Posted by The Hugging Face Team 🤗
Language models have bloomed in the past few years thanks to the advent of the Transformer architecture. Although Transformers can be used in many NLP applications, one is particularly alluring: text generation. It caters to the practical goals of automating verbal tasks and to our dreams of future interactions with chatbots.
Text generation can significantly impact user experiences. So, optimizing the generation process for throughput and latency is crucial. On that end, XLA is a great choice for accelerating TensorFlow models. The caveat is that some tasks, like text generation, are not natively XLA-friendly.
The Hugging Face team recently added support for XLA-powered text generation in 🤗 transformers for the TensorFlow models. This post dives deeper into the design choices that had to be made in order to make the text generation models TensorFlow XLA-compatible. Through these changes to incorporate XLA compatibility, we were able to significantly improve the speed of the text generation models ~ 100x faster than before.
To understand why XLA is non-trivial to implement for text generation, we need to understand text generation in more detail and identify the areas that would benefit the most from XLA.
Popular models based on the Transformer architecture (such as GPT2) rely on autoregressive text generation to produce their outputs. Autoregressive text generation (also known as language modeling) is when a model is iteratively called to predict the next token, given the tokens generated so far, until some stopping criterion is reached. Below is a schematic of a typical text generation loop:
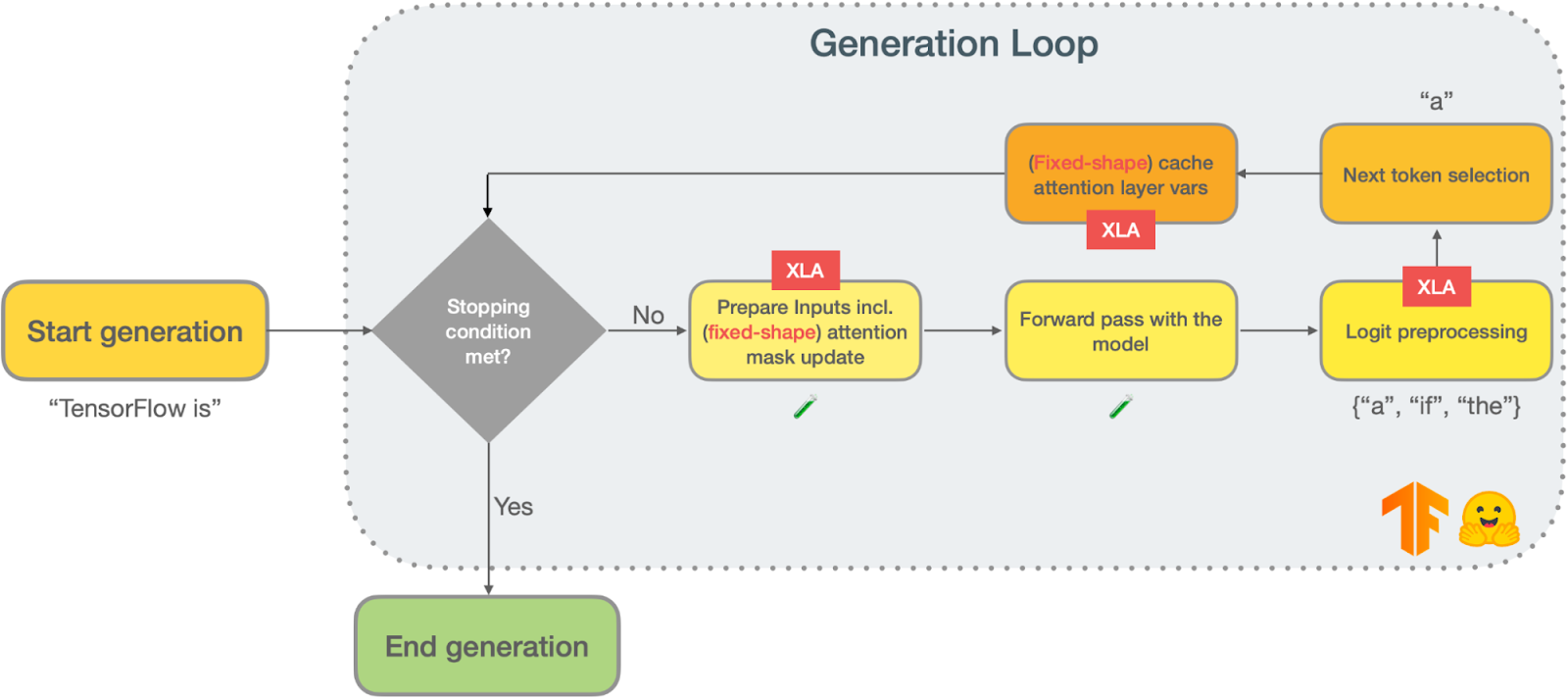 |
Any autoregressive text generation pipeline usually contains two main stages in addition to the model forward pass: logits processing and next token selection.
Next token selection
Next token selection is, as the name suggests, the process of selecting the token for the current iteration of text generation. There are a couple of strategies to perform next token selection:
You can read more about these strategies in this blog post.
Logit preprocessing
Perhaps the least discussed step of text generation is what happens between the model forward pass and the next token selection. When performing a forward pass with a text generation model, you will obtain the unnormalized log probabilities for each token (also known as logits). At this stage, you can freely manipulate the logits to impart the desired behavior to text generation. Here are some examples:
Before you move on to the XLA section of this blog post, there is one more technical aspect of autoregressive text generation that you should know about. The input to a language model is the sequence of tokens generated so far. So, if the input has N tokens, the current forward pass will repeat some attention-related computations from the previous N-1 tokens. The actual details behind these repeated computations deserve (and have) a blog post of their own, the illustrated GPT-2. In summary, you can (and should) cache the keys and the values from the masked self-attention layers where the size of the cache equals the number of input tokens obtained in the previous generation iteration.
Here we identified three keys areas that could benefit from XLA:
As a TensorFlow user, the first thing you must do if you want to compile your function with XLA is to ensure that it can be wrapped with a tf.function and handled with AutoGraph. There are many different paths you can follow to get it done for autoregressive text generation – this section will cover the design decisions made at Hugging Face 🤗, and is by no means prescriptive.
Switching between eager execution and XLA-enabled graph mode should come with as few surprises as possible. This design decision is paramount to the transformers library team. Eager execution provides an easy interface to the TensorFlow users for better interaction, greatly improving the user experience. To maintain a similar level of user experience, it is important for us to reduce the friction of XLA conversion.
Control flow
As mentioned earlier, text generation is an iterative process. You condition the inputs based on what has been generated, where the first generation is usually “seeded” with a start token. But, this continuity is not infinite – the generation process terminates with a stopping criterion.
For dealing with such a continuous process, we resort to while statements. AutoGraph can automatically handle most while statements with no changes, but if the while condition is a tensor, then it will be converted to a tf.while_loop in the function created by tf.function. With tf.while_loop, you can specify which variables will be used across iterations and if they are shape-invariant or not (which you can’t do with regular Python while statements, more on this later).
An advantage of using tf.while_loop for the text generation autoregressive loop is that the stopping conditions become clearly identifiable – they are the termination condition of the loop, corresponding to its cond argument. Here are two examples we resorted to tf.while_loop with explicit conditioning:
Sometimes a for loop repeats the same operation for an array of inputs, such as in the processing of candidates for beam search. AutoGraph’s strategy will greatly depend on the type of the condition variable, but there are further alternatives that do not rely on AutoGraph. For instance, vectorization can be a powerful strategy – instead of applying a set of operations for each data point/slice, you apply the same operations across a dimension of your data. However, it has some drawbacks. Skipping operations is not desirable with vectorized operations, so it is a trade-off you should consider.
In the beam search candidate loop, some of the iterations can be skipped because you can tell in advance that the result will not be used. The ratio of skipped iterations was low and the readability benefits of vectorization were considerable, so we adopted a vectorization strategy to execute the candidate processing in beam search. Here is one example of logit processing, benefitting from this type of vectorization.
if/else branches. Similarly to while statements, AutoGraph will convert if statements into tf.cond if the condition is a tensor.if statement must now be converted to function calls, and both branches must return the same number and type of outputs. This change impacts complex logit processors, such as the one that prevents specific tokens from being generated. Here is one example that shows our XLA port to filter undesirable tokens as a part of logit processing.Data structures
In text generation, many data structures don’t have a static dimension that depends on how many tokens were generated up to that point. This includes:
among others. Although tf.while_loop allows you to use variables with varying shapes across iterations, this process will trigger re-tracing, which should be avoided whenever possible since it’s computationally expensive. You can refer to the official commentary on tracing in case you want to delve deeper.
The summary here is that if you constantly call your tf.function wrapped function with the same input tensor shape and type (even if they have different data), and do not use new non-tensor inputs, you will not incur tracing-related penalties.
At this point, you might have anticipated why loops with dynamic shapes are not desirable for text generation. In particular, the model forward pass would have to be retraced as more and more generated tokens are used as part of its input, which would be undesirable. As an alternative, our implementation of autoregressive text generation uses static shapes obtained from the maximum possible generation length. Those structures can be padded and easily ignored thanks to the attention masking mechanisms in the Transformer architecture. Similarly, tracing is also a problem when your function itself has different possible input shapes. For text generation, this problem is handled the same way: you can (and should) pad your input prompt to reduce the possible input lengths.
Transformer-based language models rely on positional embeddings for the input tokens since the Transformer architecture is permutation invariant. These positional embeddings are often derived from the size of the structures. With padded structures, that is no longer possible, as the length of the input sequences no longer matches the number of generated tokens. In fact, because different models have different ways of retrieving these positional embeddings given the position index, the most straightforward solution was to use explicit positional indexes for the tokens while generating and to perform some ad-hoc model surgery to handle them.
Here are a couple of example model surgeries that we made to make the underlying models XLA-compatible:
Finally, to make our users aware of the potential failure cases and limitations of XLA, we ensured adding informative in-code exceptions (an example).
To summarize, our journey from a naive TensorFlow text generation implementation to an XLA-powered one consisted of:
tf.while_loop or vectorization;
tf.cond;
The journey to XLA-accelerated TensorFlow text generation by Hugging Face 🤗 was full of learning opportunities. But more importantly, the results speak for themselves: with these changes, TensorFlow text generation can execute 100x faster than before! You can try it yourself in this Colab and can check out some benchmarks here.
Bringing XLA into your mission-critical application can greatly impact driving down costs and latency. The key to accessing these benefits lies in understanding how AutoGraph and tracing work to bring the most out of them. Have a look at the resources shared in this blog post and give it a go!
Acknowledgements
Thanks to the TensorFlow team for bringing support for XLA. Thanks to Joao Gante (Hugging Face) for spearheading the development of XLA-enabled text generation models for TensorFlow in 🤗 Transformers.

November 28, 2022 — Posted by The Hugging Face Team 🤗 Language models have bloomed in the past few years thanks to the advent of the Transformer architecture. Although Transformers can be used in many NLP applications, one is particularly alluring: text generation. It caters to the practical goals of automating verbal tasks and to our dreams of future interactions with chatbots. Text generation can significantly …





