https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEhPgzXuw86PD1HNCCIhrah5h-OLyLNYYyTOnYclaxK5V-nxZvM4VD5qPlqm04cyUYPI8XMoP22aQ3rtz4TyySQIDNleKUDAnbf94PrHY_yXA4OX0LZyI_ljw0rXipCv5Y419LW_cmNt0w0lzep5GfJ5KzUaR23wsXqpewIRKiyRDFbO-2HffMx6p2LX/w660-h196/Tensorflow-Jax-on-the-Web-01.png

Posted by Andreas Steiner and Marc van Zee, Google Research, Brain Team
Introduction
In this blog post we demonstrate how to convert and run Python-based JAX functions and Flax machine learning models in the browser using TensorFlow.js. We have produced three examples of JAX-to-TensorFlow.js conversion each with increasing complexity:
- A simple JAX function
- An image classification Flax model trained on the MNIST dataset
- A full image/text Vision Transformer (ViT) demo, which was used for the Google AI blog post Locked-Image Tuning: Adding Language Understanding to Image Models (a preview of the demo is shown in Figure 1 below)
For each example, there are Google Colab notebooks you can use to try the JAX-to-TensorFlow.js conversion yourself.
 |
| Figure 1. TensorFlow.js model matching user-provided text prompts to a precomputed image embedding (try it out yourself). See Example 3: LiT Demo below for implementation details. |
Background: JAX and TensorFlow.js
JAX is a NumPy-like library developed by Google Research for high performance computing. It uses
XLA to compile programs optimized for GPUs and
TPUs. Flax is a popular neural network library built on top of JAX. Researchers have been using JAX/Flax to train very large models with billions of parameters (such as
PaLM for language understanding and generation, or
Imagen for image generation), making full use of modern hardware. If you're new to JAX and Flax, start with
this JAX 101 tutorial and
this Flax Getting Started example.
TensorFlow started as a library for ML towards the end of 2015 and has since become a rich ecosystem that includes tools for productionizing ML pipelines (
TFX), data visualization (
TensorBoard), deploying ML models to edge devices (
TensorFlow Lite), and devices running on a web browser or any device capable of executing JavaScript (
TensorFlow.js). Models developed in JAX or Flax can tap into this rich ecosystem by first converting such a model to the TensorFlow
SavedModel format, and then using the same tooling as if they had been developed in TensorFlow natively.
This is now made even easier for TensorFlow.js through the new Python API —
tfjs.converters.convert_jax() — which allows users to convert a JAX model written in Python to a web format (
.json) directly, so that the model can be used in the browser with Tensorflow.js.
To learn how to perform JAX-to-TensorFlow.js conversion, check out the three examples below.
Example 1: Converting a simple JAX function
In this introductory example, you’ll convert a few simple JAX functions using
converters.convert_jax().
Internally, this function does the following:
- It converts to the Tensorflow SavedModel format, which contains a complete TensorFlow program, including trained parameters (that is,
tf.Variables) and computation. - Then, it constructs a TensorFlow.js model from that SavedModel (refer to Figure 2 for more details).
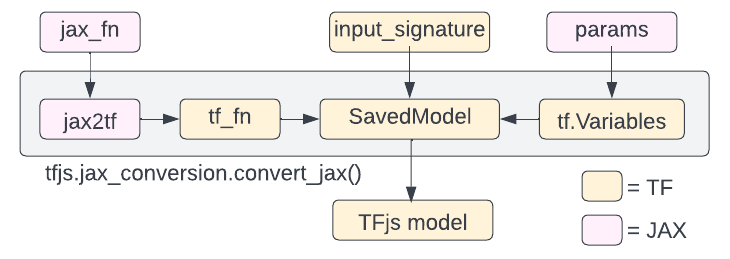 |
| Figure 2. High-level visualization of the conversion steps inside converters.convert_jax(), which converts a JAX function to a Tensorflow.js model. |
To convert a Flax model to TensorFlow.js, you need a few things:
- A function that runs the forward pass of the model.
- The model parameters (this is usually a dict-like structure).
- A specification of the shapes and dtypes of the inputs to the function.
The following examples uses a single parameter weight and implements a function prod, which multiplies the input with the parameter (in a real example, params will contain the all weights of the modules used in the neural network):
|
def prod(params, xs):
return params['weight'] * xs
|
Let's call this function with some values and verify the output makes sense:
|
params = {'weight': np.array([0.5, 1])}
# This represents a batch of 3 inputs, each of length 2.
xs = np.arange(6).reshape((3, 2))
prod(params, xs)
|
This gives the following output, where each batch element is element-wise multiplied by
[0.5, 1]:
|
[[0. 1.]
[1. 3.]
[2. 5.]]
|
Next, let's convert this to TensorFlow.js using convert_jax and use the helper function get_tfjs_predict_fn (which can be found in the Colab), allowing us to verify that the outputs for the JAX function and the web model match. (Note: this helper function will only work in Colab, as it uses some tooling to run the web model using Javascript.)
|
tfjs.converters.convert_jax(
prod,
params,
input_signatures=[tf.TensorSpec((3, 2), tf.float32)],
model_dir=model_dir)
tfjs_predict_fn = get_tfjs_predict_fn(model_dir)
tfjs_predict_fn(xs) # Same output as JAX.
|
Dynamic shapes are supported as usual in Tensorflow by passing the value
None for the dynamic dimensions in
input_signature. Additionally, one should pass the argument
polymorphic_shapes specifying names for dynamic dimensions. Note that
polymorphism is a term coming from type theory, but here we use it to mean that the function works for multiple related shapes, e.g., for multiple batch sizes. This is necessary for shape checking in the JAX function (see
Colab for more examples, and
here for more documentation on this notation).
|
tfjs.converters.convert_jax(
prod,
params,
input_signatures=[tf.TensorSpec((None, 2), tf.float32)],
polymorphic_shapes=['(b, 2)')],
model_dir=model_dir)
tfjs_predict_fn = get_tfjs_predict_fn(model_dir)
tfjs_predict_fn(np.array([[1., 2.]])) # Outputs: [[0.5, 2. ]]
|
Example 2: MNIST Model

Let's use the same conversion code snippet from before, but this time we'll use TensorFlow.js to run a real ML model. Flax provides a
Colab example of an MNIST classifier that we'll use as a starting point.
After cloning the repository, the model can be trained using:
|
train_ds, test_ds = train.get_datasets()
state = train.train_and_evaluate(config, workdir=f'./workdir')
|
This yields a
state.apply_fn that can be used to compute logits for input images. Note that the function expects the first argument to be the model weights
state.params. Given a batch of input images shaped [
batch_size, 28, 28, 1], this will produce the logits for the probability distribution over the ten labels for every model (shaped [
batch_size, 10]).
|
logits = state.apply_fn({'params': state.params}, imgs)
|
The MNIST model's
state.apply_fn() is then converted exactly the same way as in the previous section – after all, it's a
pure function that takes
params and
images as inputs and returns
logits:
|
tfjs.converters.convert_jax(
state.apply_fn,
{'params': state.params},
input_signatures=[tf.TensorSpec((1, 28, 28, 1), tf.float32)],
model_dir=tfjs_model_dir,
)
|
On the JavaScript side, you load the model asynchronously, showing a simple progress update in the
status text, making sure to give some feedback while the model weights are transferred:
|
tf.loadGraphModel(modelDir + '/model.json', {
onProgress: p => status.innerText = `loading model: ${Math.round(p*100)}%`
})
|
A minimal UI is loaded from
this snippet, and in the callback function you call the TensorFlow.js model and output the predictions. The function parameter
img is a
Uint8Array of length
28*28, which is first converted to a TensorFlow.js
tf.tensor, before computing the model outputs, and converting them to probabilities via the
tf.softmax() function. The output values from the computation are then waited for synchronously by calling
.dataSync(), and converted to JavaScript arrays before they're displayed.
|
ui.onUpdate(img => {
const imgs = tf.tensor(img).cast('float32').reshape([1, 28, 28, 1])
const logits = model.predict(imgs)
const preds = tf.softmax(logits)
const { values, indices } = tf.topk(preds, 10)
ui.showPreds([...values.dataSync()], [...indices.dataSync()])
})
|
The Colab then starts a webserver and tunnels the port so you can scan a QR code on a mobile phone and directly connect to the demo. Even though the training reports around 99.1% accuracy on the test set, you'll see that the model can easily be fooled with digits that are easy to recognize for the human eye, but hard for a model that has only seen digits from the MNIST dataset (Figure 3).
 |
Figure 3. Our model from the Colab with 99.1% accuracy on the MNIST test dataset is still surprisingly bad at recognizing hand-written digits. On the left, the model predicts all kinds of digits instead of "one". On the right side, the "one" is drawn more like the data from the training set.
Example 3: LiT DemoWriting a more realistic application with a TensorFlow.js model is a bit more involved. This section goes through the main steps that were used to create the demo app from the Google AI blog post Locked-Image Tuning: Adding Language Understanding to Image Models. Refer to that post for technical details on the implementation of the ML model. Also make sure to check out the final LiT Demo. Adapting the modelBefore starting to implement an ML demo, it's a good moment to think carefully about the different options and their respective strengths and weaknesses.
At a high level, you have two options: running the ML model on server-side infrastructure, or running the ML model on the edge (i.e. on the visiting user's device). - Running a model on a server has the advantage that it can use exactly the same framework / code that was used to develop the model. There are libraries like Streamlit or Gradio that make it very easy to quickly build interactive web apps around such centrally-hosted models. The servers running the model can be rather powerful, using lots of RAM and accelerators to run state-of-the-art ML models in near-real time, and such a website can be loaded even by the smallest mobile device.
- Running the demo on-device puts a limit on the size of the model that you can use, but comes with convincing advantages:
- No data is ever sent off the device, which is desirable both for privacy reasons and to bring down latency.
- Free scaling: For instance, a normal webserver (such as one running on GitHub Pages) can serve hundreds or thousands of users simultaneously free of charge. And running a powerful model on server-side infrastructure at this scale would be very expensive (massive compute is not cheap).
The model you use for the demo consists of two parts: an image encoder, and a text encoder (see Figure 4).
For computing image embeddings you use a large model, and for text embeddings—a small model. To make the demo run faster and produce better results, the expensive image embeddings are pre-computed, so the Tensorflow.js model only needs to compute the text embeddings and then compare the image and text embeddings to compute similarities. 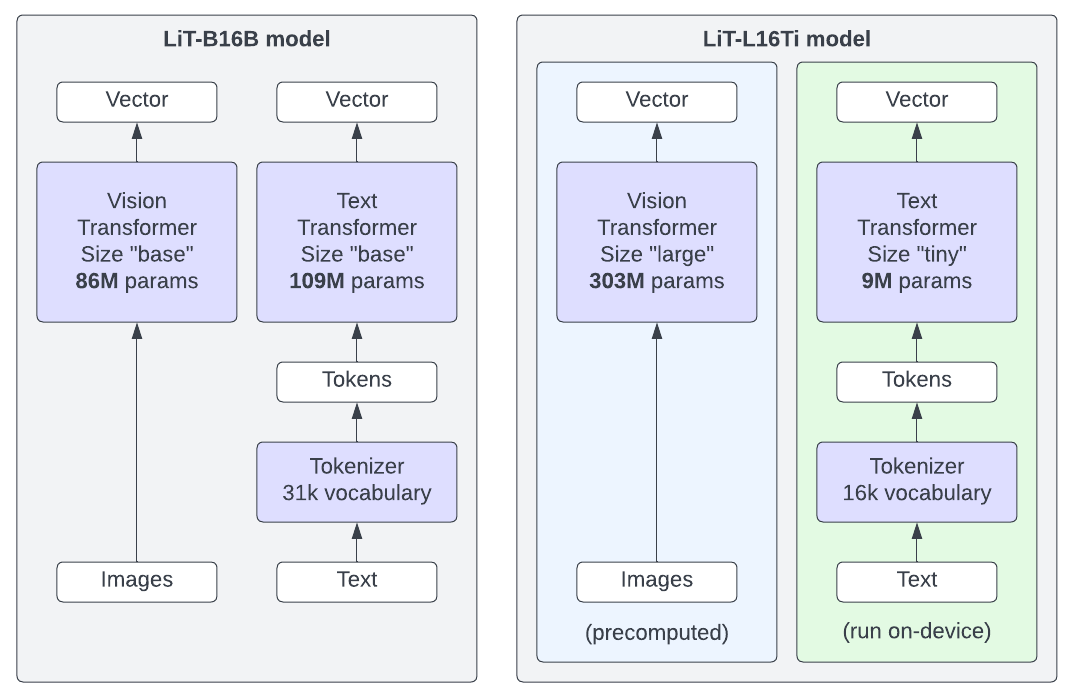 | | Figure 4. Image/text models like LiT (or CLIP) consist of two encoders that can be used separately to create vector representations of images and texts. Usually both image and text encoders are of similar size (LiT-B16B model, left image). For the demo, we precompute image embeddings using a large image encoder, and then run inference on the text on-device using a tiny text encoder (LiT-L16Ti model, right image). |
For the demo, we now get those powerful ViT-Large image representations for free, because we can precompute them for all demo images. This allows us to make for a compelling demo with a limited compute budget. In addition to the "tiny" text encoder, we have also prepared a "small" text encoder for the same image embeddings (LiT-L16S), which performs a bit better, but uses more bandwidth to download the model weights, and requires more GPU memory to run on-device. We have evaluated the different models with the code from this Colab:
| Image encoder | Text encoder | Zeroshot performance | Model | Params | FLOPs | Params | FLOPs | CIFAR-100 | ImageNet | LiT-B16B | 86M (344 MB) | 36B | 109M (436 MB) | 2.7B | 79.2% | 71.7% | LiT-L16S ("small" text encoder) | 303M (1.2 GB) | 123B | 28M (111 MB) | 0.7B | 75.8% | 60.7% | LiT-L16Ti ("tiny" text encoder) | 303M (1.2 GB) | 123B | 9M (36 MB) | 0.2B | 73.2% | 53.4% |
Note though that the "zeroshot performance" should only be taken as a proxy. In the end, the model performance needs to be good enough for the demo, and in this case our manual testing showed that even the tiny text transformer was able to compute similarities good enough for the demo. Next, we tested the performance of the tiny and small text encoders using this TensorFlow.js benchmark tool on different platforms (using the "custom model" option, and benchmarking 5x16 tokens on the WebGL backend):
| LiT-L16T ("tiny" text encoder) - benchmark | LiT-L16S ("small" text encoder) - benchmark |
| Load time | Warmup | Average/10 | Peak memory | Load time | Warmup | Average/10 | Peak memory | MacBook Pro (Intel i7 2.6GHz / Radeon Pro 5300M) | 1.1s | 0.15s | 0.12s | 33.9 MB | 3.9s | 0.8s | 0.8s | 122 MB | iPad Air (4th gen) | 1.3s | 0.6s | 0.5s | 33.9 MB | 2.7s | 2.4s | 2.5s | 141 MB | Samsung S21 G5 (cell phone) | 2.0s | 1.3s | 1.1s | 33.9 MB | - | - | - | - |
Note that the results for the model with the "small" text encoder are missing for "Samsung S21 G5" in the above table because the model did not fit into memory. In terms of performance, the model with the "tiny" text encoder produces results within approximately 0.1-1 seconds, which still feels quite responsive, even on the smallest platform tested.
The Lit-LiT web app
Preparing the model for this application is a bit more complicated, because we need not only convert the text transformer model weights, but also a matching tokenizer, and the precomputed image embeddings. The Colab loads a LiT model and showcases how to use it, and then prepares contents needed by the web app:
- The tiny/small text encoder converted to TensorFlow.js and the matching tokenizer vocabulary.
- Images in JPG format, as seen by the model (in particular, this means a fixed 224x224 pixel crop)
- Pre-computed image embeddings (since the converted model will only be able to compute embeddings for the texts).
- A selection of example prompts for every image. The embeddings of these prompts are also precomputed to allow to show precomputed answers if the prompts are not modified.
These files are prepared inside the data/ directory and then downloaded as a ZIP file. This file can then be uploaded to a web hosting, from where it is loaded by the web app (for example on GitHub Pages: vision_transformer/lit/data).
The code for the entire client-side application is available on GitHub: https://github.com/google-research/big_vision/tree/main/big_vision/tools/lit_demo/.
The application is built using Lit web components. The main index.html declares the demo application: |
|
<lit-demo-app></lit-demo-app>
|
This web component is defined in
lit-demo-app.ts in the
src/components subdirectory, next to all the other web components (image carousel, model controls etc).
For the actual computation of image/text similarities, the component
image-prompts.ts calls functions from the module
src/lit_demo/compute.ts, which wraps all the TensorFlow.js specific code.
|
export class Model {
/** Tokenizes text. */
tokenize(texts: string[]): tf.Tensor { /* ... */ }
/** Computes text embeddings. */
embed(tokens: tf.Tensor): tf.Tensor {
return this.model!.execute({inputs: tokens}) as tf.Tensor;
}
/** Computes similarities texts / pre-computed image embeddings. */
computeSimilarities(texts: string[], imgidxs: number[]) {
const textEmbeddings = this.embed(this.tokenize(texts));
const imageEmbeddingsTransposed = tf.transpose(
tf.concat(imgidxs.map(idx => tf.slice(this.zimgs!, idx, 1))));
return tf.matMul(textEmbeddings, imageEmbeddingsTransposed);
}
/** Applies softmax to `computeSimilarities()`. */
computeProbabilities(texts: string[], imgidx: number): number[] {
const sims = this.computeSimilarities(texts, [imgidx]);
const row = tf.squeeze(tf.slice(tf.transpose(sims), 0, 1));
return [...tf.softmax(tf.mul(this.def!.temperature, row)).dataSync()];
}
}
|
The parent directory of the
data/ exported by the Colab above is referenced via the baseUrl in the file
src/lit/constants.ts. By default it refers to the models from the official demo. When replacing the
baseUrl with a different server, make sure to enable
cross origin resource sharing.
In addition to the complete application, it's also possible to export the functional parts without the UI as a single JavaScript file that can be linked statically. See the file
playground.html as an example, and refer to the instructions in
README.md for how to compile the entire application or the functional part before deploying the application.
|
<!-- Loads global symbol `lit`. -->
<script src="exports_bin.js"></script>
<script>
async function demo() {
lit.setBaseUrl('https://google-research.github.io/vision_transformer/lit');
const model = new lit.Model('tiny');
await model.load();
console.log(model.computeProbabilities(['a dog', 'a cat'], /*imgIdx=*/1);
}
demo();
</script>
|
Conclusion
In this article you learned how to convert JAX functions and Flax models into the TensorFlow.js format that can be executed in a browser or on devices capable of running JavaScript.
The first example demonstrated how to convert a JAX function to a TensorFlow.js model, which can then be loaded in Colab for verification, or run on any device with a modern web browser – this is an exactly the same conversion that can be applied to more complex Flax models. The second example showed how to train an ML model in Colab, and test it interactively on a mobile phone.The third example provided a
full template for running an on-device ML model (check out the
live demo). We hope that this application can serve you as a good starting point for your own client-side demos using JAX models with TensorFlow.js.










