https://blog.tensorflow.org/2022/10/accelerating-tensorflow-on-intel-data-center-gpu-flex-series.html
https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEiggAhVjGLVpN-zQt2-nd7tSvZRLJW0qVeCvD7QMNuyTrH3IgCTZO0IWm-hq4wZtwZVdpiAHwi_NW3jjX1nBRwr16bVzfuRUyophmVIquDNkkvQ2bl3UMOG5viSeMG9HHl-xBO86xKg8agcGvKM5uqe9T9DGm8d2EYvuddIyUc6XlG-T-M6qVS-pIAj/s1600/Figure-2_PluggableDevice-diagram.png
Posted by Jianhui Li, Zhoulong Jiang, Yiqiang Li from Intel, Penporn Koanantakool from Google
The ubiquity of deep learning motivates development and deployment of many new AI accelerators. However, enabling users to run existing AI applications efficiently on these hardware types is a significant challenge. To reach wide adoption, hardware vendors need to seamlessly integrate their low-level software stack with high-level AI frameworks. On the other hand, frameworks can only afford to add device-specific code for initial devices already prevalent in the market – a chicken-and-egg problem for new accelerators. Inability to upstream the integration means hardware vendors need to maintain their customized forks of the frameworks and re-integrate with the main repositories for every new version release, which is cumbersome and unsustainable.
Recognizing the need for a modular device integration interface in TensorFlow, Intel and Google co-architected PluggableDevice, a mechanism that lets hardware vendors independently release plug-in packages for new device support that can be installed alongside TensorFlow, without modifying the TensorFlow code base. PluggableDevice has been the only way to add a new device to TensorFlow since its release in TensorFlow 2.5. To bring feature-parity with native devices, Intel and Google also added a profiling C interface to TensorFlow 2.7. The TensorFlow community quickly adopted PluggableDevice and has been regularly submitting contributions to improve the mechanism together. Currently, there are 3 PluggableDevices. Today, we are excited to announce the latest PluggableDevice - Intel® Extension for TensorFlow*.
 |
| Figure 1. Intel Data Center GPU Flex Series |
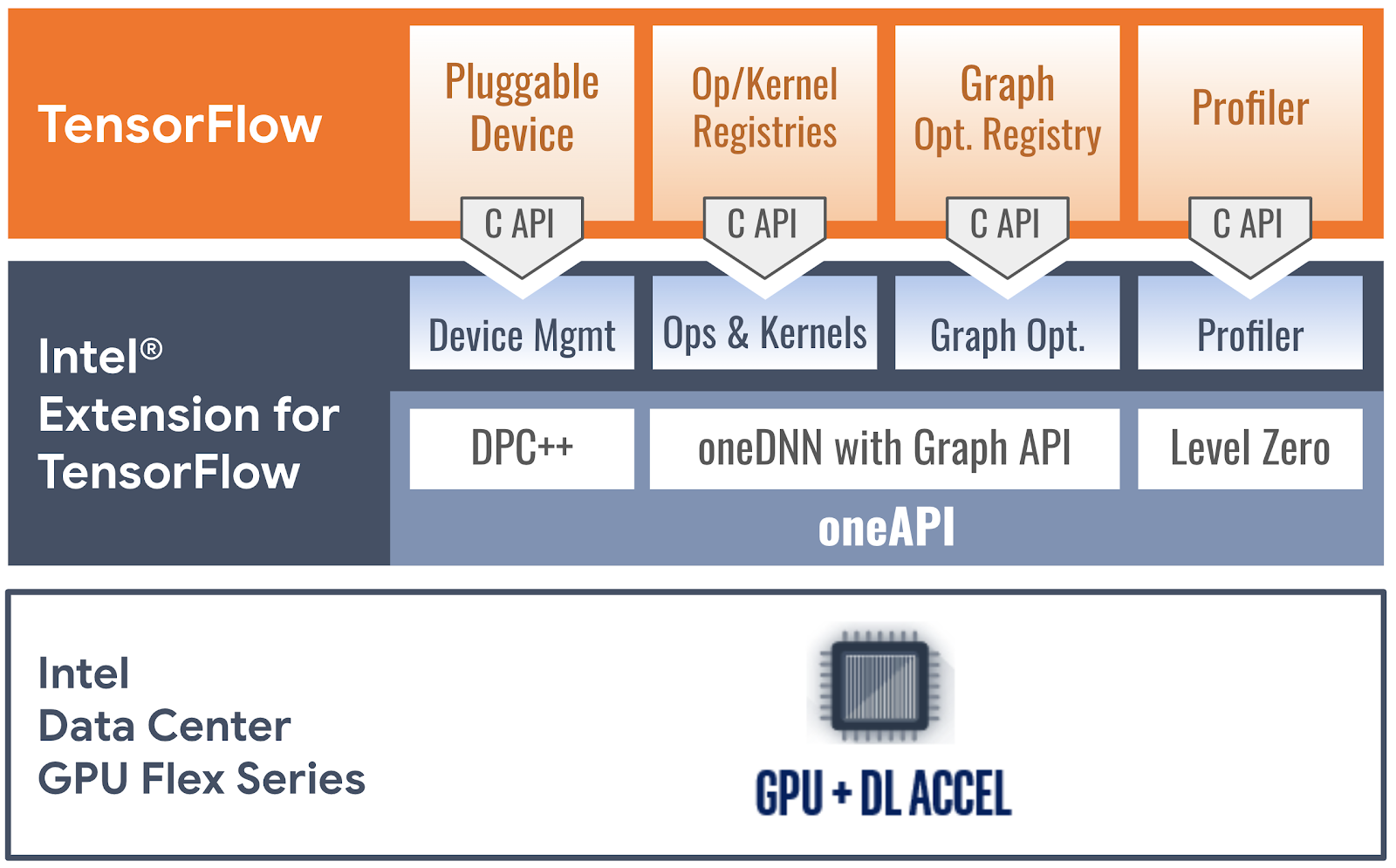
Intel® Extension for TensorFlow* accelerates TensorFlow-based applications on Intel platforms, focusing on Intel’s discrete graphics cards, including Intel® Data Center GPU Flex Series (Figure 1) and Intel® Arc™ graphics. It runs on Linux and Windows Subsystem for Linux (WSL2). Figure 2 illustrates how the plug-in implements PluggableDevice interfaces with oneAPI, an open, standard-based, unified programming model that delivers a common developer experience across accelerator architectures:
- Device management: We implemented TensorFlow’s StreamExecutor C API utilizing C++ with SYCL and some special support provided by the oneAPI SYCL runtime (DPC++ LLVM SYCL project). StreamExecutor C API defines stream, device, context, memory structure, and related functions, all of which have trivial mappings to corresponding implementations in the SYCL runtime.
- Op and kernel registration: TensorFlow’s kernel and op registration C API allows adding device-specific kernel implementations and custom operations. To ensure sufficient model coverage, we match TensorFlow native GPU device’s op coverage, implementing most performance critical ops by calling highly-optimized deep learning primitives from the oneAPI Deep Neural Network Library (oneDNN). Other ops are implemented with SYCL kernels or the Eigen math library. Our plug-in ports Eigen to C++ with SYCL so that it can generate programs to implement device ops.
- Graph optimization: The Flex Series GPU plug-in optimizes TensorFlow graphs in Grappler through Graph C API and offloads performance-critical graph partitions to the oneDNN library through oneDNN Graph API. It receives a protobuf-serialized graph from TensorFlow, deserializes the graph, identifies and replaces appropriate subgraphs with a custom op, and sends the graph back to TensorFlow. When TensorFlow executes the processed graph, the custom ops are mapped to oneDNN’s optimized implementation for their associated oneDNN Graph partitions.
- Profiler: The Profiler C API lets PluggableDevices communicate profiling data in TensorFlow’s native profiling format. The Flex Series GPU plug-in takes a serialized XSpace object from TensorFlow, fills the object with runtime data obtained through the oneAPI Level Zero low-level device interface, and returns the object back to TensorFlow. Users can display the execution profile of specific ops on The Flex Series GPU with TensorFlow’s profiling tools like TensorBoard.
|
| Figure 2. How Intel® Extension for TensorFlow* implements PluggableDevice interfaces with oneAPI software components |
To install the plug-in, run the following commands:
$ pip install tensorflow==2.10.0 $ pip install intel-extension-for-tensorflow[gpu] |
See the
Intel blog for more detailed information. For issues and feedback specific to Intel® Extension for TensorFlow, please provide feedback
here.
We are committed to continue improving PluggableDevice with the community so that device plug-ins can run TensorFlow applications as transparently as possible. Please refer to our PluggableDevice
tutorial and
sample code if you would like to integrate a new device with TensorFlow. We look forward to enabling more AI accelerators in TensorFlow through PluggableDevice.
Contributors: Anna Revinskaya (Google), Yi Situ (Google), Eric Lin (Intel), AG Ramesh (Intel), Sophie Chen (Intel), Yang Sheng (Intel), Teng Lu (Intel), Guizi Li (Intel), River Liu (Intel), Cherry Zhang (Intel), Rasmus Larsen (Google), Eugene Zhulenev (Google), Jose Baiocchi Paredes (Google), Saurabh Saxena (Google), Gunhan Gulsoy (Google), Russell Power (Google)






