A guest post by Valerie Sarge, Shashank Verma, Ben Barsdell, James Sohn, Hao Wu, and Vartika Singh from NVIDIA

Recommenders personalize our experiences just about everywhere you can think of. They help you choose a movie for Saturday night, or discover a new artist when you've looped over your go-to playlist one too many times. They are one of the most important applications of deep learning, yet as it stands today, recommenders remain some of the most challenging models to accelerate due to their data requirements. This doesn’t just mean speeding up inference, but also training workflows so developers can iterate quickly. In this article, we’ll discuss what bottlenecks are typically observed with recommender workloads in practice, and how they can be identified and alleviated.
NVIDIA GPUs are great at handling parallelized computation, and have been successful in deep learning domains like Computer Vision (CV) or Natural Language Processing (NLP) where computation itself is usually the dominant factor in throughput as compared to the time it takes to bring the data itself to the model. However, modern recommenders tend to be memory and I/O bound as opposed to compute bound.
Modern recommenders can have hundreds of features, with many categorical features and cardinalities to the order of hundreds of millions! Take a “userID” feature for example. It isn’t too hard to imagine a hundred million distinct users. On occasion, the cumulative embedding tables may become so large that they would be hard to fit on a single GPU’s memory. Additionally, these large embedding tables involve pure memory lookups, whereas the deep neural networks themselves may be much smaller in terms of their memory footprint.
That being said, the latest advancements in NVIDIA GPU technology, especially increasingly large GPU memories and higher memory bandwidths, are progressively making GPUs even better candidates for accelerating recommenders. For instance, an NVIDIA A100 GPU 80GB has 80GB HBM2 memory with 2.0TB/s bandwidth compared to tens of GB/s bandwidth of CPU memory. This is in addition to a 40MB L2 cache that provides a whopping 6TB/s read bandwidth!
In practice, you may find that recommenders tend to underutilize GPUs as they are often bound by host-to-device memory transfer bottlenecks. Reading from CPU memory into GPUs (and vice versa) is expensive! It follows that avoiding frequent data transfers between the CPU and GPU should help improve performance. Yet, many TensorFlow ops relevant to recommenders don’t have a GPU implementation which leads to unavoidable back and forth data transfers between the CPU and GPU. Additionally, in typical recommender models the compute load itself is usually quite small as compared to NLP or CV models, and training tends to get held up by data loading.
Deep learning application performance can be limited by one or more portions of the training work, such as the input data pipeline (e.g. data loading and preprocessing), computationally-intensive layers, and/or memory reads and writes. The TensorFlow profiler, with its Trace Viewer illustrating a timeline of events for CPU and GPU, can help you identify performance bottlenecks.
The figure below shows a capture of the Trace Viewer from training a Wide & Deep (W&D) model on synthetic data in TensorFlow 2.4.3.
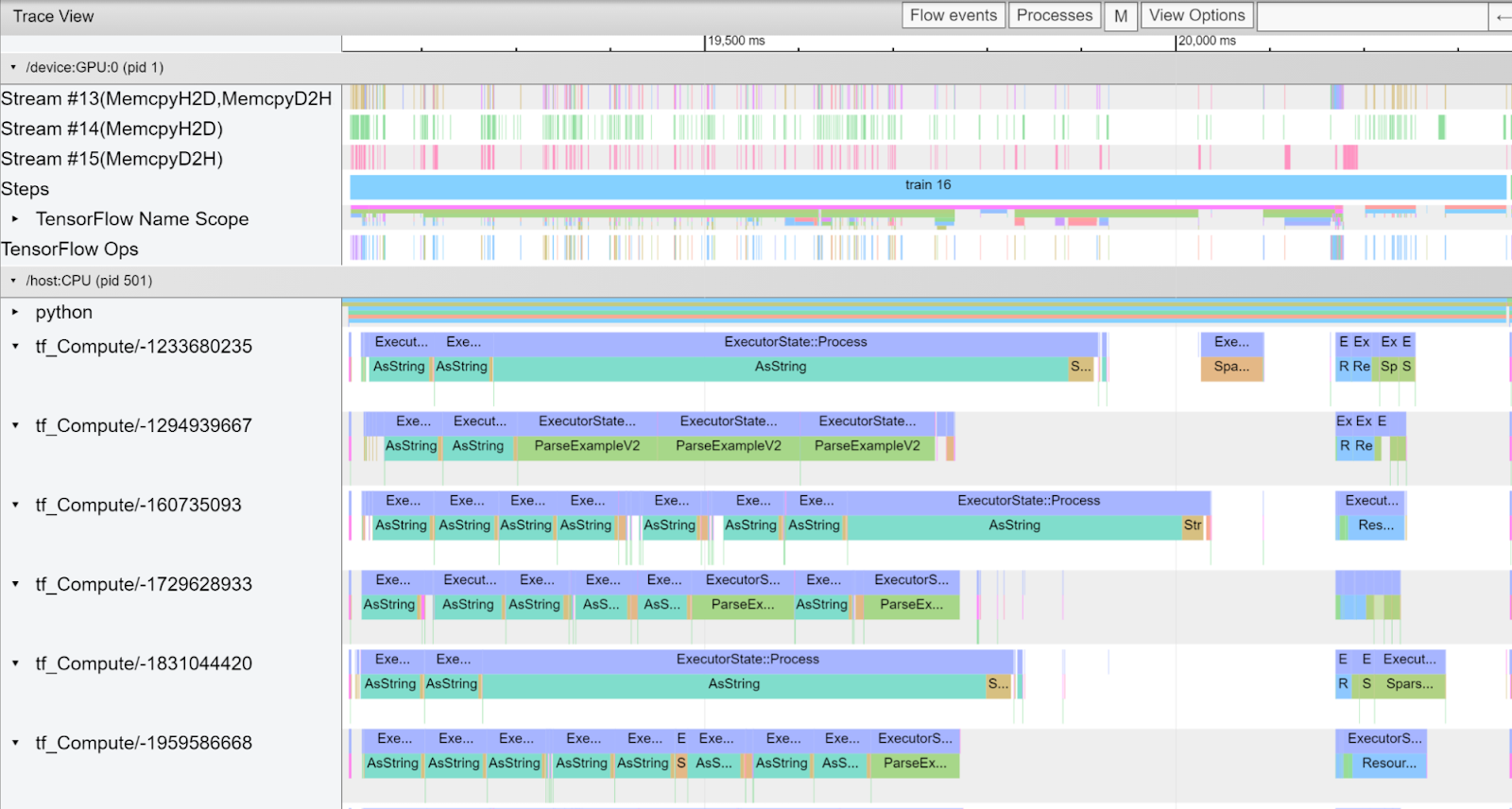 |
| Figure 1: Traces from training a W&D model on synthetic data in TensorFlow 2.4.3. |
In this capture, we can see that a few types of ops are responsible for much of the training time on the CPU. Some names are cut off, but these include:
You may also notice that there are many small memory copies in this profile, see Figure 1 Stream #14(MemcpyH2D) and Stream #15(MemcpyD2H). At the core of DenseFeatures and embedding_lookup_sparse, ops like ResourceGather fetch the needed weights from embedding tables. Here ResourceGather is performed on the GPU, but ops before and after it only have CPU implementations so data is copied back and forth between the CPU and GPU. This transfer is bound by the PCIe bandwidth, which is typically an order of magnitude slower than the GPU memory bandwidth. Additionally, though most individual copies are small, each takes time to launch, so they can be time-consuming in aggregate.
To accelerate ops like the SparseSegmentMean and Unique executed on the CPU in Figure 1 and reduce the time spent in resulting copies, TensorFlow 2.7 includes GPU implementations for a number of ops used by embedding functions, such as:
Several of the new GPU kernels leverage the CUDA CUB library to accelerate GPU primitives like scan and sort that are needed for sparse indexing calculations. The most intensive ops, SparseSegmentMean and SparseSegmentMeanGrad, use a custom GPU kernel that performs vectorized loads and stores to maximize memory throughput.
Now, let's take a look at what these improvements mean in practice.
Let’s compare training runs of a model based on the Wide & Deep architecture with TensorFlow version 2.4.3-GPU, the latest version before the above GPU sparse ops were implemented, and version 2.7.0-GPU, the first version to include all these GPU ops. The model includes 1 binary label, 10 numerical features, and 40 categorical features (3 of which are 10-hot, others are 1-hot).
In the following suite of benchmarks, some categorical features can take several values for each data point (i.e. they are “multi-hot”). As an example, a “history” feature in a movie recommendation use case could be a list of movies a user has previously watched. In comparison, a single-hot feature can take exactly one value. For the rest of this post, the term “n-hot” represents a multi-hot categorical feature that can take up to n values. Collectively, the embedding tables for all features in the model are 9.1 GB. The identity categorical column was used for these features except where the benchmark states otherwise.
The wide portions of the model use keras.layers.Embedding and the deep portions use keras.layers.DenseFeatures. These training runs use synthetic data read from a TFRecord file (described below in “Accelerating dataloading”), batch size 131,072, and the SGD optimizer. Performance data was recorded on a system with a single NVIDIA A100-80GB GPU and 2x AMD EPYC 7742 64-Core CPU @ 2.25GHz.
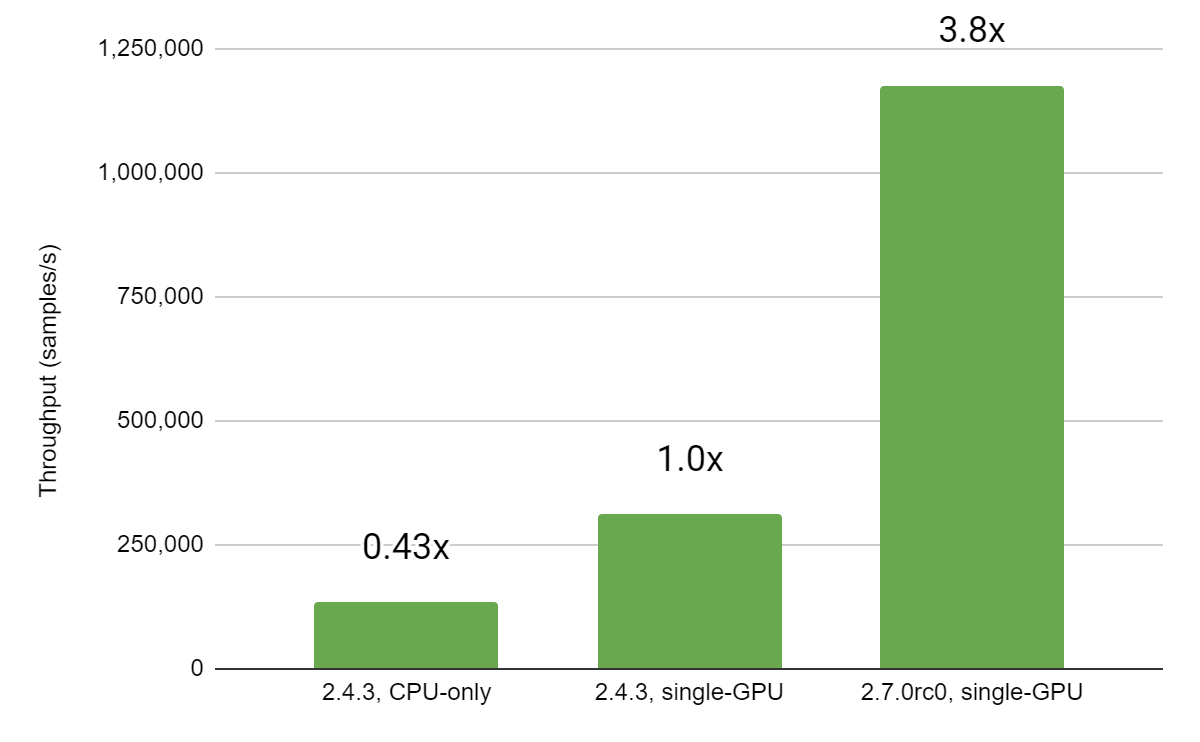 |
| Figure 2: Training throughput (in samples/second) |
From the figure above, going from TF 2.4.3 to TF 2.7.0, we observe a ~73.5% reduction in the training step. This equates to roughly a 3.77x training speedup on an NVIDIA A100-80GB from simply upgrading to TF 2.7.0! Let’s take a closer look at the changes that enabled this improvement.
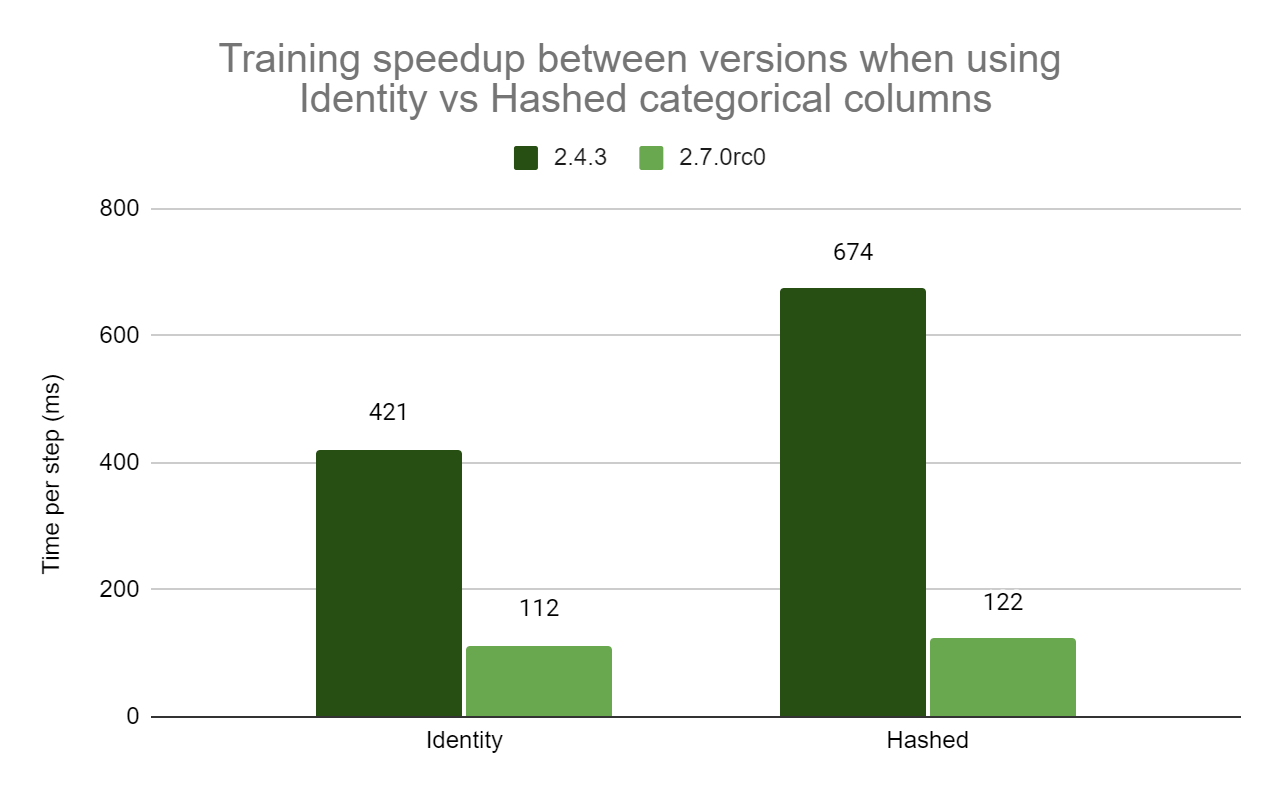 |
| Figure 3: Training step time speedup between versions when using exclusively identity categorical columns (3.77x) vs exclusively hashed categorical columns (5.55x) in the test model. Hashed categorical columns show additional speedup thanks to a new GPU integer hashing op. |
Both identity and hashed categorical columns benefit from the new GPU kernels. Because many of these ops were previously performed on the CPU in parallel to other parts of training, it is difficult to quantify the speedup from each, but these new kernels are collectively responsible for the majority of performance improvement.
Hashed categorical columns also benefit from a new GPU op (TensorToHashBucket) that replaces the previous AsString + StringToHashBucketFast hashing method in the Grappler pass. These ops were previously very time-consuming, so the test model using hashed categorical columns shows a larger improvement in the training step time.
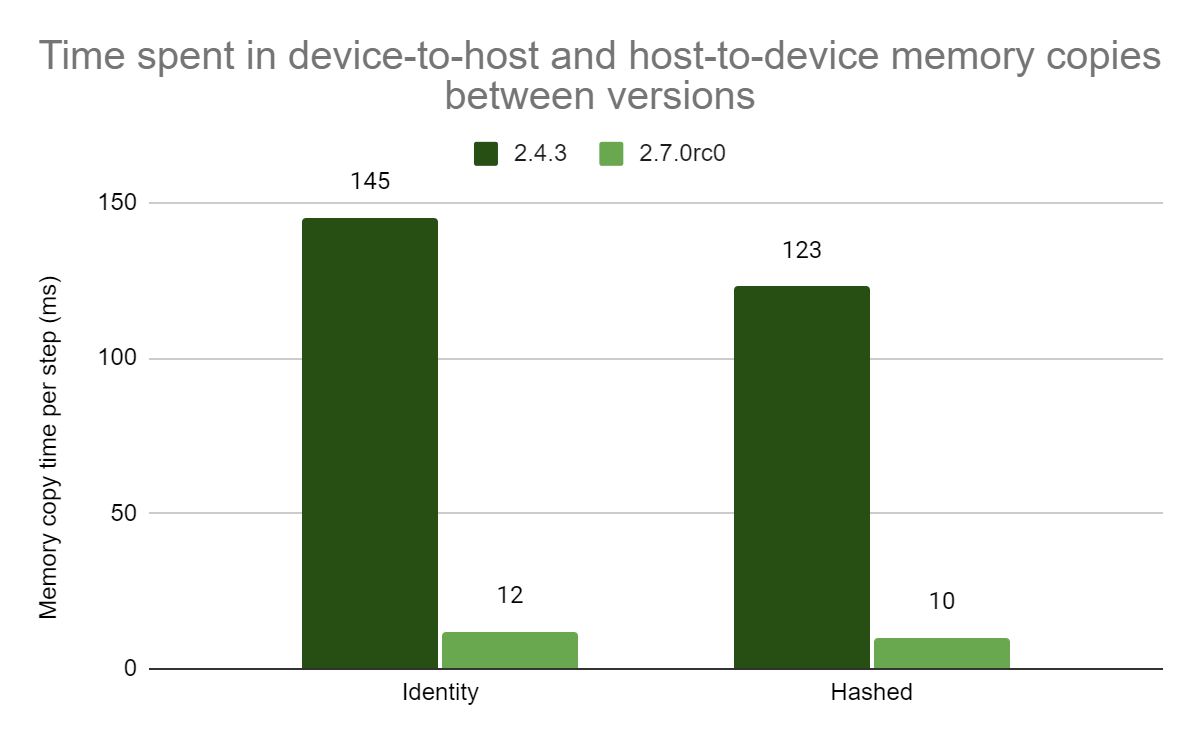 |
| Figure 4: Comparison of time spent in device-to-host and host-to-device memory copies. Availability of GPU kernels for ops in TensorFlow 2.7.0 saves time by avoiding extra copies. |
In addition to speedups from the GPU kernels themselves, some time is saved by performing fewer data copies. We previously mentioned that extra host-to-device and device-to-host copies are required when an op placed on the GPU is followed by one on the CPU or vice versa. Figure 4 shows the substantial reduction in time spent on copies from enabling more ops to be placed on the GPU.
Recommender training is frequently limited by the speed of loading data from disk. Below are three common ways to identity the data loading bottleneck:
In the examples so far, we have read data from a set of TFRecord files that have our synthetic input data pre-arranged into batches to avoid being limited by data loading (as that would make it difficult to see the speedup from the new changes, which affect operations within the network itself). In TFRecord files, normally each set of inputs is stored as a separate entry and batches are constructed after loading and shuffling data. For datasets with many small features, this can consume significant disk space because each entry is stored and labeled separately. For example, our test model has a binary label, 10 numerical features, and 40 categorical features (three 10-hot and the rest 1-hot). Each entry in a TFRecord of this model’s data contains a single floating-point value for each numerical feature and the appropriate number of integer values for each categorical feature. A dataset of about 4 million inputs takes up 4.1GB on disk in this basic format.
Now consider a record file where each entry contains an entire batch of 131,072 inputs for this model (so for each numerical feature, the entry will contain 131,072 serialized floating point values). The same dataset of 4 million inputs requires only 803MB on disk in this format, and training is more than 7x faster.
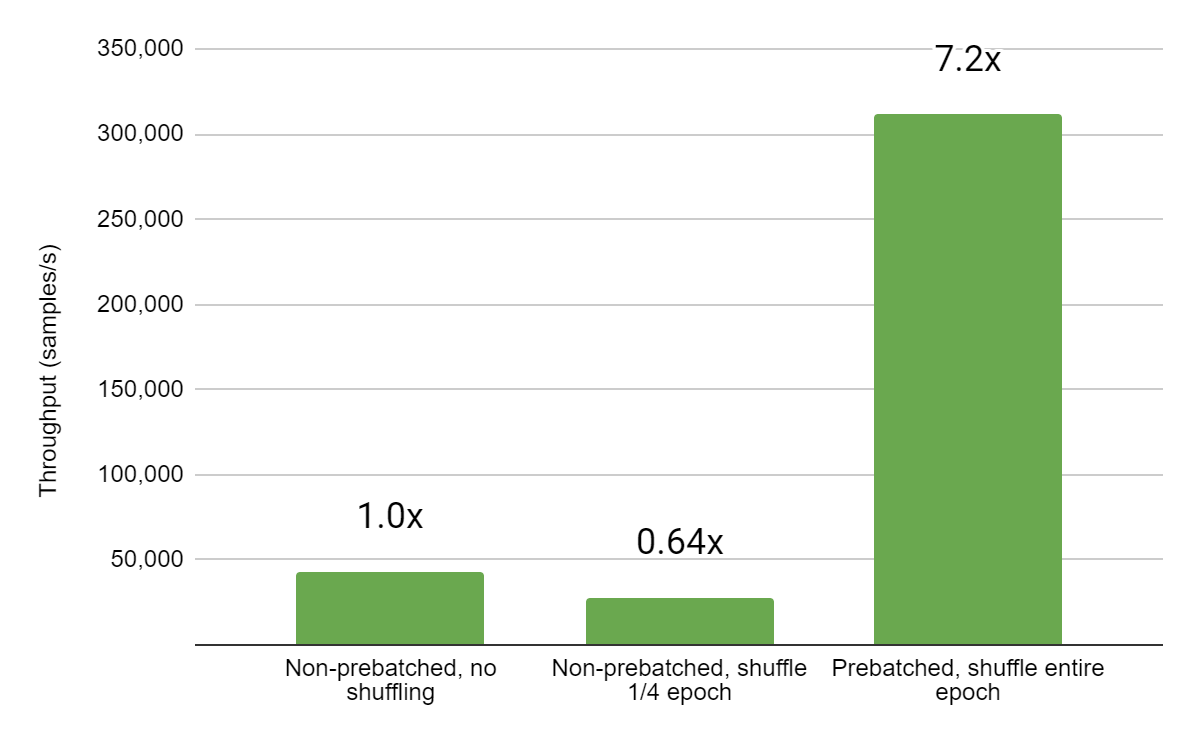 |
| Figure 5: The training step is over 7x faster after prebatching the input TFRecord dataset. While more thorough shuffling is possible with non-prebatched inputs, overhead is significant compared to negligible overhead from shuffling the order of prebatched input batches. |
Depending on how your data engineering pipeline is set up, you may have to add a component which creates the prebatched data. A side effect of prebatching data is that the batch size and contents are largely predefined at the time of writing the TFRecord. It is possible to work around these limitations (for example, by concatenating multiple batches from the file to increase the batch size at training time) but some flexibility might be lost.
The size and scale of recommenders grow rapidly, and it’s not uncommon to see recommender models in TBs (e.g. Google’s 1.2-TB model). Another great option to accelerate recommender training on NVIDIA GPUs, especially at multi-GPU and multi-node scale, is a TF custom embedding plugin. This CUDA-based plugin distributes large embedding tables across multiple GPUs and nodes for model-parallel multi-GPU training out-of-the-box. It works as a GPU plug-in enhancement for TF native embedding layers such as tf.nn.embedding_lookup and tf.nn.embedding_lookup_sparse. With TensorFlow version 2.5 and above, a single NVIDIA A100 GPU benchmark using a model with 100 ten-hot categorical features shows 7.9x speedup in average training iteration time with the TF custom embedding plugin, and the speedup increases to 23.6x on four NVIDIA A100 GPUs. Check out this article for an overview of this plugin and more information.
Recommenders present a challenging workload to accelerate. Advancements in NVIDIA GPU technology with increasingly large memories, memory bandwidths, and ever powerful parallel compute greatly benefit modern recommendation systems at scale.
We have added GPU implementations of several ops in TensorFlow that did not have one previously, massively improving training times, thus reducing the time a data scientist might spend experimenting and creating recommender models. Moreover, there is another option available to accelerate embedding layers on NVIDIA GPUs through the TF custom embedding plugin.
January 21, 2022 — A guest post by Valerie Sarge, Shashank Verma, Ben Barsdell, James Sohn, Hao Wu, and Vartika Singh from NVIDIA Recommenders personalize our experiences just about everywhere you can think of. They help you choose a movie for Saturday night, or discover a new artist when you've looped over your go-to playlist one too many times. They are one of the most important applications of deep learning…





