Posted by Jaehong Kim, Fan Yang, Shixin Luo, and Jiyang Kang

The TensorFlow Model Garden provides implementations of many state-of-the-art machine learning models for vision and natural language processing, and workflow tools to let you quickly configure and run those models on standard datasets. These models are implemented using modern best practices.
Previously, we have announced the quantization aware training (QAT) support for various on-device vision models using TensorFlow Model Optimization Toolkit (TFMOT). In this post, we introduce new SOTA models optimized using QAT in object detection, semantic segmentation, and natural language processing.
A new QAT supported object detection model has been added to the Model Garden. Specifically, we use a MobileNetV2 with 1x depth multiplier as the backbone and a lightweight RetinaNet as the decoder. MobileNetV2 is a widely used mobile model backbone and we have provided QAT support since our last release. RetinaNet is the SOTA one-stage detection framework used for detection tasks and we make it more efficient on mobile devices by using separable convolution and reducing the number of filters. We train the model from scratch without any pre-trained checkpoints.
Results show that with QAT, we can successfully preserve the model quality while reducing the latency significantly. In comparison, post-training quantization (PTQ) does not work out-of-the-box smoothly due to the complexity of the RetinaNet decoder, thus leading to low box average precision (AP).
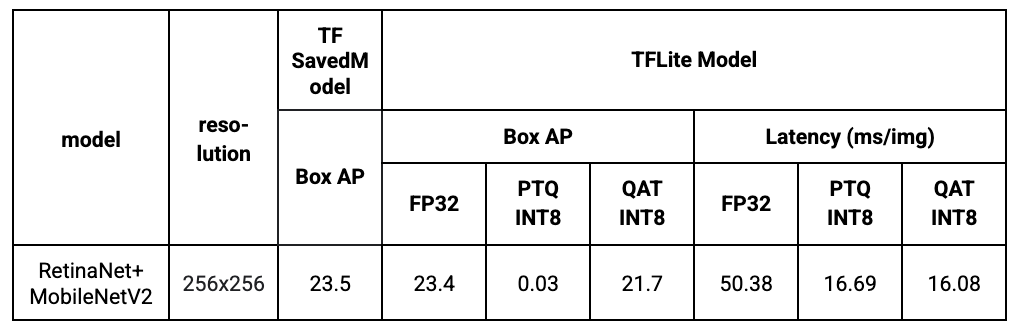 |
MOSAIC is a neural network architecture for efficient and accurate semantic image segmentation on mobile devices. With a simple asymmetric encoder-decoder structure which consists of an efficient multi-scale context encoder and a light-weight hybrid decoder to recover spatial details from aggregated information, MOSAIC achieves better balanced performance while considering accuracy and computational cost. MLCommons MLPerf adopted MOSAIC as the new industry standard model for mobile image segmentation benchmark.
We have added QAT support for MOSAIC as part of the open source release. In Table 2, we provide the benchmark comparison between DeepLabv3+ and MOSAIC. We can clearly observe that MOSAIC achieves better performance (mIoU: mean intersection-over-union) with significantly lower latency. The negligible gap between QAT INT8 and FP32 also demonstrates the effectiveness of QAT. Please refer to the paper for more benchmark results.
 |
MobileBERT is a thin version of BERT_LARGE, while equipped with bottleneck structures and a carefully designed balance between self-attentions and feed-forward networks. (code)
We applied QAT to the MobileBERT model to show our QAT toolkit can apply to the Transformer based mode, which has become very popular these days.
In this post, we expanded the coverage of QAT support and introduced new state-of-the-art quantized models in Model Garden for object detection, semantic segmentation, and natural language processing. TensorFlow practitioners can easily utilize these SOTA quantized models for their problems achieving lower latency or smaller model size with minimal accuracy loss.
To learn more about the Model Garden and its Model Optimization Toolkit support, check out the following blog posts:
Model Garden provides implementation of various vision and language models, and the pipeline to train models from scratch or from checkpoints. To get started with Model Garden, you can check out the examples in the Model Garden Official repository. Model libraries in this repository are optimized for fast performance and actively maintained by Google engineers. Simple colab examples for training and inference using these models are also provided.
We would like to thank everyone who contributed to this work including the Model Garden team, Model Optimization team and Google Research team. Special thanks to Abdullah Rashwan, Yeqing Li, Hongkun Yu from the Model Garden team; Jaesung Chung from the Model Optimization team, Weijun Wang from the Google Research team.


Δεκεμβρίου 22, 2022 — Posted by Jaehong Kim, Fan Yang, Shixin Luo, and Jiyang Kang The TensorFlow Model Garden provides implementations of many state-of-the-art machine learning models for vision and natural language processing, and workflow tools to let you quickly configure and run those models on standard datasets. These models are implemented using modern best practices. Previously, we have announced the quantiz…






