Posted by Dan Kondratyuk, Liangzhe Yuan, Google Research and Khanh LeViet, TensorFlow Developer Relations
We are excited to announce MoViNets (pronounced “movie nets”), a family of new mobile-optimized model architectures for video classification. The models are trained on the Kinetics-600 dataset to be able to recognize 600 different human actions (such as playing trumpet, robot dancing, bowling, and more) and can classify video streams captured on a modern smartphone in real time. You can download the pre-trained TensorFlow Lite models from TensorFlow Hub or try it out using our Android and Raspberry Pi demo apps, as well as fine-tune your own MoViNets with the Colab demo and the code in the TensorFlow Model Garden.
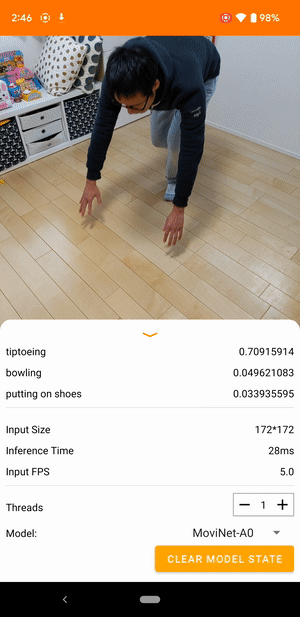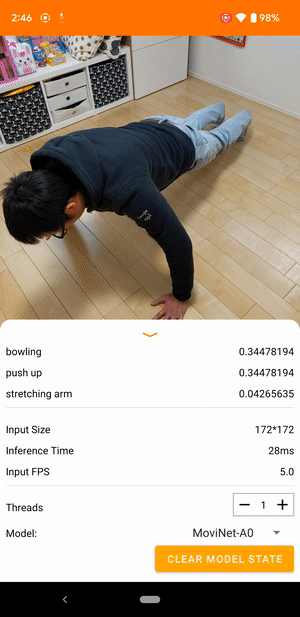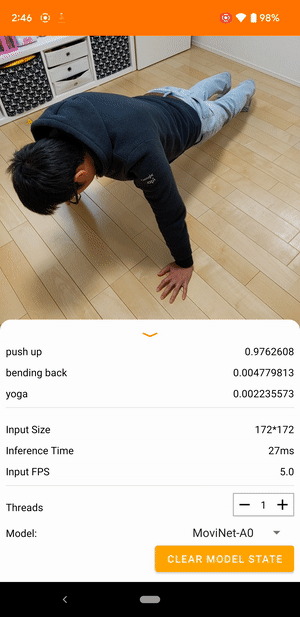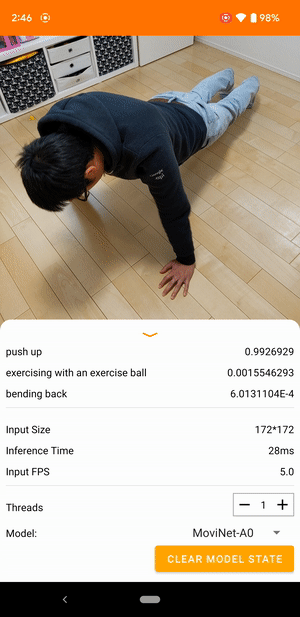 |
| Demo from the TensorFlow Lite video classification reference app |
Video classification is a machine learning task that takes video frames as input and predicts a single class from a larger set of classes. Video action recognition is a type of video classification where the set of predicted classes consists of human actions that happened in the frames. Video action recognition is similar to image recognition in that both take input images and output the probabilities of the images belonging to each of the predefined classes. However, a video action recognition model has to look at both the content of each frame and the spatial relationships between adjacent frames to understand the actions in the video. For example, if you look at these still images, it’s difficult to tell what the person is doing.
 |
|
 |
But if you look at the full video, it becomes clear that the person is performing jumping jacks.

MoViNets are a family of convolutional neural networks which efficiently process video streams, outputting accurate predictions with a fraction of the latency of convolutional video classifiers like 3D ResNets or transformer-based classifiers like ViT.
Frame-based classifiers output predictions on each 2D frame independently, resulting in sub-optimal performance due to their lack of temporal reasoning. On the other hand, 3D video classifiers offer high accuracy predictions by processing all frames in a video clip simultaneously, at a cost of significant memory and latency penalties as the number of input frames increases. MoViNets offer key advantages from both 2D frame-based classifiers and 3D video classifiers while mitigating their disadvantages.
The following figure shows a typical approach to using 3D networks with multi-clip evaluation, where the predictions of multiple overlapping subclips are averaged together. Shorter subclips result in lower latency, but reduce the overall accuracy.
 |
| Diagram illustrating Multi-Clip Evaluation for 3D Video Networks |
MoViNets take a hybrid approach, which proposes the use of causal convolutions in place of 3D convolutions, allowing intermediate activations to be cached across frames with a Stream Buffer. The Stream Buffer copies the input activations of all 3D operations, which is output by the model and then input back into the model on the next clip input.
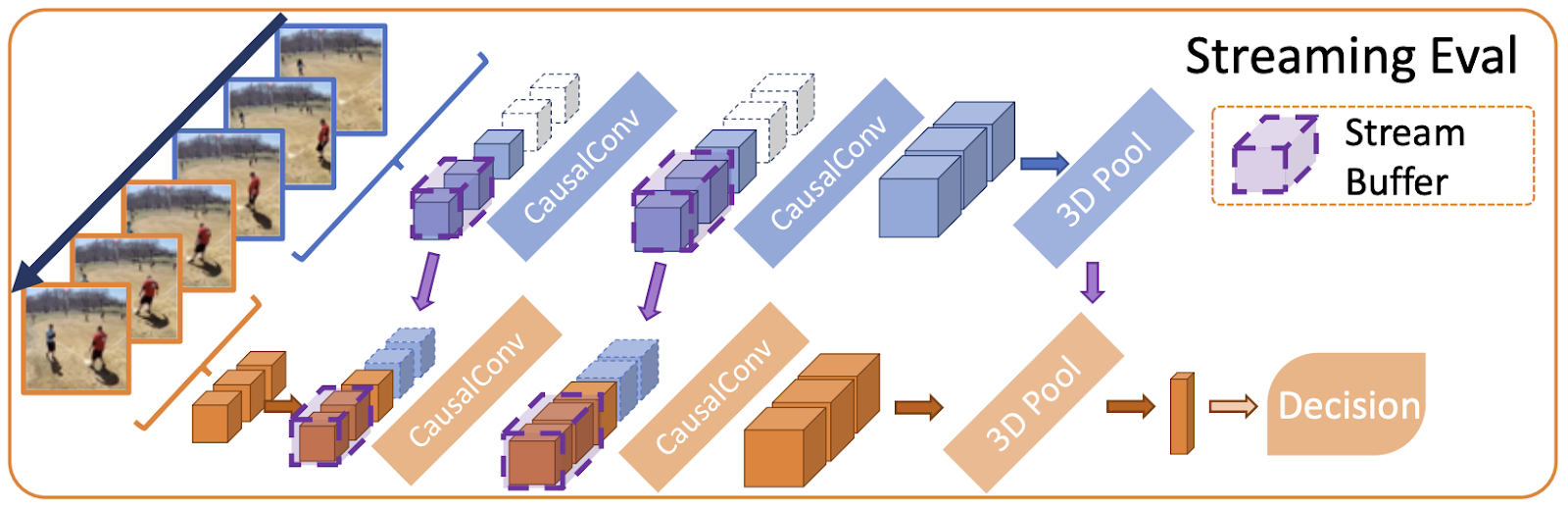 |
| Diagram illustrating Streaming Evaluation for MoViNets |
The result is that MoViNets can receive one frame input at a time, reducing peak memory usage while resulting in no loss of accuracy, with predictions equivalent to inputting all frames at once like a 3D video classifier. MoViNets additionally leverage Neural Architecture Search (NAS) by searching for efficient configurations of models on video datasets (specifically Kinetics 600) across network width, depth, and resolution.
The result is a set of action classifiers that can output temporally-stable predictions that smoothly transition based on frame content. Below is an example plot of MoViNet-A2 making predictions on each frame on a video clip of skateboarding. Notice how the initial scene with a small amount of motion has relatively constant predictions, while the next scene with much larger motion causes a dramatic shift in predicted classes.
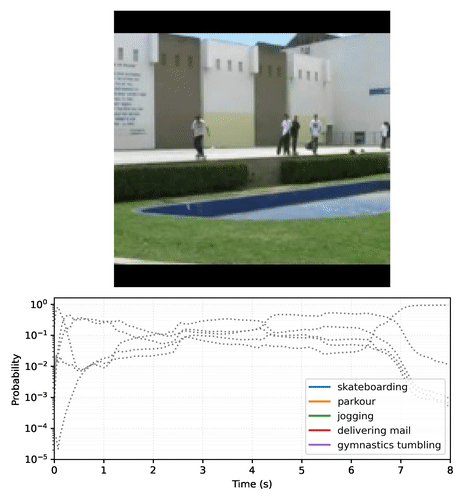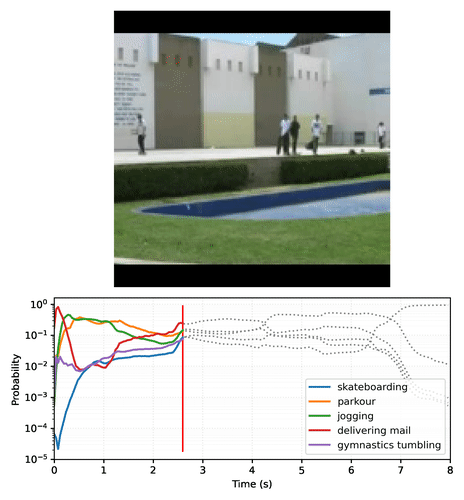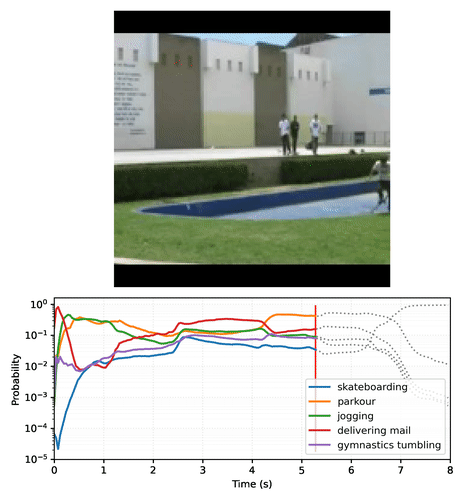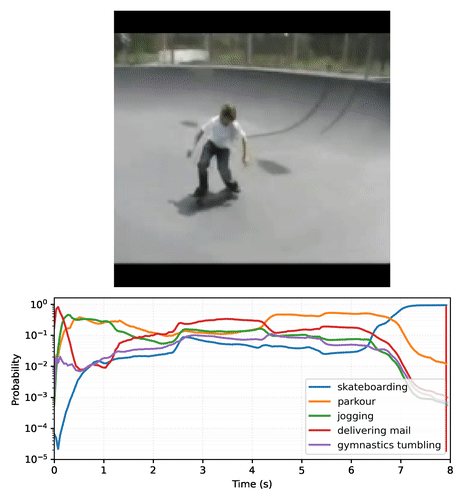 |
| A video plotting the top-5 predictions of MoViNet-A2 over time on an example 8-second (25 fps) skateboarding video clip. Create your own plots with this Colab notebook. |
MoViNets need a few modifications to be able to run effectively on edge devices. We start with MoViNet-A0-Stream, MoViNet-A1-Stream, and MoViNet-A2-Stream, which represent the smaller models that can feasibly run in real time (20 fps or higher). To effectively quantize MoViNet, we adapt a few modifications to the model architecture - the hard swish activation is replaced by ReLU6, and Squeeze-and-Excitation layers are removed in the original architectures, which results in 3-4 p.p accuracy drop on Kinetics-600. We then convert the models to TensorFlow Lite and use integer-based post-training quantization (as well as float16 quantization) to reduce the model sizes and make them run faster on mobile CPUs. The integer-based post-training quantization process further introduces 2-3 p.p. accuracy loss. Compared to the original MoViNets, quantized MoViNets lag behind in accuracy on full 10-second Kinetics 600 clips (5-7 p.p. accuracy reduction in total), but in practice they are able to provide very accurate predictions on daily human actions, e.g., push ups, dancing, and playing piano. In the future, we plan to train with quantization-aware training to bridge this accuracy gap.
We benchmark quantized A0, A1, and A2 on real hardware and the model inference time achieves 200, 120, and 60 fps respectively on Pixel 4 CPU. In practice, due to the input pipeline overhead, we see increased latency closer to 20-60 fps when running on Android with a camera as input.
Train a Custom Model
You can train your own video classifier model using the MoViNet codebase in the TensorFlow Model Garden. The provided Colab notebook provides specific steps on how to fine-tune a pretrained video classifier on another dataset.
Future Steps
We are excited to see on-device online video action recognition powered by MoViNets, which demonstrate highly efficient performance. In the future, we plan to support quantize-aware training for MoViNets to mitigate the quantization accuracy loss. We also are interested in extending MoViNets as the backbone for more on-device video tasks, e.g. video object detection, video object segmentation, visual tracking, pose estimation, and more.
Acknowledgement
We would like to extend a big thanks to Yeqing Li for supporting MoViNets in TensorFlow Model Garden, Boqing Gong, Huisheng Wang, and Ting Liu for project guidance, Lu Wang for code reviews, and the TensorFlow Hub team for hosting our models.

4월 14, 2022 — Posted by Dan Kondratyuk, Liangzhe Yuan, Google Research and Khanh LeViet, TensorFlow Developer Relations We are excited to announce MoViNets (pronounced “movie nets”), a family of new mobile-optimized model architectures for video classification. The models are trained on the Kinetics-600 dataset to be able to recognize 600 different human actions (such as playing trumpet, robot dancing, bowling…






