Posted by Zu Kim and Louis Romero, Software Engineers, Google Research
Classification-by-retrieval provides an easy way to create a neural network-based classifier without computationally expensive training via backpropagation. Using this technology, you can create a lightweight mobile model with as little as one image per class, or you can create an on-device model that can classify as many as tens of thousands of classes. For example, we created mobile models that can recognize tens of thousands of landmarks with the classification-by-retrieval technology.
There are many use-cases for classification-by-retrieval, including:
Classification and retrieval are two distinct methods of image recognition. A typical object recognition approach is to build a neural network classifier and train it with a large amount of training data (often thousands of images, or more). On the contrary, the retrieval approach uses a pre-trained feature extractor (e.g., an image embedding model) with feature matching based on a nearest neighbor search algorithm. The retrieval approach is scalable and flexible. For example, it can handle a large number of classes (say, > 1 million), and adding or removing classes does not require extra training. One would need as little as a single training data per class, which makes it effectively few-shot learning. A downside of the retrieval approach is that it requires extra infrastructure, and is less intuitive to use than a classification model. You can learn about modern retrieval systems in this article on TensorFlow Similarity.
Classification-by-retrieval (CbR) is a neural network model with image retrieval layers baked into it. With the CbR technology, you can easily create a TensorFlow classification model without any training.
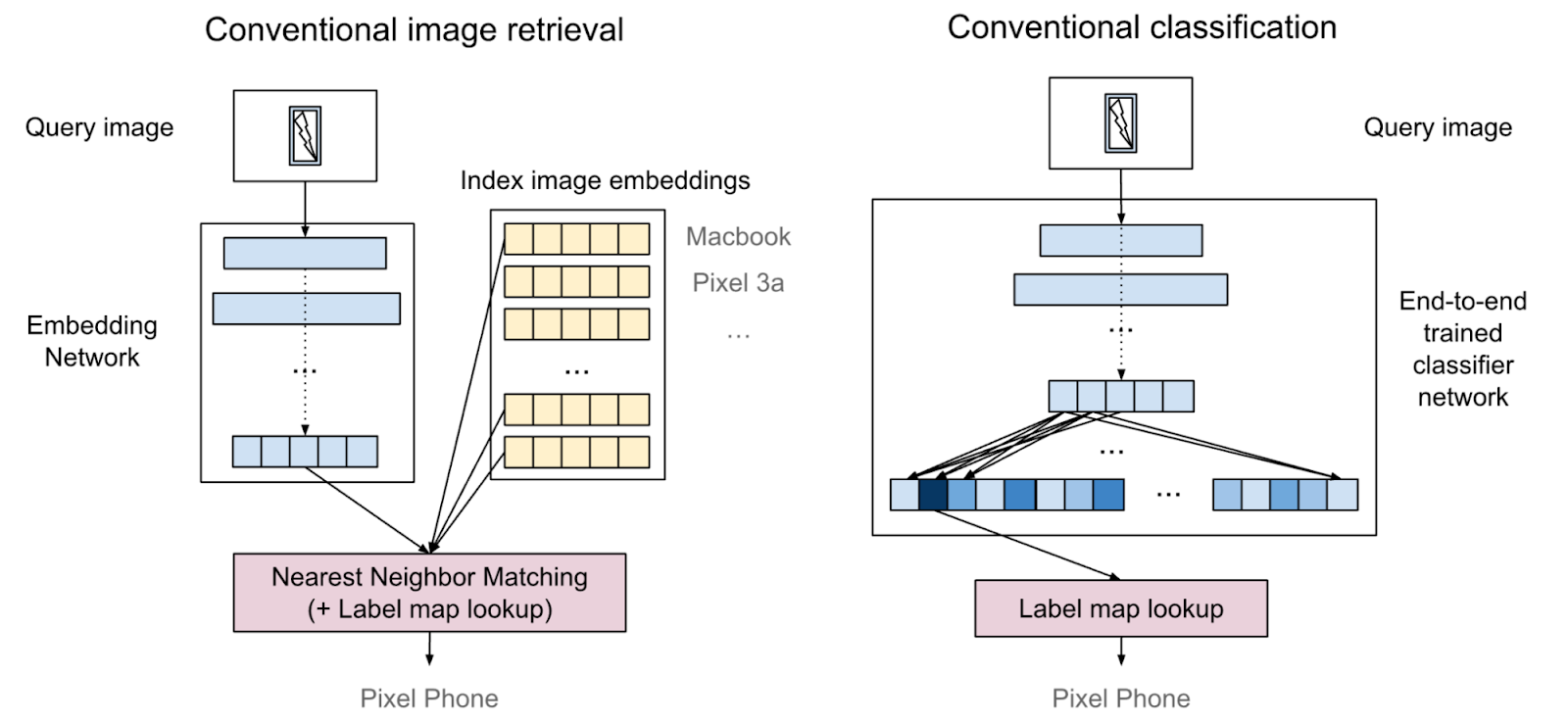 |
| An image describing conventional image retrieval and conventional classification. Conventional image retrieval requires special retrieval infrastructure, and conventional classification requires expensive training with a large amount of data. |
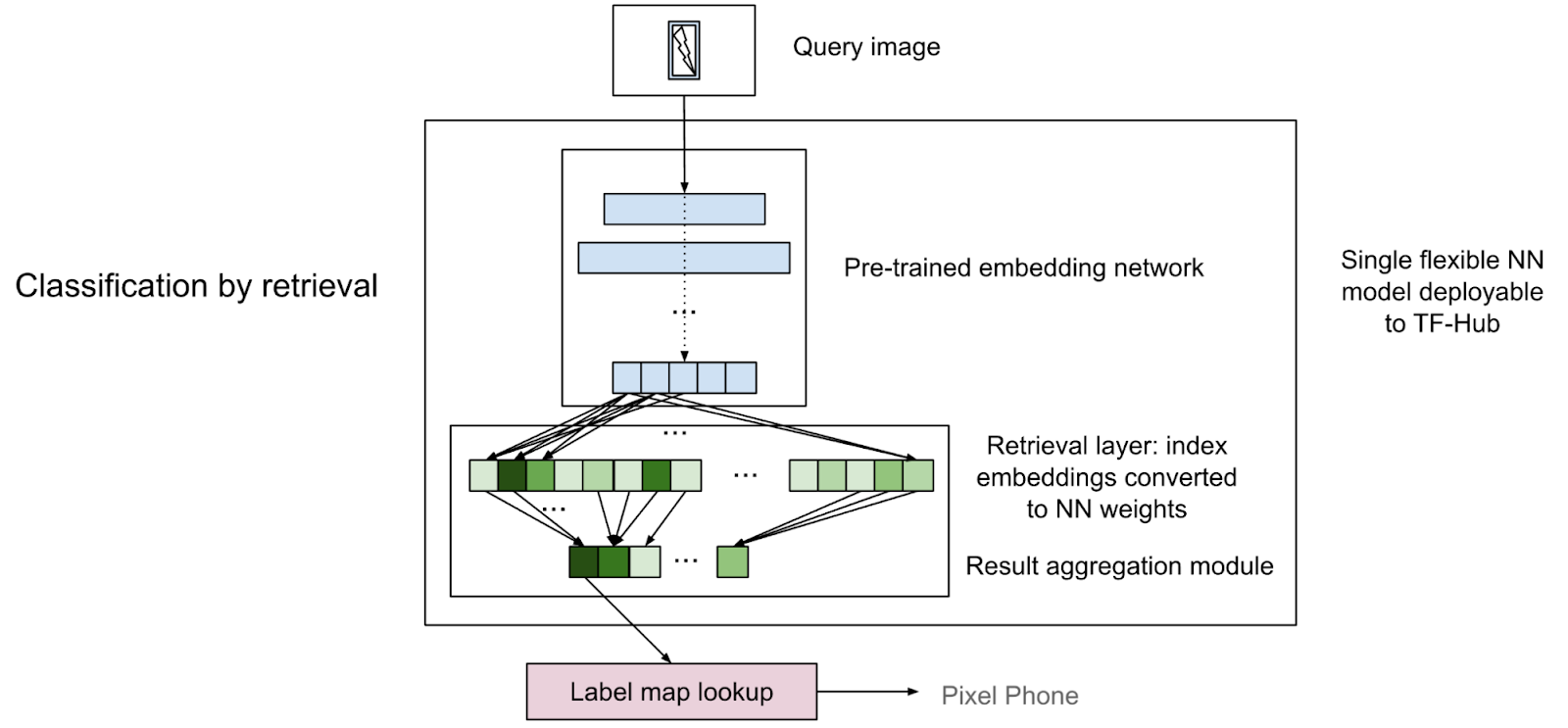 |
| An image describing how classification-by-retrieval composes with a pre-trained embedding network and a final retrieval layer. It can be built without expensive training, and does not require special infrastructure for inference. |
A classification-by-retrieval model is an extension of an embedding model with extra retrieval layers. The retrieval layers are computed (not trained) from the training data, i.e., the index data. The retrieval layers consists of two components:
The nearest neighbor matching component is essentially a fully connected layer where its weights are the normalized embeddings of the index data. Note that a dot-product of two normalized vectors (cosine similarity) is linear (with a negative coefficient) to the squared L2 distance. Therefore, the output of the fully connected layer is effectively identical to the nearest neighbor matching result.
The retrieval result is given for each training instance, not for each class. Therefore, we add another result aggregation component on top of the nearest neighbor matching layer. The aggregation component consists of a selection layer for each class followed by an aggregation (e.g., max) layer for each of them. Finally, the results are concatenated to form a single output vector.
You may choose a base embedding model that best fits the domain. There are many embedding models available, for example, in TensorFlow Hub. The provided iOS demo uses a MobileNet V3 trained with ImageNet, which is a generic and efficient on-device model.
In some sense, CbR (indexing) can be considered as a few-shot learning approach without training. Although it is not apples to apples to compare CbR with an arbitrary pre-trained base embedding model with a typical few-shot learning approach where the whole model trained with given training data, there is a research that compares nearest neighbor retrieval (which is equivalent to CbR) with few-shot learning approaches. It shows that nearest neighbor retrieval can be comparable or even better than many few-shot learning approaches.
The code is available at https://github.com/tensorflow/examples/tree/master/lite/examples/classification_by_retrieval/lib.
To demo the ease of use of the Classification-by-Retrieval library, we built a mobile app that lets users select albums in their photo library as input data to create a new, tailor-made, image classification TFLite model. No coding required.
 |
| The iOS lets users create a new model by selecting albums in their library. Then the app lets them try the classification model on the live camera feed. |
We encourage you to use these tools to build a model that is fair and responsible. To learn more about building a responsible model:
We will explore possible ways to extend TensorFlow Lite Model Maker for on-device training capability based on this work.
Many people contributed to this work. We would like to thank Maxime Brénon, Cédric Deltheil, Denis Brulé, Chenyang Zhang, Christine Kaeser-Chen, Jack Sim, Tian Lin, Lu Wang, Shuangfeng Li, and everyone else involved in the project.

يناير 18, 2022 — Posted by Zu Kim and Louis Romero, Software Engineers, Google Research Classification-by-retrieval provides an easy way to create a neural network-based classifier without computationally expensive training via backpropagation. Using this technology, you can create a lightweight mobile model with as little as one image per class, or you can create an on-device model that can classify as many as t…





