Posted by Hannes Hapke and Robert Crowe
Startup companies building Machine Learning-based services and products require production-level infrastructure for training and serving their models. This can be especially challenging for small teams that are spread thin and need to innovate and grow quickly. TFX (TensorFlow Extended) provides a range of options to mitigate these challenges. In this blog post, you will learn how the San Francisco-based FinTech startup Digits has benefitted from applying TFX early, how TFX helps Digits grow, and how other startups can benefit from TFX too.
TFX is a set of libraries that streamline the development and deployment of production machine learning models, including implementing automated training pipelines. You might already be aware of major companies like Alphabet (including Google and Waze), Spotify, or Twitter successfully leveraging TFX to manage their machine learning pipelines. But TFX also has enormous benefits for medium-stage startups, like Digits.
Before we dive into how we are using TFX at Digits, let’s introduce a conceptual software design question that every startup will face: Choosing between tactical and strategic programming (introduced by John Ousterhout in “A Philosophy of Software Design”). In his analysis, Ousterhout shows that strategic programming is a much more sustainable approach for long-term success: even though it takes more time to get to an initial release, strategic programming will help make the complexity of a growing codebase more manageable.
 |
| Source: “A Philosophy of Software Design”, John Ousterhout, 2018 |
At Digits, we found that the same concept applies to machine learning. While we could train machine learning models in a minimal Jupyter notebooks-based setup, this system would become increasingly hard to manage as complexity increases. In this scenario, any initial wins of a rapidly trained machine learning model would dwindle as the company grows. Therefore, we invested heavily in our ML engineering setup from the start:
Ousterhout found that strategic programming requires more upfront time, but developers will benefit from lower system complexity. For example, we have spent roughly 2-3 months setting up all the ML tooling and workflows, and we recognize that it is a substantial investment.
While this might not be feasible for startups that are still trying to establish a product-market-fit, we believe that this ML strategy is the right path for startups with a growing customer base. Furthermore, it has been our experience that applying strategic programming to machine learning problems will add to the developers’ job satisfaction and increase retention among the data team in the long run (fewer rushed hotfixes, systematic model retraining, etc.).
Growing our business with TFX, we have identified three key benefits that have allowed us to optimize our ML model training and deployment in ways that have been crucial to our success as a startup:
At Digits, we distinguish between machine learning experiments and production machine learning. The objective of an ML experiment is to develop a proof of concept model. Our engineers are free to use any framework and tooling for ML experiments as long as our security requirements are met.
When we bring a model to production and customers rely on consistent predictions, we convert these experiments to production ML models. Every time we create a production ML model, we follow a consistent project structure and use the same steps for data and model analysis as well as feature engineering. TFX is crucial in standardizing those aspects.
Because each production model follows the same standards, we can detect potential synergies between projects early. This approach enables us to share code between projects even in the earliest development stages. Standardization has increased code reusability, and new projects have a much faster ramp-up time.
Another benefit of standardizing our workflows with TFX is that we can now apply our software engineering and DevOps principles to ML projects: Pipelines that run non-periodically can be triggered by our continuous integration system. TFX pipelines then register the newly produced model with our model registry. Based on this, the continuous integration system can also update our ML-serving endpoints and automatically deploy our ML models. This way, all changes to our ML systems are tracked in our Git repository.
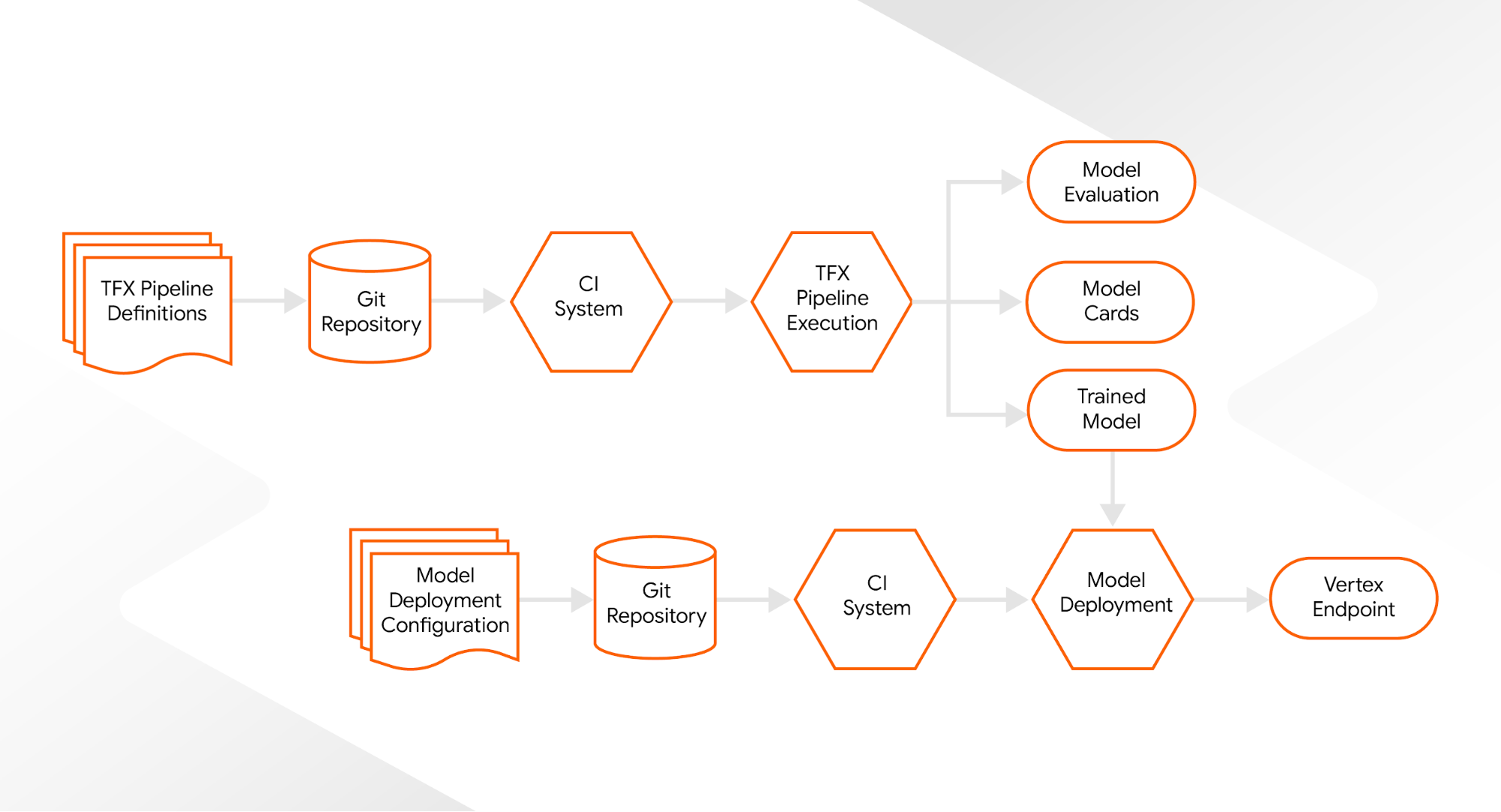 |
| System components including CI |
In contrast to Keras’ preprocessing layers, TFX supports feature engineering, model analysis, and data validation via Apache Beam tasks. This way we only need to implement the feature engineering once - with TFX, we can simply swap out the Apache Beam configuration when our datasets grow and we need more processing capabilities.
Startups can begin with the TFX default setup based on Apache Beam’s DirectRunner. The DirectRunner mode doesn’t allow any parallelized execution of pipeline tasks but is available without any setup time. As the startup grows, the engineering team can swap out the underlying Apache Beam Runner for a more performant system like Google Cloud’s Dataflow, Apache Spark, or Apache Flink, with minimal code changes - often only one line. While Dataflow is only available to Google Cloud customers, Apache Spark and Flink are open-source, and all major cloud providers offer managed services.
We successfully employed this strategy at Digits: We started out with Apache Beam’s DirectRunner for our initial pipelines, a setup that helped us understand how TFX can improve our ML workflows. As our company grew, the volume of data to process grew as well. To handle the increasing volume of data, TFX allowed us to switch to a different Beam runner without any friction. By building our pipelines in two phases, we didn’t have to implement TFX and the more performative and complex orchestration dependencies all at once, and saved our small initial team considerable strain.
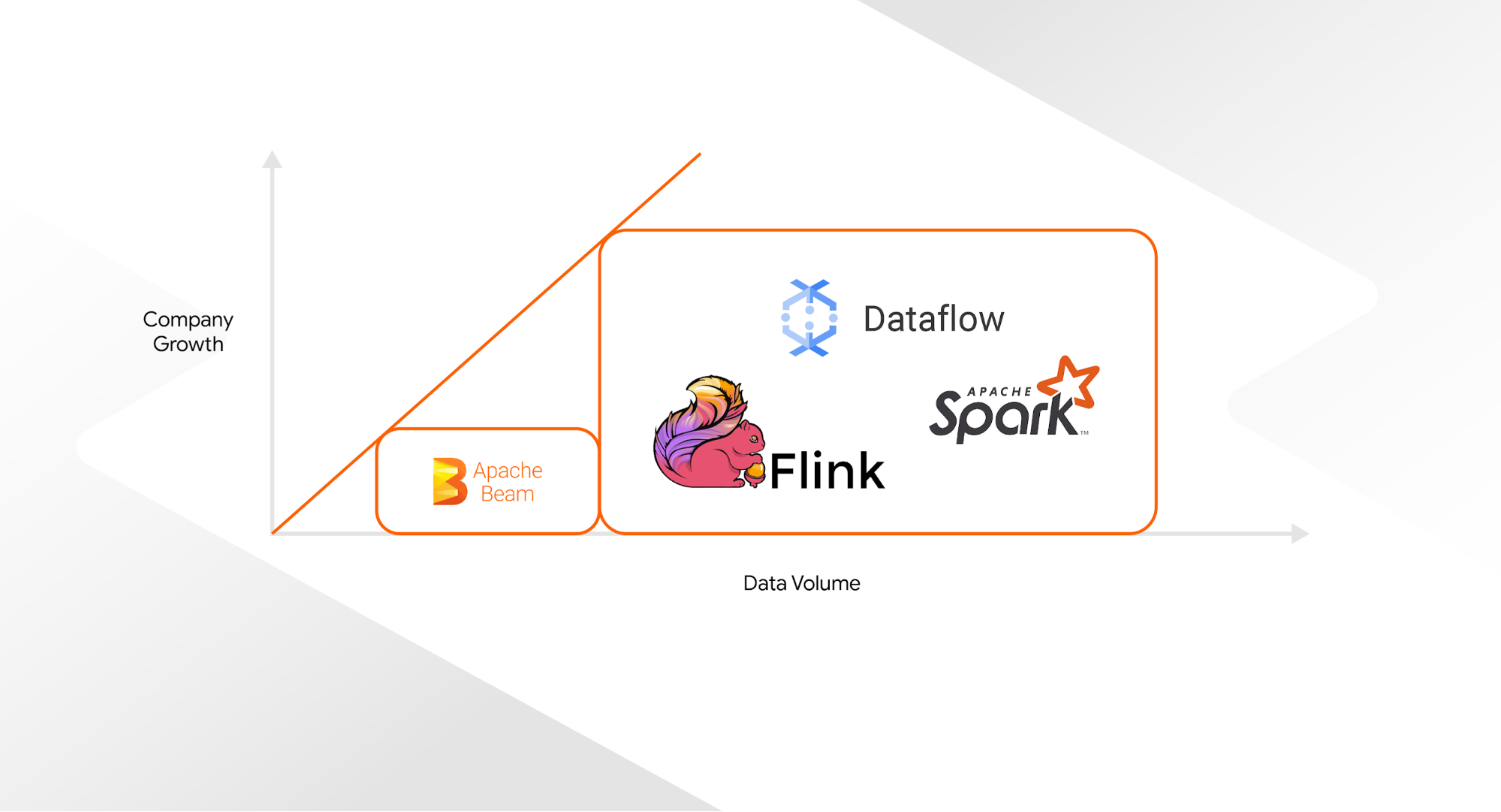 |
| Different Beam Runner options, depending on the data volume |
Another advantage that was useful to us is how easily TFX integrates with the Google Cloud ecosystem. Google Cloud’s Vertex AI Pipeline natively supports TFX and provides all necessary pipeline infrastructure as a managed service. Instead of managing our own Kubernetes clusters, we can easily switch back and forth between pipeline runs in different Google Cloud projects. We are also not limited by cluster compute and memory limitations since we can access both GPUs and TPUs with Vertex Pipelines.
Keeping track of all ML artifacts is key for the sustainable management of production ML models. Our goal was to track all relevant data points for all our production models. We needed to store artifacts like datasets, data splits, data validation results, feature transformations, trained models, and model analysis results. But we also didn’t want to slow down the ML team with extensive record keeping.
TFX is tightly integrated with the ML Metadata Store (MLMD) which helps us to keep track of all model details in one place. Under the hood, each TFX component in our ML pipelines records all intermediate pipeline results and metadata. We can generate model lineages for each model produced by our ML pipelines without any additional overhead. This has proven to be an indispensable tool when things move fast.
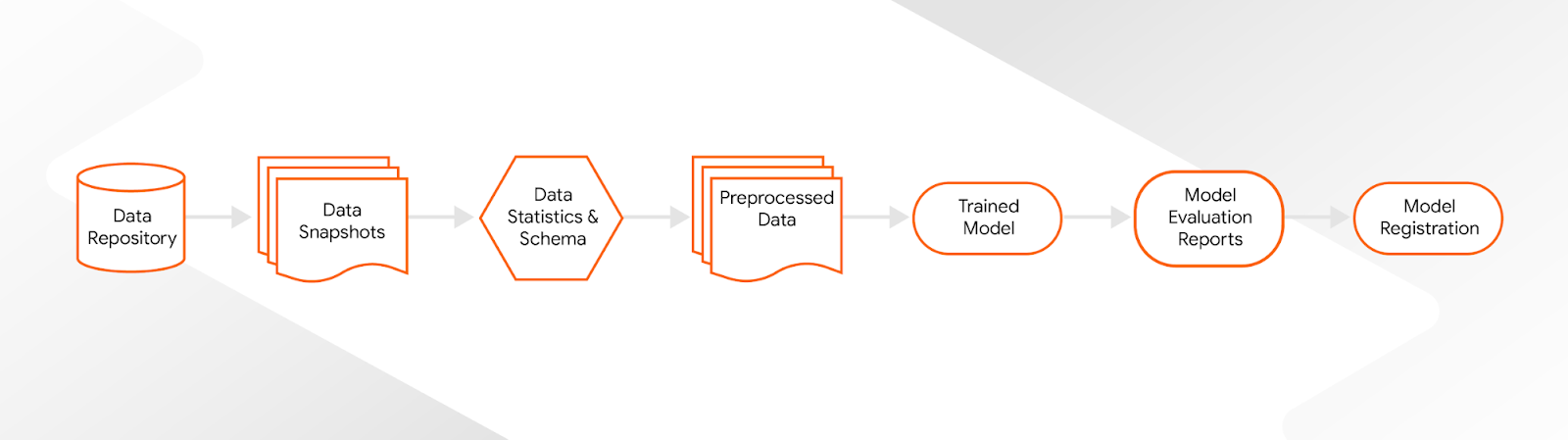 |
| Model lineage |
While adapting TFX to our needs did take some time, we have seen this initial investment pay off over time. We are now able to convert machine learning experiments within minutes into production pipelines and continuously produce and deploy new versions of our models.
- TFX helps us to make our ML codebase more modular. We have developed several custom TFX components (e.g. for model deployments, model annotations, or model tracking). Due to the modularity of the TFX components, all projects can benefit from enhancements made in a single project.
- At the same time, we benefited from standardizing our production ML codebase with TFX. As a growing startup company, we found this standardization especially useful as it helped us stay on track as complexity increased. New projects now follow a highly optimized cookie-cutter approach, which has resulted in major time and labor savings. Those standardizations also allowed us to automate large parts of the model deployment processes, which in turn helped free up engineering capacities. We have found that these savings are vital for the small, flexible ML teams which are common in startups.
- Using TFX also has allowed us to future-proof our MLOps tooling. The fact that TFX uses Apache Beam under the hood gave us confidence that we don’t need to reengineer our MLOps setup as the company grows.
- TFX, its metadata store, and its Google Cloud integrations have helped us reproduce models from given artifacts and made it much easier to accurately recreate any previous ML models whenever needed.
The experience of growing Digits with TFX has convinced us that any company that is serious about machine learning can benefit from TFX - at every step along the way, from small startups to large corporations.
To learn more about TFX, check out the TFX website, join the TFX discussion group, dive into other posts in the TFX blog, watch our TFX playlist on YouTube, or subscribe to the TensorFlow channel.

أكتوبر 14, 2022
—
Posted by Hannes Hapke and Robert Crowe
Startup companies building Machine Learning-based services and products require production-level infrastructure for training and serving their models. This can be especially challenging for small teams that are spread thin and need to innovate and grow quickly. TFX (TensorFlow Extended) provides a range of options to mitigate these challenges. In this blog p…





