A guest post by Charles Gaillard, Mindee
Optical Character Recognition (OCR) refers to technologies capable of capturing text elements from images or documents and converting them into a machine-readable text format. If you want to learn more on that topic, this article is a good introduction.
At Mindee, we have developed an open-source Python-based OCR called DocTR, however we also wanted to deploy it in the browser to ensure that it was accessible to all developers - especially as ~70% developers choose to use JavaScript.
We managed to achieve this using the TensorFlow.js API, which resulted in a web demo that you can now try for yourself using images of your own.
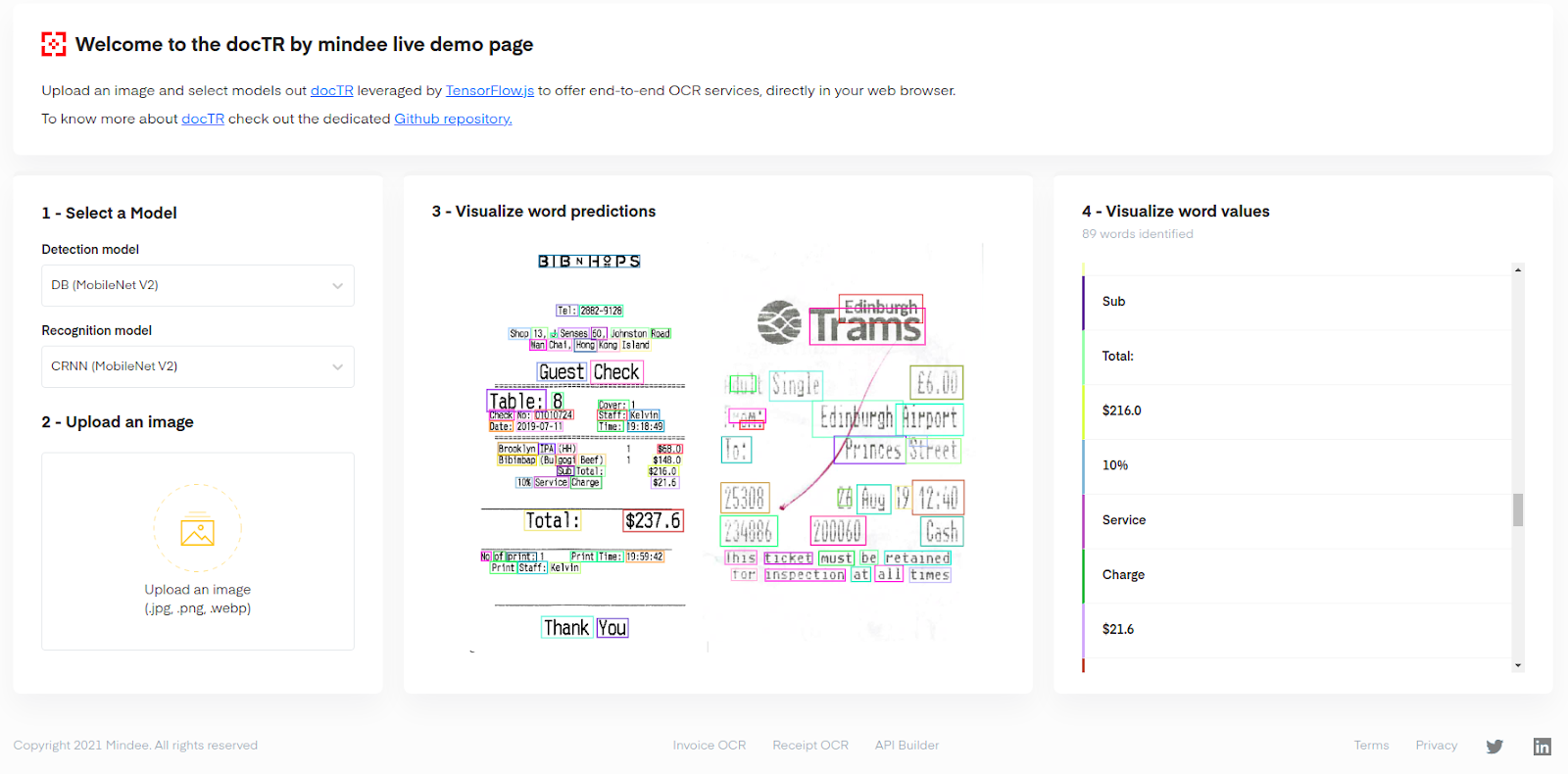
 |
| The demo interface with a picture of 2 receipts being parsed by the OCR: 89 words were found here |
This demo is designed to be very simple to use and run quickly on most computers, therefore we provided a single pretrained model that we trained with a small (512 x 512) input size to save memory. Images are resized to be squares, so it generalizes well to most of the documents which have an aspect ratio close to 1: cards, smaller receipts, tickets, A4, etc. For rectangles with a very high aspect ratio, segmentation results might not be as good because we don’t preserve the aspect ratio (with padding) at the text detection step. It is optimized to work on documents with a significant word size (for example receipts, cards, etc). Keep in mind that these models have been designed to offer performance while running in the browser. Hence, performance might not be optimal on documents that have a very small writing size vs the size of the document or images with a very high aspect ratio.
OCR models can be divided into 2 parts: A detection model and a text recognition model. In DocTR, the detection model is a CNN (convolutional neural network) which segments the input image to find text areas, then text boxes are cropped around each detected word and sent to a recognition model. The second model is a convolutional recurrent neural network (CRNN), which extracts features from word-images and then decodes the sequence of letters on the image with recurrent layers (LSTM).
 |
| Global architecture of the OCR model used in this Demo |
We have different architectures implemented in DocTR, but we chose a very light one for use on the client side as device hardware can change from person to person. Here we used a mobilenetV2 backbone with a DB (Differentiable Binarization) head. The implementation details can be found in the DocTR Github. We trained this model with an input size of (512, 512, 3) to decrease latency and memory usage. We have a private dataset composed of 130,000 annotated documents that was used to train this model.
The recognition model we used is also our lighter architecture: a CRNN (convolutional recurrent neural network) with a mobilenetV2 backbone. More information on this architecture can be found here. It is basically composed of the first half of the mobilenetV2 layers to extract features and it is followed by 2 bi-LSTMs to decode visual features as character sequences (words). It uses the CTC loss, introduced by Alex Graves, to decode a sequence efficiently. We have an input size of (32, 128, 3) for word images in this model, and we use padding to preserve the aspect ratio of crops. It is trained on our private dataset, composed of 11 millions text boxes extracted from different documents. This dataset has a wide variety of fonts, since it is composed of documents which come from many different data sources. We used data augmentation so that it generalizes well on different fonts, backgrounds, and renderings. It should also give decent results on handwritten text as long as it is human-readable.
As our model was originally implemented using TensorFlow, Python conversion was required to run the resulting models in the web browser at scale. To do this we exported a tensorflow SavedModel for each Python model trained and used the tensorflowjs_converter command line tool to quickly convert our saved models to the TensorFlow.js JSON format required for execution in the browser.
The resulting converted models were then integrated into our React.js front end application that powered the user interface of the demo. More precisely, we used MUI to design the components of the interface for our in-house front-end SDK react-mindee-js (which provides computer vision tools) and OpenCV.js for the detection model post processing. This post processing step took the raw binarized segmentation map and converted it to a list of polygons with OpenCV.js functions. We could then crop those boxes from the source image to finally obtain word images ready to be sent to the recognition model.
We had to manage the tradeoff between speed and performance efficiently. OCR models are quite slow because you have 2 tasks (text areas segmentation + words recognition) that can't be parallelized, so we had to use lightweight models to ensure speedy execution on most devices.
On an modern computer with an RTX 2060 and an i7 9th Gen, the detection task takes around 750 milliseconds per image, and the recognition model around 170 milliseconds per batch of 32 crops (words) with the WebGL backend, benchmarked with the TensorFlow.js benchmarking tool.
Wrapping up the 2 models and the vision operations (detection post processing), the end-to-end OCR runs in less than 2 seconds on small documents (less than 100 words) and the prediction time can only take a few seconds more to run on very dense documents with a lot of words.

|
| A screenshot of the demo interface with a very dense old A4 document being parsed by the OCR: 738 words are identified. |
This demo powered by TensorFlow.js is a way to give access to an online, relatively quick and robust document OCR to almost everyone, which is one of the first of its kind powered by TensorFlow.js entirely in the browser.
As we are executing the model on the client side, exact performance will vary depending on the hardware of the device it is run on. However the goal here is more to demonstrate that even complex and state-of-the-art deep learning models can be deployed in the browser and run on almost every machine in an efficient manner that can be very useful, especially for potentially sensitive document information, where you do not want to send the document to the cloud for analysis.
We are excited to offer this solution for all to use, and keen to follow the future of the Web ML industry, where things will no doubt get faster with time as new web standards like WebGPU become mainstream and enabled by default on modern web browsers.
June 07, 2022 — A guest post by Charles Gaillard, MindeeIntroduction Optical Character Recognition (OCR) refers to technologies capable of capturing text elements from images or documents and converting them into a machine-readable text format. If you want to learn more on that topic, this article is a good introduction. At Mindee, we have developed an open-source Python-based OCR called DocTR, however we also …





