Posted by Zhi An Ng and Marat Dukhan, Google
XNNPack is the default TensorFlow Lite CPU inference engine for floating-point models, and delivers meaningful speedups across mobile, desktop, and Web platforms. One of the optimizations employed in XNNPack is repacking the static weights of the Convolution, Depthwise Convolution, Transposed Convolution, and Fully Connected operators into an internal layout optimized for inference computations. During inference, the repacked weights are accessed in a sequential pattern that is friendly to the processors’ pipelines.
The inference latency reduction comes at a cost: repacking essentially creates an extra copy of the weights inside XNNPack. When the TensorFlow Lite model is memory-mapped, the operating system eventually releases the original copy of the weights and makes the overhead disappear. However, some use-cases require creating multiple copies of a TensorFlow Lite interpreter, each with its own XNNPack delegate, for the same model. As the XNNPack delegates belonging to different TensorFlow Lite interpreters are unaware of each other, every one of them creates its own copy of repacked weights, and the memory overhead grows linearly with the number of delegate instances. Furthermore, since the original weights in the model are static, the repacked weights in XNNPack are also the same across all instances, making these copies wasteful and unnecessary.
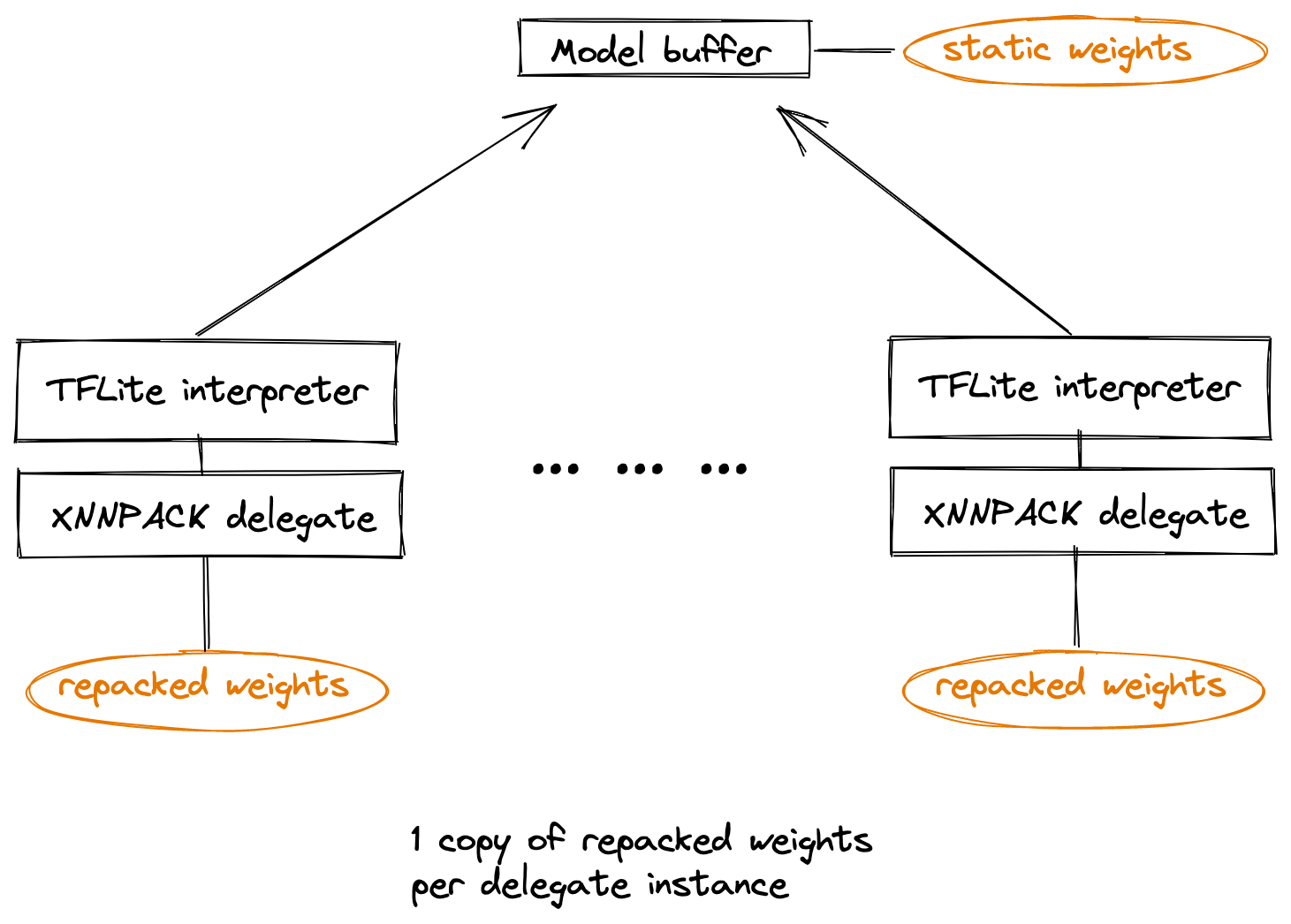
Weights cache is a mechanism that allows multiple instances of the XNNPack delegate accelerating the same model to optimize their memory usage for repacked weights. With a weights cache, all instances use the same underlying repacked weights, resulting in a constant memory usage, no matter how many interpreter instances are created. Moreover, elimination of duplicates due to weights cache may improve performance through increased efficiency of a processor’s cache hierarchy. Note: the weights cache is an opt-in feature available only via the C++ API.

The chart below shows the high water mark memory usage (vertical axis) of creating multiple instances (horizontal axis). It compares the baseline, which does not use weights cache, with using weights cache with soft finalization. The peak memory usage when using weights cache grows much slower with respect to the number of instances created. For this example, using weights cache allows you to double the number of instances created with the same peak memory budget.

The weights cache object is created by the TfLiteXNNPackDelegateWeightsCacheCreate function, and passed to the XNNPack delegate via the delegate options. XNNPack delegate will then use the weights cache to store repacked weights. Importantly, the weights cache must be finalized before any inference invocation.
// Example demonstrating how to create and finalize a weights cache.
std::unique_ptr<tflite::Interpreter> interpreter;
TfLiteXNNPackDelegateWeightsCache* weights_cache =
TfLiteXNNPackDelegateWeightsCacheCreate();
TfLiteXNNPackDelegateOptions xnnpack_options =
TfLiteXNNPackDelegateOptionsDefault();
xnnpack_options.weights_cache = weights_cache;
TfLiteDelegate* delegate =
TfLiteXNNPackDelegateCreate(&xnnpack_options);
if (interpreter->ModifyGraphWithDelegate(delegate) != kTfLiteOk) {
// Static weights will be packed and written into weights_cache.
}
TfLiteXNNPackDelegateWeightsCacheFinalizeHard(weights_cache);
// Calls to interpreter->Invoke and interpreter->AllocateTensors must
// be made here, between finalization and deletion of the cache.
// After the hard finalization any attempts to create a new XNNPack
// delegate instance using the same weights cache object will fail.
TfLiteXNNPackWeightsCacheDelete(weights_cache);
There are two ways to finalize a weights cache, and in the example above we use TfLiteXNNPackDelegateWeightsCacheFinalizeHard which performs hard finalization. The hard finalization has the least memory overhead, as it will trim the memory used by the weights cache to the absolute minimum. However, no new delegates can be created with this weights cache object after the hard finalization - the number of XNNPack delegate instances using this cache is fixed in advance. The other kind of finalization is a soft finalization. Soft finalization has higher memory overhead, as it leaves sufficient space in the weights cache for some internal bookkeeping. The advantage of the soft finalization is that the same weights cache can be used to create new XNNPack delegate instances, provided that the delegate instances use exactly the same model. This is useful if the number of delegate instances is not fixed or known beforehand.
// Example demonstrating soft finalization and creating multiple
// XNNPack delegate instances using the same weights cache.
std::unique_ptr<tflite::Interpreter> interpreter;
TfLiteXNNPackDelegateWeightsCache* weights_cache =
TfLiteXNNPackDelegateWeightsCacheCreate();
TfLiteXNNPackDelegateOptions xnnpack_options =
TfLiteXNNPackDelegateOptionsDefault();
xnnpack_options.weights_cache = weights_cache;
TfLiteDelegate* delegate =
TfLiteXNNPackDelegateCreate(&xnnpack_options);
if (interpreter->ModifyGraphWithDelegate(delegate) != kTfLiteOk) {
// Static weights will be packed and written into weights_cache.
}
TfLiteXNNPackDelegateWeightsCacheFinalizeSoft(weights_cache);
// Calls to interpreter->Invoke and interpreter->AllocateTensors can
// be made here, between finalization and deletion of the cache.
// Notably, new XNNPack delegate instances using the same cache can
// still be created, so long as they are used for the same model.
std::unique_ptr<tflite::Interpreter> new_interpreter;
TfLiteDelegate* new_delegate =
TfLiteXNNPackDelegateCreate(&xnnpack_options);
if (new_interpreter->ModifyGraphWithDelegate(new_delegate) !=
kTfLiteOk)
{
// Repacked weights inside of the weights cache will be reused,
// no growth in memory usage
}
// Calls to new_interpreter->Invoke and
// new_interpreter->AllocateTensors can be made here.
// More interpreters with XNNPack delegates can be created as needed.
TfLiteXNNPackWeightsCacheDelete(weights_cache);
With the weights cache, using XNNPack for batch inference will reduce memory usage, leading to better performance. Read more about how to use weights cache with XNNPack at the README and report any issues at XNNPack's GitHub page.
To stay up to date, you can read the TensorFlow blog, follow twitter.com/tensorflow, or subscribe to youtube.com/tensorflow. If you’ve built something you’d like to share, please submit it for our Community Spotlight at goo.gle/TFCS. For feedback, please file an issue on GitHub or post to the TensorFlow Forum. Thank you!

มิถุนายน 06, 2565 — Posted by Zhi An Ng and Marat Dukhan, GoogleXNNPack is the default TensorFlow Lite CPU inference engine for floating-point models, and delivers meaningful speedups across mobile, desktop, and Web platforms. One of the optimizations employed in XNNPack is repacking the static weights of the Convolution, Depthwise Convolution, Transposed Convolution, and Fully Connected operators into an internal l…





