting that increasing it pushes the performance of the minority and majority groups closer together but may come with more pronounced tradeoffs.
As specified above, we create the original model, and wrap it in a MinDiffModel. We pass in one of the MinDiff losses and use a moderately high weight of 1.5.
original_model = ... # Same structure as used for baseline model.
min_diff_loss = md.losses.MMDLoss()
min_diff_weight = 1.5
min_diff_model = md.keras.MinDiffModel(
original_model, min_diff_loss, min_diff_weight) After wrapping the original model, we compile the model as usual. This means using the same loss as for the baseline model:
optimizer = tf.keras.optimizers.Adam(learning_rate=0.001)
loss = tf.keras.losses.BinaryCrossentropy()
min_diff_model.compile(
optimizer=optimizer, loss=loss, metrics=['accuracy']) We fit the model to train on the MinDiff dataset, and save the original model to evaluate (see API documentation for details on why we don’t save the MinDiff model).
min_diff_model.fit(min_diff_dataset, epochs=20)
min_diff_model.save_original_model(
min_diff_model_location, save_format='tf') Finally, we evaluate the new results.
min_diff_eval_subdir = 'eval_results_min_diff'
min_diff_eval_result = util.get_eval_results(
min_diff_model_location, base_dir, min_diff_eval_subdir,
validate_tfrecord_file, slice_selection='religion') To ensure we evaluate a new model correctly, we need to select a threshold the same way that we would the baseline model. In a production setting, this would mean ensuring that evaluation metrics meet launch standards. In our case, we will pick the threshold that results in a similar overall FPR to the baseline model. This threshold may be different from the one you selected for the baseline model. Try selecting false positive rate with threshold 0.400. (Note that the subgroups with very low quantity examples have very wide confidence range intervals and don’t have predictable results.)
widget_view.render_fairness_indicator(min_diff_eval_result) 
Note: The scale of the y-axis has changed from .04 in the graph for the baseline model to .02 for our MinDiff model
Reviewing these results, you may notice that the FPRs for our target groups have improved. The gap between our lowest performing group and the majority group has improved from .024 to .006. Given the improvements we’ve observed and the continued strong performance for the majority group, we’ve satisfied both of our goals. Depending on the product, further improvements may be necessary, but this approach has gotten our model one step closer to performing equitably for all users.
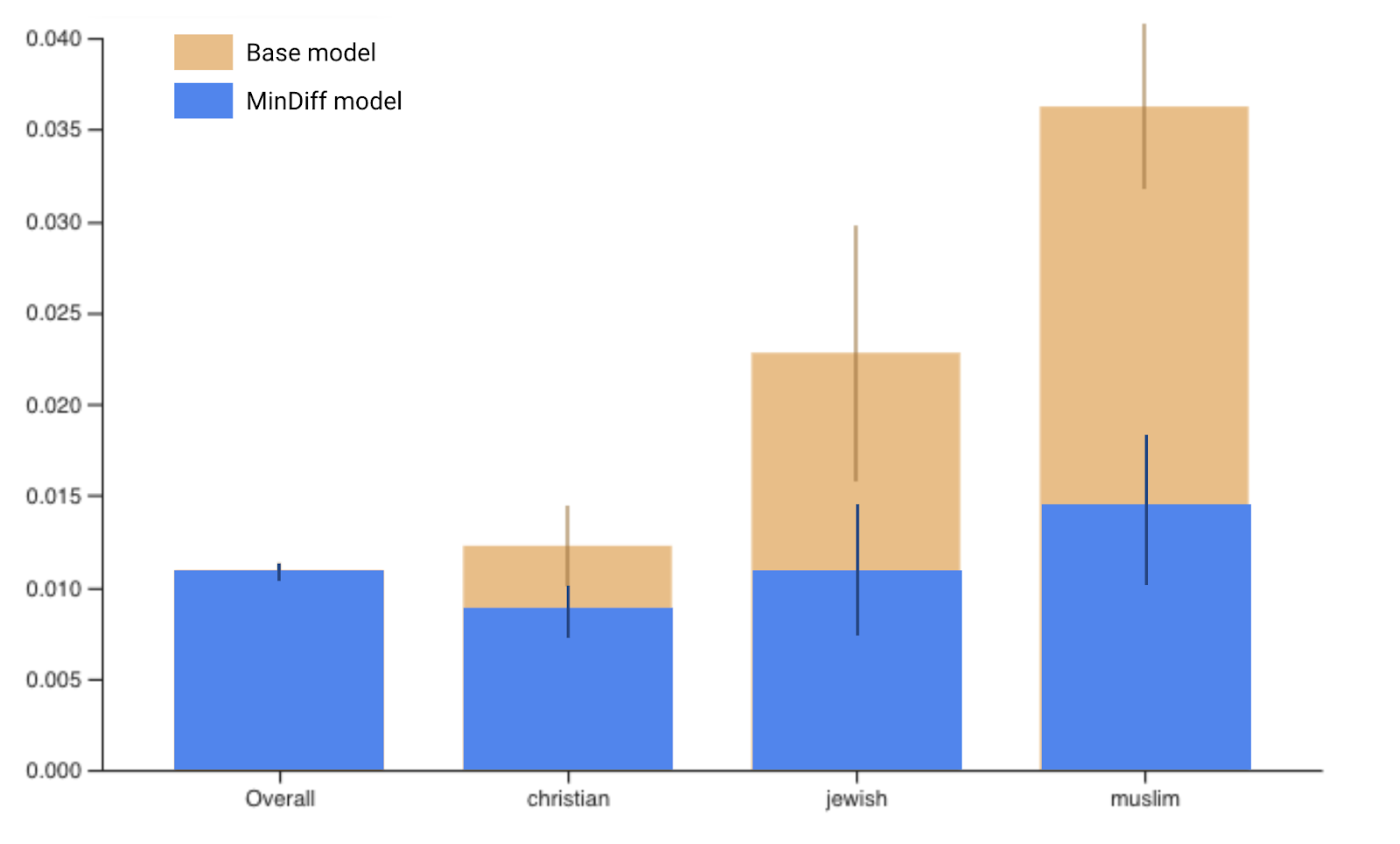
To get a better sense of scale, we superimposed the MinDiff model on top of the base model.
You can get started with MinDiff by visiting the MinDiff page on tensorflow.org. More information about the research behind MinDiff is available in our post on the Google AI Blog. You can also learn more about evaluating for fairness in this guide.
Acknowledgements
The MinDiff framework was developed in collaboration with Thomas Greenspan, Summer Misherghi, Sean O'Keefe, Christina Greer, Catherina Xu, Manasi Joshi, Dan Nanas, Nick Blumm, Jilin Chen, Zhe Zhao, James Chen, Maciej Kula, Lichan Hong, Mahesh Sathiamoorthy, and Meg Mitchell. This research effort on ML Fairness in classification was jointly led by (in alphabetical order) Alex Beutel, Ed H. Chi, Flavien Prost, Hai Qian, Jilin Chen, Shuo Chen, and Tulsee Doshi. Further, this work was pursued in collaboration with Cristos Goodrow, Christine Luu, Jonathan Bischof, Pierre Kreitmann, and Qiuwen Chen.

نومبر 16, 2020 — Posted by Summer Misherghi and Thomas Greenspan, Software Engineers, Google Research Last December, we open-sourced Fairness Indicators, a platform that enables sliced evaluation of machine learning model performance. This type of responsible evaluation is a crucial first step toward avoiding bias as it allows us to determine how our models are working for a wide variety of users. When we do id…





