Posted by Mingsheng Hong, TFRT Tech Lead/Manager & Eric Johnson, TFRT Product Manager

Roughly two years ago, we announced an ambitious new Machine Learning (ML) runtime effort called TFRT (short for TensorFlow Runtime). We simultaneously provided a deep dive of the initial technical design and open-sourced its codebase.
Driven by trends in the ML ecosystem – larger and bigger models, ML being deployed to more diverse execution environments, and the need to keep up with continued research and modeling innovations – TFRT was started with the following set of goals in mind:
In this post, we share our progress to date, the experiences and lessons we’ve learned over the past two years of development, as well as what you can expect going forward.
The last two years of development have largely been focused on implementing and validating our ambitious ideas by enabling Google’s most important internal workloads for users such as Ads and Search. To date, we have deployed TFRT broadly inside Google on a variety of training and inference workloads, and obtained great results.
How have we been able to achieve the above? Here are some interesting technical lessons that we learned, beyond what was in the original design:
First, async support is important for some of the key workloads (e.g. overlapping compute and I/O, and driving heterogeneous devices), while fast sync execution is critical for many other workloads, including small, “embedded” ML models.
We spent a lot of effort in designing and refining AsyncValue, a key low level abstraction in TFRT, which allows the host runtime to asynchronously drive devices, as well as invoking kernels. This led to improved device utilization due to the ability to overlap more computation and communication across hosts and devices. For example, we were able to successfully run bulk inference of an 80B-parameter model on one TPU chip with good performance by splitting the model into multiple stages and using TFRT to overlap variable transfer of the next stage with TPU computation of the current stage.
On the other hand, small CPU models that are embedded in application servers, invoked within the application process instead of via RPC/REST calls, remain critical for some of Google’s business workloads from users like Ads. For these models, the async-first internal design of TFRT initially caused a performance and resource regression. We worked with the Ads team to successfully address it, by extending the TFRT design with a synchronous interpreter, as well as an experimental memory planning optimization, to avoid heap allocation during kernel execution. We are working on productizing this extension.
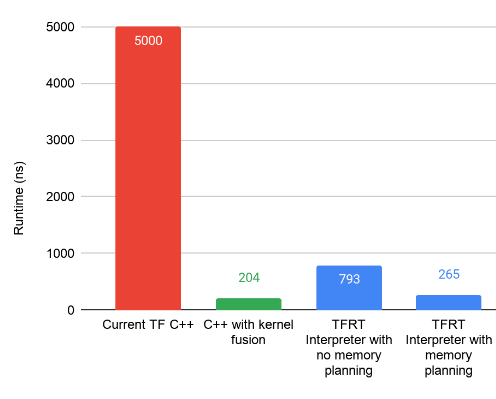
This diagram below showcases the impact of the resulting TFRT design over a benchmark, as compared to “Current TF” which ran the old runtime before TFRT’s deployment. This benchmark focused on executing a tiny CPU model, where a large number of small matmuls executed sequentially. Notably, the optimized execution in TFRT (265 ns) is approaching the optimal baseline we set up (204 ns), via hand-written C++ code without any ML runtime overhead.
Second, while faster runtime execution is critical, optimizing the input program to reduce execution complexity is important as well.
Note that while compiler-based graph optimization should be performed when TF SavedModel is saved to the disk whenever possible, there are also important inference-time compiler optimizations that can only be performed with the knowledge of being in an inference context (e.g. when training variables remain constant).
As we were onboarding ML models onto TFRT, we had the chance to examine some of the models in depth, and identified new ways of rewriting and simplifying the program, before its execution. The simplified program, along with a faster execution of each kernel in the graph program, led to a nice compounding effect in the reduction of the execution latency and resource cost.
For example, in the left hand side graph program below, we were able to hoist the scalar op normalization computation (e.g. divide a float value by the max value of its domain), identical across all 18 input scalars, above the “concat” op, therefore enabling vectorized execution of the normalization, over a concatenated 1D float tensor.

While it is possible to perform this optimization at model training time as well, the compiler+runtime used to produce the trained model did not include this optimization.
In addition, we also find it critical to hoist computation from model execution time to load time whenever possible (e.g. const folding).
Third, cost-based execution is not just for SQL queries.
We developed a simple compile-time cost model (analogous to SQL query optimizer’s cost model) for TF op kernels, and applied cost-based optimization for ML model execution (see stream analysis), and achieved a better load balancing of the kernel execution across a set of threadpool threads. In contrast, TF1 has a runtime-based cost model, in which each operation's runtime cost is profiled and used to guide that operation’s scheduling. In TFRT, we moved the cost analysis to compile-time, thus removing runtime cost. Also, our compiler approach allows the entire computational graph to be analyzed, thereby resulting in scheduling decisions that are optimal at a more global scope.
See this tech talk for more similarities between data and ML infra.
While we’ve certainly made some strong progress, especially with respect to our first goal – faster and cheaper execution – we admittedly still have work to do on enabling a more modular design and enabling more flexible deployments via hardware integration.
In terms of modularity, with the initial integration successes such as JAX’s adoption of TFRT device runtimes (e.g. CPU), we will continue to explore how TFRT could support workloads beyond just TensorFlow. We expect some of the TFRT components will also benefit the PyTorch/XLA workloads going forward.
Moreover, while we have successfully integrated CPU and TPU (with upcoming integration into Cloud TPU), the two most important device types at Google for ML computation, with NVIDIA GPU also in progress.
With respect to training workload, TFRT has been used as building blocks for Google's large scale distributed training framework which are currently in active development.
As we look to the future, our organization has been exploring its integration with Pixel’s hardware SOC devices such as Google Tensor. In addition, due to TFRT’s proven success for Google’s internal workloads, it is also being integrated into new venues such as GCP’s Vertex AI and Waymo.
The TFRT team has really enjoyed working on this new, ambitious infrastructure project. It has often felt like bootstrapping a new startup. With that in mind, we would like to give a huge shout out to everyone who has advised, contributed to and supported TFRT through this incredible 2-year journey:
(alphabetically) Adi Agrawal, Andrew Bernard, Andrew Leaver, Andy Selle, Ayush Dubey, Bangda Zhou, Bramandia Ramadhana, Catherine Payne, Ce Zheng, Chiachen Chou, Chao Xie, Christina Sorokin, Chuanhao Zhuge, Dan Hurt, Dong Lin, Eugene Zhulenev, Ewa Matejska, Hadi Hashemi, Haoliang Zhang, HanBin Yoon, Haoyu Zhang, Hongmin Fan, Jacques Pienaar, Jeff Dean, Jeremy Lau, Jordan Soyke, Jing Dong, Juanli Shen, Kemal El Moujahid, Kuangyuan Chen, Mehdi Amini, Ning Niu, Peter Gavin, Phil Sun, Pulkit Bhuwalka, Qiao Zhang, Raziel Alvarez, Russell Power, Sanjoy Das, Shengqi Zhu, Smit Hinsu, Tatiana Shpeisman, Tianrun Li, Tim Davis, Tom Black, Victor Akabutu, Vilobh Meshram, Xiao Yu, Xiaodan Song, Yiming Zhang, YC Ling, Youlong Chen, and Zhuoran Liu.
We would like to give special thanks to Chris Lattner for his initial technical leadership in bootstrapping this project, Martin Wicke for his support in TFRT throughout the first year, Alex Zaks for his support in TFRT during the second year and seeing through the impactful landing for Google’s ML serving workloads.

February 09, 2022 — Posted by Mingsheng Hong, TFRT Tech Lead/Manager & Eric Johnson, TFRT Product Manager Roughly two years ago, we announced an ambitious new Machine Learning (ML) runtime effort called TFRT (short for TensorFlow Runtime). We simultaneously provided a deep dive of the initial technical design and open-sourced its codebase. Driven by trends in the ML ecosystem – larger and bigger models, ML bein…





