Posted by Nikita Namjoshi, Google Cloud Developer Advocate
When you start working on a new machine learning problem, I’m guessing the first environment you use is a notebook. Maybe you like running Jupyter in a local environment, using a Kaggle Kernel, or my personal favorite, Colab. With tools like these, creating and experimenting with machine learning is becoming increasingly accessible. But while experimentation in notebooks is great, it’s easy to hit a wall when it comes time to elevate your experiments up to production scale. Suddenly, your concerns are more than just getting the highest accuracy score.
What if you have a long running job, want to do distributed training, or host a model for online predictions? Or maybe your use case requires more granular permissions around security and data privacy. What is your data going to look like at serving time, how will you handle code changes, or monitor the performance of your model overtime?
Making production applications or training large models requires additional tooling to help you scale beyond just code in a notebook, and using a cloud service provider can help. But that process can feel a bit daunting. Take a look at the full list of Google Cloud products, and you might be completely unsure where to start.
So to make your journey a little easier, I’ll show you a fast path from experimental notebook code to a deployed model in the cloud.
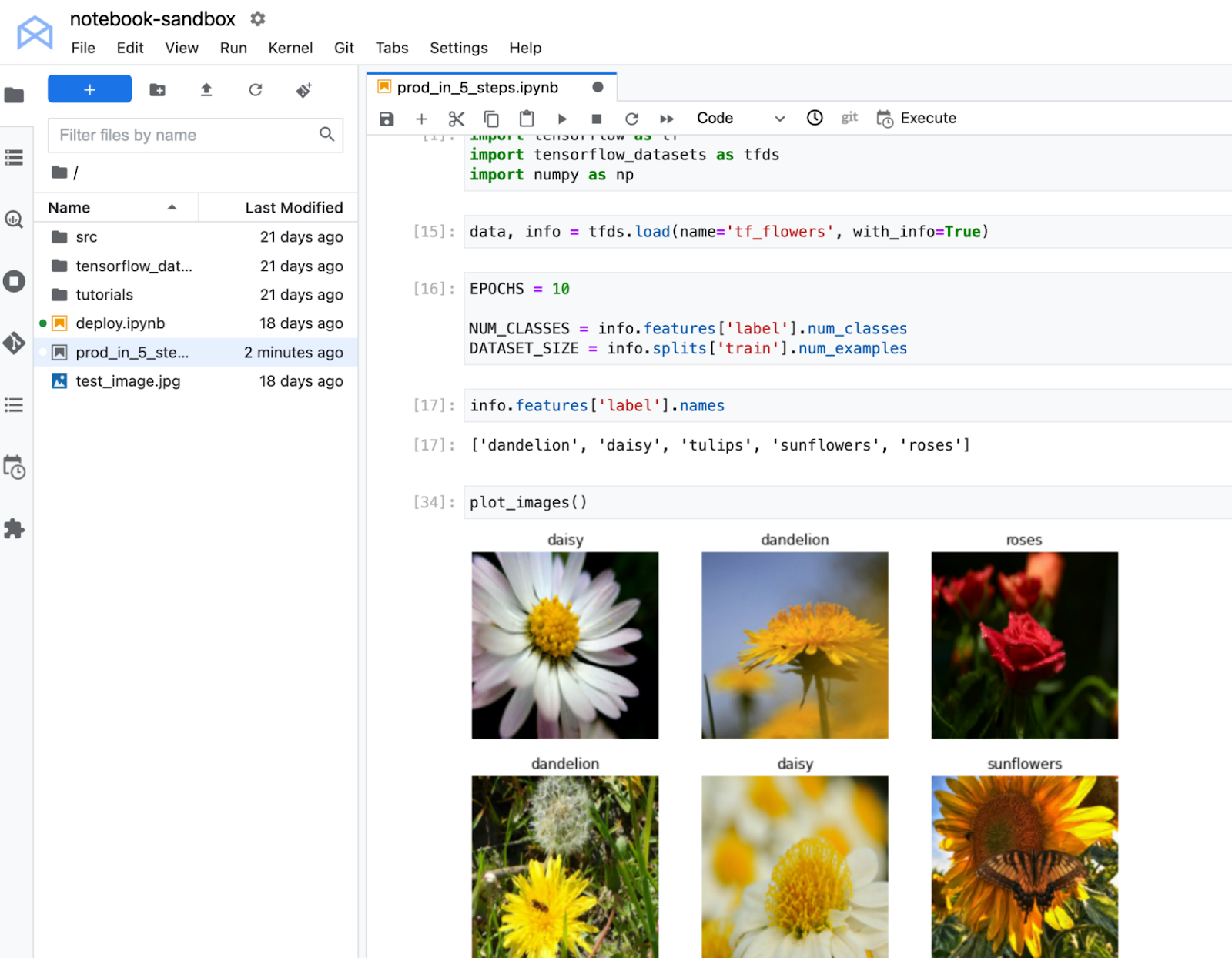
The code used in this sample can be found here. This notebook trains an image classification model on the TF Flowers dataset. You’ll see how to deploy this model in the cloud and get predictions on a new flower image via a REST endpoint.
Note that you’ll need a Google Cloud project with billing enabled to follow this tutorial. If you’ve never used Google Cloud before, you can follow these instructions to set up a project and get $300 in free credits to experiment with.
Here are the five steps you’ll take:
To train and deploy the model, you’ll use Vertex AI, which is Google Cloud’s managed machine learning platform. Vertex AI contains lots of different products that help you across the entire lifecycle of an ML workflow. You’ll use a few of these products today, starting with Workbench, which is the managed notebook offering.
Under the Vertex AI section of the cloud console, select “Workbench”. Note that if this is the first time you’re using Vertex AI in a project, you’ll be prompted to enable the Vertex API and the Notebooks API. So be sure to click the button in the UI to do so.

Next, select MANAGED NOTEBOOKS, and then NEW NOTEBOOK.

Under Advanced Settings you can customize your notebook by specifying the machine type and location, adding GPUs, providing custom containers, and enabling terminal access. For now, keep the default settings and just provide a name for your notebook. Then click CREATE.

You’ll know your notebook is ready when you see the OPEN JUPYTERLAB text turn blue. The first time you open the notebook, you’ll be prompted to authenticate and you can follow the steps in the UI to do so.

When you open the JupyterLab instance, you’ll see a few different notebook options. Vertex AI Workbench provides different kernels (TensorFlow, R, XGBoost, etc), which are managed environments preinstalled with common libraries for data science. If you need to add additional libraries to a kernel, you can use pip install from a notebook cell, just like you would in Colab.

Step one is complete! You’ve created your managed JupyterLab environment.
Now it’s time to get our TensorFlow code into Google Cloud. If you’ve been working in a different environment (Colab, local, etc), you can upload any code artifacts you need to your Vertex AI Workbench managed notebook, and you can even integrate with GitHub. In the future, you can do all of your development right in Workbench, but for now let’s assume you’ve been using Colab.
Colab notebooks can be exported as .ipynb files.

You can upload the file to Workbench by clicking the “upload files” icon.

When you open the notebook in Workbench, you’ll be prompted to select the kernel, which is the environment where your notebook is run. There are a few different kernels you can choose from, but since this code sample uses TensorFlow, you’ll want to select the TensorFlow 2 kernel.

After you select the kernel, any cells you execute in your notebook will run in this managed TensorFlow environment. For example, if you execute the import cell, you’ll see that you can import TensorFlow, TensorFlow Datasets, and NumPy. This is because all of these libraries are included in the Vertex AI Workbench TensorFlow 2 kernel. Unsurprisingly, if you try to execute that same notebook cell in the XGBoost kernel, you’ll see an error message since TensorFlow is not installed there.
While we could run the rest of the notebook cells manually, for models that take a long time to train, a notebook isn’t always the most convenient option. And if you’re building an application with ML, it’s unlikely that you’ll only need to train your model once. Over time, you’ll want to retrain your model to make sure it stays fresh and keeps producing valuable results.
Manually executing the cells of your notebook might be the right option when you’re getting started with a new machine learning problem. But when you want to automate experimentation at a large scale, or retrain models for a production application, a managed ML training option will make things much easier.
The quickest way to launch a training job is through the notebook execution feature, which will run the notebook cell by cell on the Vertex AI managed training service.
When you launch the training job, it’s going to run on a machine you won’t have access to after the job completes. So you don’t want to save the TensorFlow model artifacts to a local path. Instead, you’ll want to save to Cloud Storage, which is Google Cloud’s object storage, meaning you can store images, csv files, txt files, saved model artifacts. Just about anything.
Cloud storage has the concept of a “bucket” which is what holds your data. You can create them via the UI. Everything you store in Cloud Storage must be contained in a bucket. And within a bucket, you can create folders to organize your data.
Each file in Cloud Storage has a path, just like a file on your local filesystem. Except that Cloud Storage paths always start with gs://
You’ll want to update your training code so that you’re saving to a Cloud Storage bucket instead of a local path.
For example, here I’ve updated the last cell of the notebook from model.save('model_ouput").Instead of saving locally, I’m now saving the artifacts to a bucket called nikita-flower-demo-bucket that I’ve created in my project.

Now we’re ready to launch the execution.
Select the Execute button, give your execution a name, then add a GPU. Under Environment, select the TensorFlow 2.7 GPU image. This container comes preinstalled with TensorFlow and many other data science libraries.
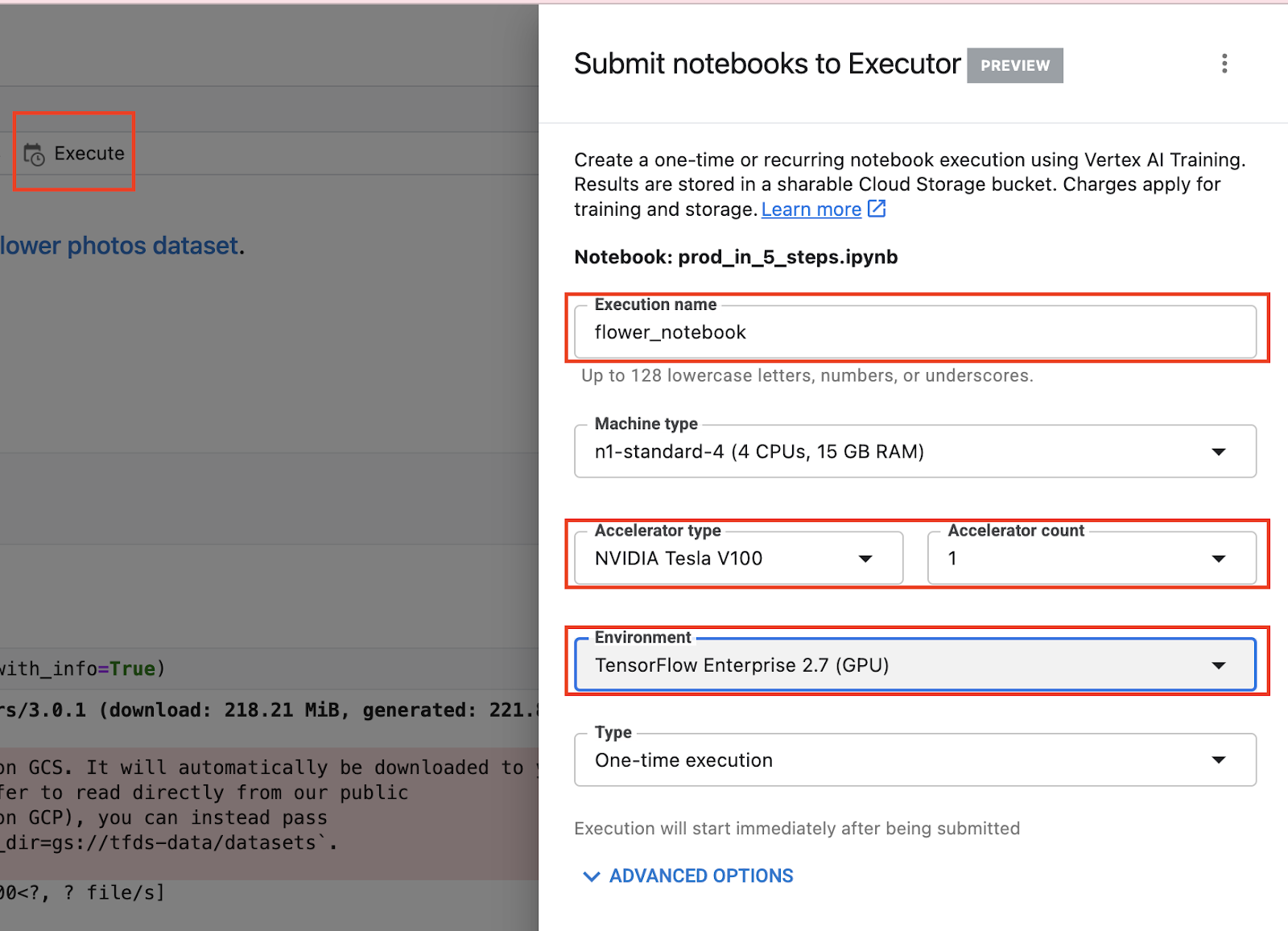
Then click SUBMIT.
You can track the status of your training job in the EXECUTIONS tab. The notebook and the output of each cell will be visible under VIEW RESULT when the job finishes and is stored in a GCS bucket. This means you can always tie a model run back to the code that was executed.

When the training completes you’ll be able to see the TensorFlow saved model artifacts in your bucket.

Now you know how to quickly launch serverless training jobs on Google Cloud. But ML is not just about training. What’s the point of all this effort if we don’t actually use the model to do something, right?
Just like with training, we could execute predictions directly from our notebook by calling model.predict. But when we want to get predictions for lots of data, or get low latency predictions on the fly, we’re going to need something more powerful than a notebook.
Back in your Vertex AI Workbench managed notebook, you can paste the code below in a cell, which will use the Vertex AI Python SDK to deploy the model you just trained to the Vertex AI Prediction service. Deploying the model to an endpoint associates the saved model artifacts with physical resources for low latency predictions.
First, import the Vertex AI Python SDK.
from google.cloud import aiplatform
Then, upload your model to the Vertex AI Model Registry. You’ll need to give your model a name, and provide a serving container image, which is the environment where your predictions will run. Vertex AI provides pre-built containers for serving, and in this example we’re using the TensorFlow 2.8 image.
You’ll also need to replace artifact_uri with the path to the bucket where you stored your saved model artifacts. For me, that was “nikita-flower-demo-bucket”. You’ll also need to replace project with your project ID.
my_model = aiplatform.Model.upload(display_name='flower-model',
artifact_uri='gs://{YOUR_BUCKET}',
serving_container_image_uri='us-docker.pkg.dev/vertex-ai/prediction/tf2-cpu.2-8:latest',
project={YOUR_PROJECT})
Then deploy the model to an endpoint. I’m using default values for now, but if you’d like to learn more about traffic splitting, and autoscaling, be sure to check out the docs. Note that if your use case does not require low latency predictions, you don’t need to deploy the model to an endpoint and can use the batch prediction feature instead.
endpoint = my_model.deploy(
deployed_model_display_name='my-endpoint',
traffic_split={"0": 100},
machine_type="n1-standard-4",
accelerator_count=0,
min_replica_count=1,
max_replica_count=1,
)
Once the deployment has completed, you can see your model and endpoint in the console

Now that this model is deployed to an endpoint, you can hit it like any other REST endpoint. This means you can integrate your model and get predictions into a downstream application.
For now, let’s just test it out directly within Workbench.
First, open a new TensorFlow notebook.

In the notebook, import the Vertex AI Python SDK.
from google.cloud import aiplatform
Then, create your endpoint, replacing project_number and endpoint_id.
endpoint = aiplatform.Endpoint(
endpoint_name="projects/{project_number}/locations/us-central1/endpoints/{endpoint_id}")
You can find your endpoint_id in the Endpoints section of the cloud Console.

You can find your Project Number on the home page of the console. Note that this is different from the Project ID.

When you send a request to an online prediction server, the request is received by an HTTP server. The HTTP server extracts the prediction request from the HTTP request content body. The extracted prediction request is forwarded to the serving function. The basic format for online prediction is a list of data instances. These can be either plain lists of values or members of a JSON object, depending on how you configured your inputs in your training application.
To test the endpoint, I first uploaded an image of a flower to my workbench instance.

The code below opens and resizes the image with PIL, and converts it into a numpy array.
import numpy as np from PIL import Image IMAGE_PATH = 'test_image.jpg' im = Image.open(IMAGE_PATH) im = im.resize((150, 150))
Then, we convert our numpy data to type float32 and to a list. We convert to a list because numpy data is not JSON serializable so we can’t send it in the body of our request. Note that we don’t need to scale the data by 255 because that step was included as part of our model architecture using tf.keras.layers.Rescaling(1./255). To avoid having to resizing our image, we could have added tf.keras.layers.Resizing to our model, instead of making it part of the tf.data pipeline.
# convert to float32 list x_test = [np.asarray(im).astype(np.float32).tolist()]
Then, we call call predict
endpoint.predict(instances=x_test).predictions
The result you get is the output of the model, which is a softmax layer with 5 units. Looks like class at index 2 (tulips) scored the highest.
[[0.0, 0.0, 1.0, 0.0, 0.0]]
Tip: to save costs, be sure to undeploy your endpoint if you’re not planning to use it! You can undeploy by going to the Endpoints section of the console, selecting the endpoint and then the Undeploy model form endpoint option. You can always redeploy in the future if needed.

For more realistic examples, you’ll probably want to directly send the image itself to the endpoint, instead of loading it in NumPy first. If you’d like to see an example, check out this notebook.
You now know how to get from notebook experimentation to deployment in the cloud. With this framework in mind, I hope you start thinking about how you can build new ML applications with notebooks and Vertex AI.
If you’re interested in learning even more about how to use Google Cloud to get your TensorFlow models into production, be sure to register for the upcoming Google Cloud Applied ML Summit. This virtual event is scheduled for 9th June and brings together the world’s leading professional machine learning engineers and data scientists. Connect with other ML engineers and data scientists and discover new ways to speed up experimentation, quickly get into production, scale and manage models, and automate pipelines to deliver impact. Reserve your seat today!

maio 25, 2022 — Posted by Nikita Namjoshi, Google Cloud Developer Advocate When you start working on a new machine learning problem, I’m guessing the first environment you use is a notebook. Maybe you like running Jupyter in a local environment, using a Kaggle Kernel, or my personal favorite, Colab. With tools like these, creating and experimenting with machine learning is becoming increasingly accessible. But …





