Posted by Jaehong Kim, Rino Lee, and Fan Yang, Software Engineers
The TensorFlow model optimization toolkit (TFMOT) provides modern optimization techniques such as quantization aware training (QAT) and pruning. Since the introduction of TFMOT, we have been continuously improving its usability and coverage. Today, we are excited to announce that we are extending the TFMOT model coverage to popular computer vision models in the TensorFlow Model Garden.
To do so, we added 8-bit QAT API support for subclassed models and custom layers, and Pruning API support. You can use these new features in the model garden, and when developing your own models as well. With this, we have showcased applying QAT and pruning to several canonical computer vision models, while accelerating the model development cycle significantly.
In this article, we will describe the technical challenges we encountered to apply QAT and pruning to the subclass models and custom layers. And show the optimized results to show the benefits from optimization techniques.
We have resolved a few technical challenges to support subclassed models and simplified the process of applying QAT API. All the new changes have already been taken care of by TFMOT and Model Garden to save users from knowing all technical details. The final user-facing API to apply QAT on a computer vision model in Model Garden is quite straightforward. By applying a few configuration changes, you can enable QAT to finetune a pre-trained model and obtain a deployable on-device model in just a few hours. There is minimal to no code change at all. Here we will talk about those challenges and how we addressed them.
The previous QAT API assumed that the model only contained built-in layers. To support nested functional models, we apply the QAT method to different parts of the model individually. For example, to apply QAT to an image classification model (M) in the Model Garden that consists of two sub modules: the backbone network (B) and the classification head (C). Here B is a nested model within M, and C is a layer. Both B and C only contain built-in layers. Instead of directly quantizing the entire classification model M, we quantize the backbone B and classification head C individually. First, we apply QAT to backbone B only. Then we connect the quantized backbone B to its corresponding classification head C to form a new classification model, and annotate C to be quantized. Finally, we quantize the entire new model, which effectively applies QAT to the annotated classification head C.
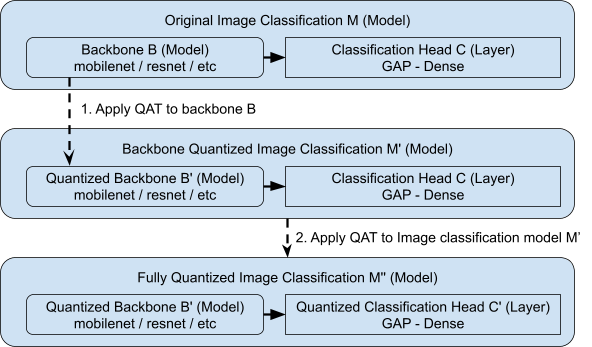 |
When the backbone network also contains custom layers rather than built-in layers, we add quantized versions of those custom layers first. For example, if the backbone network (B) or the classification head (C) of the classification model (M) also contain a custom layer called MyLayer, we create its QAT counterpart called MyLayerQuantized and wrap any built-in layers within it by a quantize wrapper API. We do this recursively if there are any nested custom layers, until all built-in layers are properly wrapped.
The remaining part after applying quantize is loading the weights from the original model because the QAT-applied model contains more parameters due to additional quantization parameters. Our current solution is variable name filtering. We have added a logic to load the weights from the original model to filtered weight from the QAT-applied model to support fine-tuning from pre-trained models.
Along with QAT, we provide two Model garden models with pruning, which is another in-training model optimization technique of MOT. Pruning sparsifies (forces a fixed portion of elements to zero) the given model’s weights during training for computation and storage efficiency.
Users can easily set pruning parameters in Model Garden configs. For better pruned model quality, starting pruning from a pre-trained dense model and careful tuning pruning schedule over training steps are well-known techniques. Both are available in Model Garden Pruning configs.
This work also provides an example of nested functional layer support in pruning. The way we used here using get_prunable_weight() is also applicable to any other Keras models with custom layers.
With the provided two Model Garden Pruning configs, users can quickly demonstrate pruning to ResNet50 and MobileNetV2 models for image classification. Understanding the practical usage of Pruning API and the pruning process by monitoring tensorboard are also another takeaways of this work.
We support two tasks, image classification and semantic segmentation. Specifically, for QAT in image classification, we support the common MobileNet family, including MobileNetV2, MobileNetV3 (large), Multi-Hardware MobileNet (AVG), and ResNet (through quantization on common building blocks such as InvertedBottleneckBlockQuantized and BottleneckBlockQuantized). For QAT in semantic segmentation, we support MobileNetV2 backbone with DeepLab V3/V3+. For Pruning in image classification we support MobileNetV2 and ResNet. Please refer to the documentations of QAT and pruning for more details.
Using QAT with Model Garden is simple and straightforward. First, we train a floating point model following the standard process of training models using Model Garden. After training converges, we take the best checkpoint as our starting point to apply QAT, analogous to a finetuning stage. Soon, we will obtain a model that is more quantization friendly. Such model then can be converted to a TFLite model for on-device deployment.
For image classification, we evaluate the top-1 accuracy on the ImageNet validation set. As shown in Table 1, QAT model consistently outperforms PTQ model by a large margin, which achieves comparable latency. Notably, on models where PTQ fails to produce reasonable results (MobileNetV3), QAT is still capable of generating a strong quantized model with negligible accuracy drop.
Table 1. Accuracy and latency comparison of supported models for ImageNet classification. Latency is measured on a Samsung Galaxy S21 using 1-thread CPU. FP32 refers to the unquantized floating point TFLite model. PTQ INT8 refers to full integer post-training quantization. QAT INT8 refers to the quantized QAT model.
* PTQ fails to quantize MobileNet V3 properly due to hard-swish activation, thus leading to low accuracy.
We have a similar observation on semantic segmentation: PTQ introduces 1.3 mIoU drop, compared to FP32 model, while QAT model minimizes the drop to just 0.7 and maintains comparable latency. On average, we expect QAT will only introduce 0.5 top-1 accuracy drop for image classification and less than 1 mIoU drop for semantic segmentation.
Table 2. Accuracy and latency comparison of a MobileNet v2 + DeepLab v3 on Pascal VOC segmentation. Latency is measured on a Samsung Galaxy S21 using 1-thread CPU. FP32 refers to the unquantized floating point TFLite model. PTQ INT8 refers to full integer post-training quantization. QAT INT8 refers to the quantized QAT model.
We support ResNet50 and MobileNet V2 for image classification. Pretrained dense models for each task are generated using the Model Garden training configs. The pruned model can be converted to the TFLite model. By simply setting a flag for sparsity in TFLite conversion, one can get a benefit of model size reduction through sparse data format.
For image classification, we again evaluate the top-1 accuracy on the ImageNet validation set, as well as the size of converted TFLite models. As sparsity level increases, the model size becomes more compact but accuracy degrades. The accuracy impact in high sparsity is more severe in parameter-efficient models like MobileNetV2.
Table 3. Accuracy and model size comparison of ResNet-50 and MobileNet v2 for ImageNet classification. Model size is measured by disk usage of saved TFLite models. Dense refers to the unpruned TFLite model, and 50% sparsity refers to the TFLite model with all prunable layers’ weights randomly pruned 50% of their elements.
We have presented an extension to TFMOT that offers QAT and pruning support for computer vision models in Model Garden. We highlight the ease of use and outstanding trade-offs about maintaining accuracy while keeping low latency or small model size.
While we believe this is a simple and user-friendly solution to enable QAT and pruning, we know this is just the beginning of streamlined works to provide even better usability.
Currently, supported tasks are limited to image classification and semantic segmentation. We will continue to add more support to other tasks, such as object detection and instance segmentation. We will also add more models, such as transformer based models, and improve the usability of TFMOT and Model Garden’s API. Thanks for your interest in this work.
We would like to thank everyone who contributed to this work, including Model Garden, Model Optimization, and our collaborators from Research. Special thanks to David Rim (emeritus), Ethan Kim (emeritus) from the Model Optimization team; Abdullah Rashwan, Xianzhi Du, Yeqing Li, Jaeyoun Kim, Jing Li from the Model Garden team; Yuqi Li from the on-device ML team.

יוני 09, 2022 — Posted by Jaehong Kim, Rino Lee, and Fan Yang, Software Engineers The TensorFlow model optimization toolkit (TFMOT) provides modern optimization techniques such as quantization aware training (QAT) and pruning. Since the introduction of TFMOT, we have been continuously improving its usability and coverage. Today, we are excited to announce that we are extending the TFMOT model coverage to popular…





