Posted by Cheng Xing and Michael Broughton, Google
Training large machine learning models is a core ability for TensorFlow. Over the years, scale has become an important feature in many modern machine learning systems for NLP, image recognition, drug discovery etc. Making use of multiple machines to boost computational power and throughput has led to great advances in the field. Similarly in quantum computing and quantum machine learning, the availability of more machine resources speeds up the simulation of larger quantum states and more complex systems. In this tutorial you will walk through how to use TensorFlow and TensorFlow quantum to conduct large scale and distributed QML simulations. Running larger simulations with greater FLOP/s counts unlocks new possibilities for research that otherwise wouldn’t be possible at smaller scales. In the figure below we have outlined approximate scaling capabilities for several different hardware settings for quantum simulation.

From our experiments in the multi-worker setting, training a 23-qubit QCNN with 1,000 training examples, which corresponds to roughly 3,000 circuits simulated using full state vector simulation takes 5 minutes per epoch on a 32 node (512 vCPU) cluster, which costs a few US dollars. By comparison, the same training job on a single-worker would take roughly 4 hours per epoch. Pushing things a little bit farther, hundreds of thousands of 30-qubit circuits could be run in a few hours using more than 10,000 virtual CPUs which could have taken weeks to run in a single-worker setting. The actual performance and cost may vary depending on your cloud setup, such as VM machine type, total cluster running time, etc. Before performing larger experiments, we recommend starting with a small cluster first, like the one used in this tutorial.
The source code for this tutorial is available in the TensorFlow Quantum GitHub repository. README.md contains the quickest way to get this tutorial up and running. This tutorial will instead focus on walk through each step in detail, to help you understand the underlying concepts and integrate them with your own projects. Let’s get started!
The first step is to create the infrastructure resources in Google Cloud. If you have an existing Google Cloud environment, the exact steps might vary, due to organizational policy constraints for example. This is a guideline to the most common set of necessary steps. Note that you will be charged for Google Cloud resources you create, and here is a summary of billable resources used in this tutorial. If you are a new Google Cloud user, you are eligible for $300 in credits. If you are part of an academic institution, you may be eligible for Google Cloud research credits.
You will be running several shell commands in this tutorial. For that, you can use either a local Unix shell available on your computer or the Cloud Shell, which already contains many of the tools mentioned later.
A script automating the steps below is available in setup.sh. This section walks through every step in detail, and if this is your first time using Google Cloud, we recommend that you walk through the entire section. If you prefer to automate the Google Cloud setup process and skip this section:
setup.sh and configure parameter values inside.
./setup.sh infra.
In this tutorial, you will use a few Google Cloud products:
To get your cloud environment ready, first follow these quick start guides:
For purposes of this tutorial, you could stop the Kubernetes Engine quickstart right before the instructions for creating a cluster. In addition, install gsutil, the Cloud Storage command-line tool (if you are using Cloud Shell, gsutil is already installed):
gcloud components install gsutilFor reference, shell commands throughout the tutorial will refer to these variables. Some of them will make more sense later on in the tutorial in the context of each command.
${CLUSTER_NAME}: your preferred Kubernetes cluster name on Google Kubernetes Engine.
${PROJECT}: your Google Cloud project ID.
${NUM_NODES}: the number of VMs in your cluster.
${MACHINE_TYPE}: the machine type of VMs. This controls the amount of CPU and memory resources for each VM.
${SERVICE_ACCOUNT_NAME}: The name of both the Google Cloud IAM service account and the associated Kubernetes service account.
${ZONE}: Google Cloud zone for the Kubernetes cluster.
${BUCKET_REGION}: Google Cloud region for Google Cloud Storage bucket.
${BUCKET_NAME}: Name of the Google Cloud Storage bucket for storing training output.
owner, or all of the following roles:
container.admin
iam.serviceAccountAdmin
storage.admin
To check your roles, run:
gcloud projects get-iam-policy ${PROJECT}After you’ve completed the quickstart guides, run this command to create a Kubernetes cluster:
gcloud container clusters create ${CLUSTER_NAME} --workload-pool=${PROJECT}.svc.id.goog --num-nodes=${NUM_NODES} --machine-type=${MACHINE_TYPE} --zone=${ZONE} --preemptible
--num-nodes is the number of Compute Engine virtual machines backing your Kubernetes cluster. This is not necessarily the same as the number of worker replicas you’d like to have for your QCNN job, as Kubernetes is able to schedule multiple replicas on the same node, provided that the node has enough CPU and memory resources. If you are trying this tutorial for the first time, we recommend 2 nodes.
--machine-type specifies the VM machine type. If you are trying this tutorial for the first time, we recommend “n1-standard-2”, with 2 vCPUs and 7.5GB of memory.
--zone is the Google Cloud zone where you’d like to run your cluster (for example “us-west1-a”).
--workload-pool enables the GKE Workload Identity feature, which ties Kubernetes service accounts with Google Cloud IAM service accounts. In order to have fine-grained access control, an IAM service account is recommended to access various Google Cloud products. Here you’ll create a service account to be used by your QCNN jobs. Kubernetes service account is the mechanism to inject the credentials of this IAM service account into your worker container.
--preemptible uses Compute Engine Preemptible VMs to back the Kubernetes cluster. They are up to 80% lower in cost compared to regular VMs, with the tradeoff that a VM may be preempted at any time, which will terminate the training process. This is well-suited for short-running training sessions with large clusters.
You can then create an IAM service account:
gcloud iam service-accounts create ${SERVICE_ACCOUNT_NAME}gcloud iam service-accounts add-iam-policy-binding --role roles/iam.workloadIdentityUser --member "serviceAccount:${PROJECT}.svc.id.goog[default/${SERVICE_ACCOUNT_NAME}]" ${SERVICE_ACCOUNT_NAME}@${PROJECT}.iam.gserviceaccount.comgsutil mb -p ${PROJECT} -l ${BUCKET_REGION} -b on gs://${BUCKET_NAME}To make your Cloud Storage data accessible by your QCNN jobs, give permissions to your IAM service account:
gsutil iam ch serviceAccount:${SERVICE_ACCOUNT_NAME}@${PROJECT}.iam.gserviceaccount.com:roles/storage.admin gs://${BUCKET_NAME}
With the cloud environment set up, you can now install the necessary Kubernetes tools into the cluster. You’ll need tf-operator, a component from KubeFlow. KubeFlow is a toolkit for running machine learning workloads on Kubernetes, and tf-operator is a subcomponent which simplifies the management of TensorFlow jobs. tf-operator can be installed separately without the larger KubeFlow installation.
To install tf-operator, run:
docker pull k8s.gcr.io/kustomize/kustomize:v3.10.0
docker run k8s.gcr.io/kustomize/kustomize:v3.10.0 build "github.com/kubeflow/tf-operator.git/manifests/overlays/standalone?ref=v1.1.0" | kubectl apply -f -You can now take the QCNN code found on the TensorFlow Quantum research branch and prepare it to run in a distributed fashion. Let’s clone the source code:
git clone https://github.com/tensorflow/quantum.git && cd quantum && git checkout origin/research && cd qcnn_multiworkergit clone git@github.com:tensorflow/quantum.git && cd quantum && git checkout origin/research && cd qcnn_multiworker
The training directory contains the necessary pieces for performing distributed training of your QCNN. The combination of training/qcnn.py and common/qcnn_common.py is the same as the hybrid QCNN example in TensorFlow Quantum, but with a few feature additions:
tf.distribute.MultiWorkerMirroredStrategy.
MultiWorkerMirroredStrategy is the mechanism in TensorFlow to perform synchronized distributed training. Your existing model has been augmented for distributed training with just a few extra lines of code.
At the beginning of training/qcnn.py, we set up MultiWorkerMirroredStrategy:
strategy = tf.distribute.MultiWorkerMirroredStrategy()... = qcnn_common.prepare_model(strategy)
Each worker of our QCNN distributed training job will run a copy of this Python code. Every worker needs to know the network endpoint of all other workers. The TF_CONFIG environment variable is typically used for this purpose, but in our case, the tf-operator injects it automatically behind the scenes.
After the model is trained, weights are uploaded to your Cloud Storage bucket to be accessed later by the inference job.
if task_type == 'worker' and task_id == 0:
qcnn_weights_path='/tmp/qcnn_weights.h5'
qcnn_model.save_weights(qcnn_weights_path)
upload_blob(args.weights_gcs_bucket, qcnn_weights_path, f'qcnn_weights.h5')
Before proceeding to the Kubernetes deployment setup and launching your workers, several parameters need to be configured in the tutorial source code to match your own setup. The provided script, setup.sh, can be used to simplify this process.
Open setup.sh and configure parameter values inside, if you haven’t already done so in a previous step. Then run
./setup.sh parammake trainingThe rest of this section walks through the Kubernetes setup in detail.
Prior to running as containers in Kubernetes, the QCNN job needs to be packaged as a container image using Docker and uploaded to the Container Registry. The Dockerfile contains the specification for the image. To build and upload the image, run:
docker build -t gcr.io/${PROJECT}/qcnn .
docker push gcr.io/${PROJECT}/qcnncommon/sa.yaml. This service account will be used by the QCNN containers.
apiVersion: v1
kind: ServiceAccount
metadata:
annotations:
iam.gke.io/gcp-service-account: ${SERVICE_ACCOUNT_NAME}@${PROJECT}.iam.gserviceaccount.com
name: ${SERVICE_ACCOUNT_NAME}kubectl apply -f common/sa.yaml
The last step is to create the distributed training job. training/qcnn.yaml contains the Kubernetes specifications for your job. In Kubernetes, multiple containers with related functions are grouped into a single entity called a Pod, which is the most fundamental unit of work that can be scheduled. Typically, users leverage existing resource types such as Deployment and Job to create and manage workloads. You’ll instead use TFJob (as specified in the `kind` field), which is not a Kubernetes built-in resource type but rather a Custom Resource provided by the tf-operator, making it easier to work with TensorFlow workloads.
Notably, the TFJob spec contains the field tfReplicaSpecs.Worker, which lets you configure a MultiWorkerMirroredStrategy worker. Values of PS (parameter server), Chief, and Evaluator are also supported for asynchronous and other forms of distributed training. Under the hood, tf-operator creates two Kubernetes resources for each worker replica:
tfReplicaSpecs.Worker.template. This runs the container you’ve built previously on Kubernetes.
<service_name>:<port> (the alternative form of <service_name>.<service_namespace>.svc:<port> works as well).
 |
| The TFJob generates one Service and Pod per worker replica. Once the TFJob is updated, changes are reflected in the underlying Services and Pods. Worker status is also reported in the TFJob. |
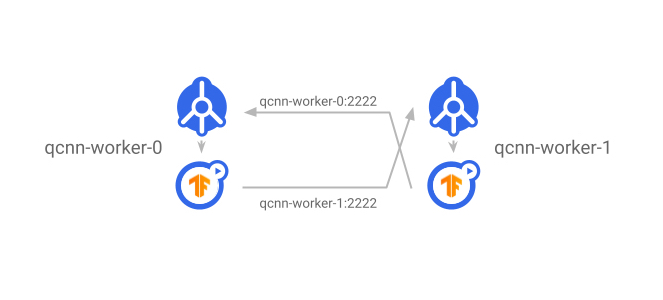 |
| The Service exposes worker servers to the rest of the cluster. Each worker communicates with other workers by using the destination worker’s Service name as the DNS name. |
Within the worker spec, there are a few notable fields:
TFJob:
kubectl apply -f training/qcnn.yamlkubectl get pods a few times (or add -w to stream the output). Eventually you should see there are the same number of qcnn-worker Pods as your replicas parameter, and they all have status Running:
NAME READY STATUS RESTARTS
qcnn-worker-0 1/1 Running 0
qcnn-worker-1 1/1 Running 0kubectl logs <worker_pod_name>-f to stream the output. The output of qcnn-worker-0 looks like this:
…
I tensorflow/core/distributed_runtime/rpc/grpc_server_lib.cc:411] Started server with target: grpc:/
/qcnn-worker-0.default.svc:2222
…
I tensorflow/core/profiler/rpc/profiler_server.cc:46] Profiler server listening on [::]:2223 selecte
d port:2223
…
Epoch 1/50
…
4/4 [==============================] - 7s 940ms/step - loss: 0.9387 - accuracy: 0.0000e+00 - val_loss: 0.7432 - val_accuracy: 0.0000e+00
…
I tensorflow/core/profiler/lib/profiler_session.cc:71] Profiler session collecting data.
I tensorflow/core/profiler/lib/profiler_session.cc:172] Profiler session tear down.
…
Epoch 50/50
4/4 [==============================] - 1s 222ms/step - loss: 0.1468 - accuracy: 0.4101 - val_loss: 0.2043 - val_accuracy: 0.4583
File /tmp/qcnn_weights.h5 uploaded to qcnn_weights.h5.
The output of qcnn-worker-1 should be similar except the last line is missing. The chief worker (worker 0) is responsible for saving weights of the entire model.
You can also verify that model weights are saved by visiting the Storage Browser in Cloud Console and browsing through the storage bucket you created previously.
To delete the training job, run
kubectl delete -f training/qcnn.yamlmodel.fit():
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir=args.logdir,
histogram_freq=1,
update_freq=1,
profile_batch='10, 20')
…
history = qcnn_model.fit(x=train_excitations,
y=train_labels,
batch_size=32,
epochs=50,
verbose=1,
validation_data=(test_excitations, test_labels),
callbacks=[tensorboard_callback])profile_batch parameter enables the TensorFlow Profiler in programmatic mode, which samples the program during the training step range you specify here. You can also enable the sampling mode,
tf.profiler.experimental.server.start(args.profiler_port)model.compile() step:
qcnn_model.compile(..., metrics=[‘accuracy’])
The TensorFlow Profiler is a helpful tool in debugging performance bottlenecks in your model training job.
In this tutorial, we use both the programmatic mode, in which profiling is done for a predefined training step range, as well as the sampling mode, in which profiling can be done on-demand. For a MultiWorkerMirroredStrategy setup, currently programmatic mode only outputs profiling data from the chief (worker 0), whereas sampling mode is able to profile all workers.
When you first open the Profiler, the data displayed is from the programmatic mode. The overview page gives you a sense of how long training took during each step. This will act as a reference as you experiment with different methods of improving training performance, whether that’s by scaling infrastructure (adding more VMs to the cluster, using VMs with more CPU and memory, integrating with hardware accelerators) or improving code efficiency.


To view the TensorBoard UI, you can create a TensorBoard instance in Kubernetes. The Kubernetes setup is in training/tensorboard.yaml. This file contains two objects:
tensorboard --logdir=gs://${BUCKET_NAME}/${LOGDIR_NAME} --port=5001 --bind_all
It is also possible to run a local instance of TensorBoard on your workstation by pointing --logdir to the same Cloud Storage bucket, although additional IAM permissions setup is required.
Create this Kubernetes setup:
kubectl apply -f training/tensorboard.yaml
In the output of kubectl get pods, you should see there’s a Pod with the prefix qcnn-tensorboard which is eventually in Running status. To get the IP address of the TensorBoard instance, run
kubectl get svc tensorboard-service -wNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S)
tensorboard-service LoadBalancer 10.123.240.9 <pending> 5001:32200/TCP
The load balancer takes some time to provision so you may not see the IP right away. Once it’s available, go to <ip>:5001 in your browser to access the TensorBoard UI.
With TensorFlow 2.4 and higher, it’s possible to profile multiple workers in sampling mode: workers can be profiled while a training job is running, by clicking “Capture Profile” in the Tensorboard Profiler and “Profile Service URL” to qcnn-worker-<replica_id>:2223. To enable this, the profiler port needs to be exposed by the worker service. The tutorial source code provides a script which patches all worker Services generated by the TFJob with a profiler port. Run
training/apply_profiler_ports.shtf-operator to support specifying additional ports in the TFJob.
inference/ directory. The main file, qcnn_inference.py, mostly reuses the model construction code in common/qcnn_common.py, but loads model weights from your Cloud Storage bucket instead:
qcnn_weights_path = '/tmp/qcnn_weights.h5'
download_blob(args.weights_gcs_bucket, args.weights_gcs_path, qcnn_weights_path)
qcnn_model.load_weights(qcnn_weights_path)results = qcnn_model(test_excitations).numpy().flatten()
loss = tf.keras.losses.mean_squared_error(test_labels, results)make inference
The inference program is built into the Docker image from the training step, so you don’t need to build a new image here. The inference job spec, inference/inference.yaml, contains a Job with its Pod spec pointing to the image but executes qcnn_inference.py instead. Run kubectl apply -f inference/inference.yaml to create the job.
The Pod prefixed with inference-qcnn should eventually be in Running status (kubectl get pods). In the log output of the inference Pod (kubectl logs <pod_name>), the mean squared error should be close to the final loss shown in the TensorBoard UI.
…
Blob qcnn_weights.h5 downloaded to /tmp/qcnn_weights.h5.
[-0.8220097 0.40201923 -0.82856977 0.46476707 -1.1281478 0.23317486
0.00584182 1.3351855 0.35139582 -0.09958048 1.2205497 -1.3038696
1.4065738 -1.1120421 -0.01021352 1.4553616 -0.70309246 -0.0518395
1.4699622 -1.3712595 -0.01870352 1.2939589 1.2865802 0.847203
0.3149605 1.1705848 -1.0051676 1.2537074 -0.2943283 -1.3489063
-1.4727883 1.4566276 1.3417912 0.9123422 0.2942805 -0.791862
1.2984066 -1.1139404 1.4648925 -1.6311806 -0.17530376 0.70148027
-1.0084027 0.09898916 0.4121615 0.62743163 -1.4237025 -0.6296255 ]
Test Labels
[-1 1 -1 1 -1 1 1 1 1 -1 1 -1 1 -1 1 1 -1 -1 1 -1 -1 1 1 1
1 1 -1 1 -1 -1 -1 1 1 1 -1 -1 1 -1 1 -1 -1 1 -1 1 1 1 -1 -1]
Mean squared error: tf.Tensor(0.29677835, shape=(), dtype=float32)And this wraps up our journey through distributed training! After you are done experimenting with the tutorial, this section walks you through the steps to clean up Google Cloud resources.
First, remove the Kubernetes deployments. Run:
make delete-inference
kubectl delete -f training/tensorboard.yamlmake delete-traininggcloud container clusters delete ${CLUSTER_NAME} --zone=${ZONE}gsutil rm -r gs://${BUCKET_NAME}qcnn.
Now that you’ve tried out the multi-worker setup, try setting it up with your project! As all the tools mentioned in this tutorial continue to grow, best practices for training with multiple workers will change over time. Check back on the tutorial directory in the TensorFlow Quantum GitHub repository for updates!
As you continue to scale your experiment, you might eventually hit infrastructure limitations that require advanced configuration of the technologies used in this tutorial due to the complexity of working in a distributed environment. For a deeper dive into some of them, check out these resources:

de juny 11, 2021 — Posted by Cheng Xing and Michael Broughton, Google Training large machine learning models is a core ability for TensorFlow. Over the years, scale has become an important feature in many modern machine learning systems for NLP, image recognition, drug discovery etc. Making use of multiple machines to boost computational power and throughput has led to great advances in the field. Similarly in quan…





