Posted by Chansung Park, Sayak Paul (ML and Cloud GDEs)
TensorFlow Extended (TFX) is a flexible framework allowing Machine Learning (ML) practitioners to iterate on production-grade ML workflows faster with reliability and resiliency. TFX’s power lies in its flexibility to run ML pipelines across different compatible orchestrators such as Kubeflow, Apache Airflow, Vertex AI Pipelines, etc., both locally and on the cloud.
In this blog post, we discuss the crucial details of building an end-to-end ML pipeline for Semantic Segmentation tasks with TFX and various Google Cloud services such as Dataflow, Vertex Pipelines, Vertex Training, and Vertex Endpoint. The pipeline also uses a custom TFX component that is integrated with Hugging Face 🤗 Hub - HFPusher. Finally, you will see how we implemented CI/CD into the mix by leveraging GitHub Actions.
Although we won’t go over all the bits of the pipeline, you can still find the code of the underlying project in this GitHub repository.
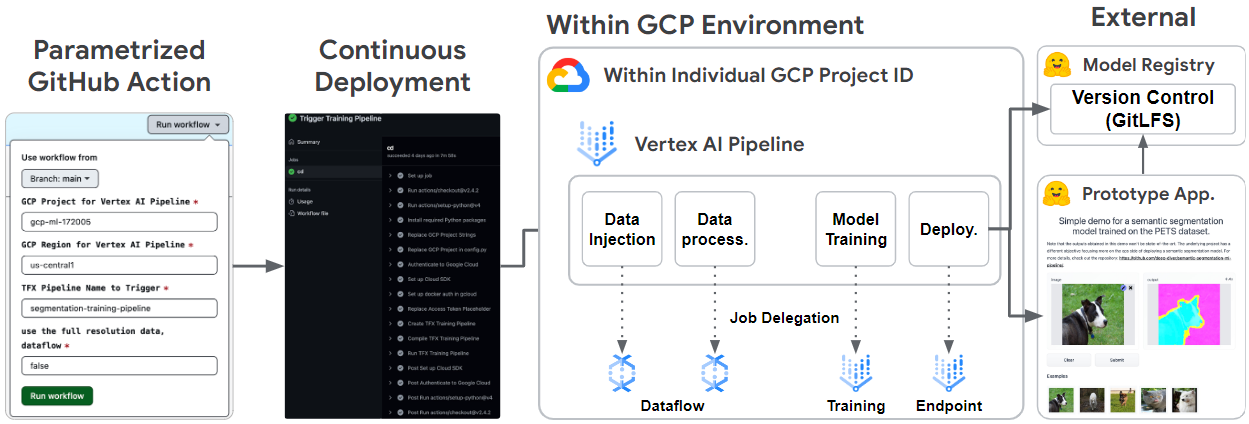
The system architecture of the project is divided into three main parts. The first part is all about the core TFX pipeline handling all the steps from data ingestion to model deployment. The second part concerns the integration between the pipeline and the external Hugging Face 🤗 Hub service. The last one is about automation and implementing CI/CD using GitHub Actions.
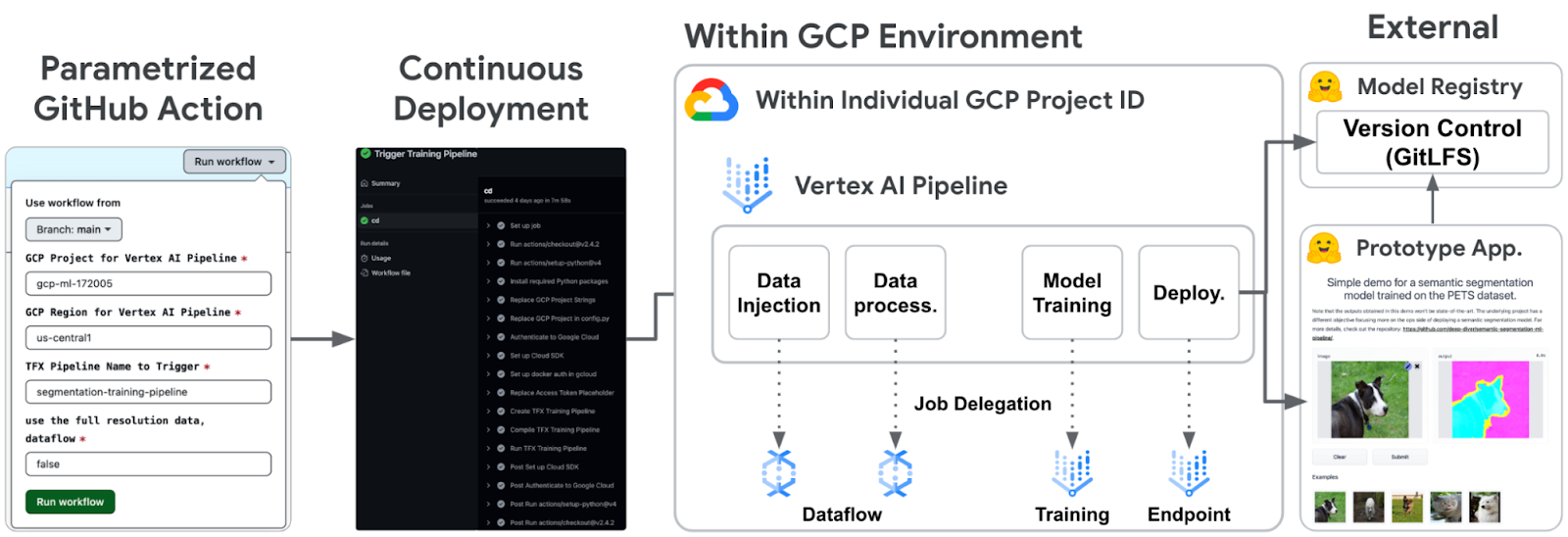 |
Figure 1. Overall system architecture (original) |
It is common to open Pull Requests when proposing new features or code refactorings in separate branches. When it comes to ML projects, these changes usually affect the model and/or data. Besides running basic validation on the proposed changes (code quality, tests, etc.), we should also ensure that the changes produce a model that is better enough to replace the currently deployed model before merging (if the changes pertain to modeling). In this project, we developed a GitHub Action that is manually triggered on the merging branch with configurable parameters. This way, project stakeholders can validate performance-related changes and reliably ship the changes to production. In reality, there might be more critical measurements here, but we hope this GitHub Action proves to be a good starting point.
At the heart of any MLOps project, there is an ML pipeline. We built a simple yet complete ML pipeline with support for automatic data ingestion, data preprocessing, model training, model evaluation, and model deployment in TFX. The TFX pipeline could be run on a local environment, but we also ran it on the Vertex AI platform to replicate real-world production-grade environments.
Finally, the trained and qualified model from the ML pipeline is deployed to the Vertex AI Endpoint. The “blessed” model is also pushed to the Hugging Face Hub alongside an interactive demo via a custom HFPusher TFX component. Hugging Face Hub is a very popular place to store models and publish a fully working ML-powered interactive application for free. It is useful to showcase an application with the latest model to audit if it works as expected before going on a full production deployment.
Below, we discuss each of these components in a little more detail, discussing our design considerations and non-trivial technical aspects.
The ML pipeline is written entirely in TFX, from data ingestion to model deployment. Specifically, we used standard TFX components such as ExampleGen, ImportSchemaGen, Transform, Trainer, Evaluator, and Pusher, along with the custom HFPusher component. Let’s briefly look at the roles of each component in the context of our project.
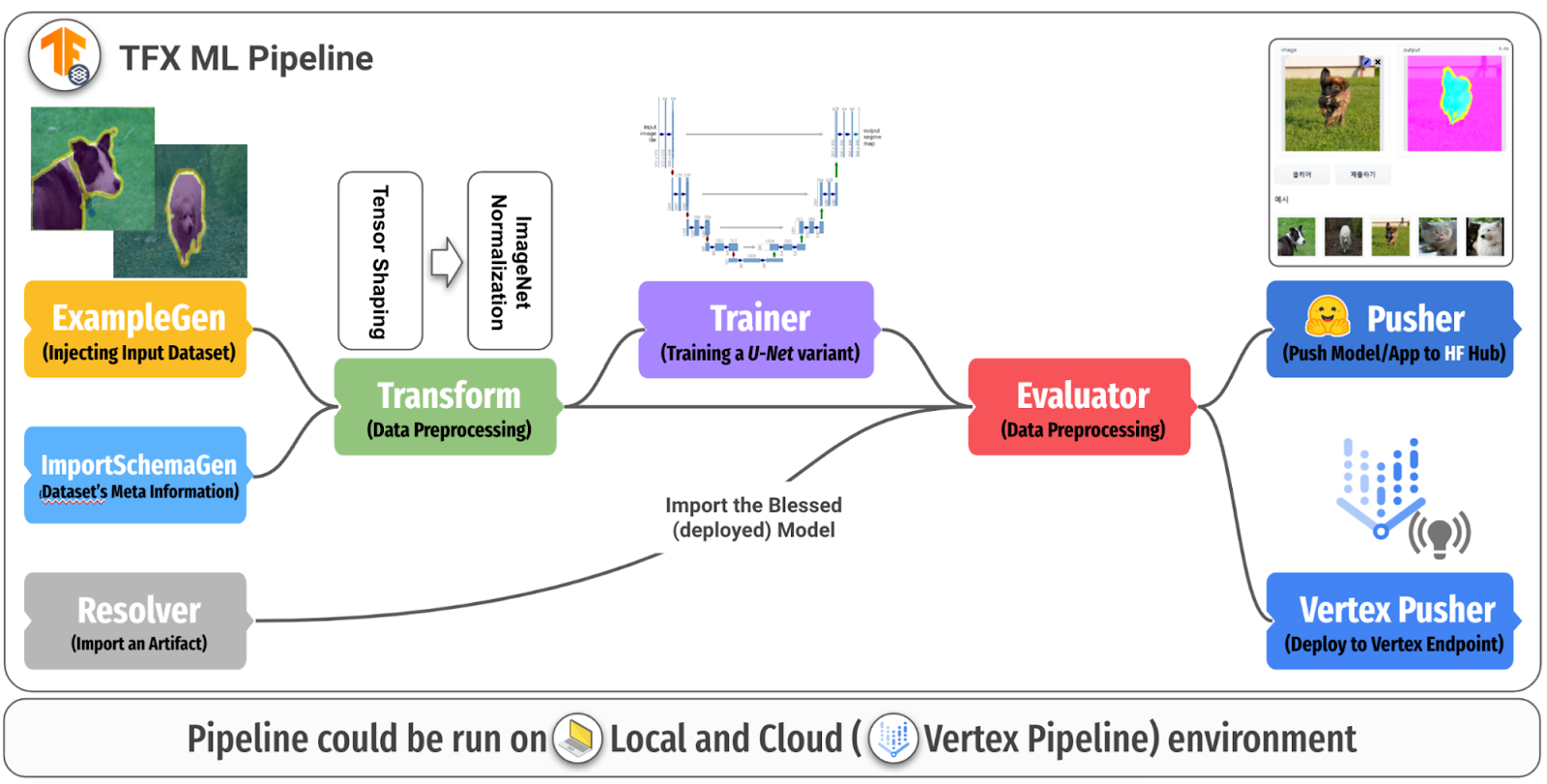 |
Figure 2. Overview of the ML pipeline (original) |
In this project, we have prepared Pets dataset in TFRecord format with these scripts and stored them in Google Cloud Storage(GCS). ExampleGen brings the data files from GCS, splits them into training and evaluation datasets according to glob patterns, and stores them as TFRecords in GCS. Note that ExampleGen could take different data types such as CSV, TFRecord, or Parquet, then it generates datasets in a uniform format in TFRecord. It lets us handle the data uniformly inside the entire TFX pipeline. Note that since the Pets dataset is available from TF Datasets, you could also use a custom TFDS ExampleGen for this task.
ExampleGen can be integrated with Dataflow out of the box. All you need to do to benefit from Dataflow is to call with_beam_pipeline_args method with appropriate parameters such as machine type, disk size, the number of workers, and so on. For context, Dataflow is a managed service provided by Google Cloud that allows us to run Apache Beam pipelines efficiently in a fully distributed manner.
ImportSchemaGen imports a Protocol Buffer Text Format file that was previously automatically inferred by SchemaGen. It can also be hand-tuned to define the structure of the output data from ExampleGen.
In our case, the prepared Pets dataset has two features - image and segmentation map (label), and the size of each feature is 128x128. Therefore, we could define a schema like the one below.
Also note that in the float_domain section, we can set the value restrictions. In this project, the input data is standard RGB images, so each pixel value should be between 0 and 255. On the other hand, the pixel value of the label should be 0, 1, or 2, meaning outer, inner, and border of an object in an image, respectively.
With the help of ImportSchemaGen, the data is already shaped correctly in Transform and validated. Without ImportSchemaGen, we would have to write code to parse TFRecords and shape each feature manually inside Transform. Therefore, one line of code below is sufficient for the data preprocessing since the model in this project is built on top of MobileNetV2.
Since data preprocessing is a CPU and memory-intensive job, Transform also can be integrated with Dataflow. Just like in ExampleGen, the job could be seamlessly delegated to Dataflow by calling the with_beam_pipeline_args method.
(Vertex) Trainer simply trains a model. We used a UNet architecture built on top of MobileNetV2 from the TensorFlow official tutorial. Since the model architecture is nothing new, let’s take a look at how it is modularized and some of the key pieces of code.
You place your modeling code in a separate file, which is supplied as a parameter to the Trainer. In this case, that file is named train.py. When the Trainer component is run, it looks for a starting point function with the name run_fn which is defined in train.py. The run_fn() function basically pulls in the training and evaluation datasets from the output of Transform, trains the UNet model ( defined in unet.py), then saves the trained model with appropriate signatures. The training process simply follows the standard Keras way – model.compile(), model.fit().
The Trainer component can be integrated with Vertex AI Training out of the box, which is a managed service to train models in a distributed system. By specifying how you would want to configure the training server clusters in the custom_config parameter of the Trainer, the training job is handled by Vertex AI Training automatically.
It is also important to notice which signatures the model exports in TensorFlow. Consider the following code snippet that saves a trained model (of the tf.keras.Model instance) into a SavedModel resource.
The signatures are functions that define how to handle given input data. For example, we have defined three different signatures. While serving_default is used during serving time, the other two are used during the model evaluation time.
Note that the transform_features and from_examples signatures are used internally in the Evaluator component. In the next section, we explain their connections.
The performance of the trained model should be evaluated by certain criteria or metrics. Evaluator lets us define such metrics that not only evaluates the trained model itself but also compares the trained model to the last best model retrieved by Resolver. In other words, the trained model will be deployed only if it achieves performance above the baseline threshold and it is better than the previously deployed model. The full configurations for this project can be found here.
The reason that we had transform_features and from_examples signatures that are doing the same data preprocessing is that they are used in different situations. Evaluator runs the evaluate() method on an existing model while it runs a function (signature) specified in the signature_name on the currently trained model. Therefore, we not only need a function that transforms a given sample but also runs the evaluate() method at the same time.
When the trained model is evaluated to be deployed, (Vertex) Pusher pushes the model to the Model Registry in Vertex AI. It also optionally creates an Endpoint and deploys the model to the endpoint out of the box. You can specify a number of different deployment-specific configurations to Pusher: machine type, GPU type, the number of GPUs, traffic splits etc.
Hugging Face Hub offers ML practitioners a powerful way to store and share models, datasets, and ML applications. Since it supports seamless support for storing model artifacts with automatic version control, we developed a custom TFX component named HFPusher that:
You can use this component anywhere after the Trainer component, but it’s recommended to use it at the end of a TFX pipeline. The HFPusher component only requires a handful of arguments consisting of two TFX artifacts and four Hugging Face specific configurations:
The Hugging Face Hub is primarily based on Git and Git-LFS. The Hugging Face team provides an easy-to-use huggingface_hub API toolkit to interact with it. That is how it provides seamless support for version control, large file storage, and interaction.
In Figures 3 and 4, we show how the model repository and the application repository (which were automatically created from a TFX pipeline) look like on the Hugging Face Hub.
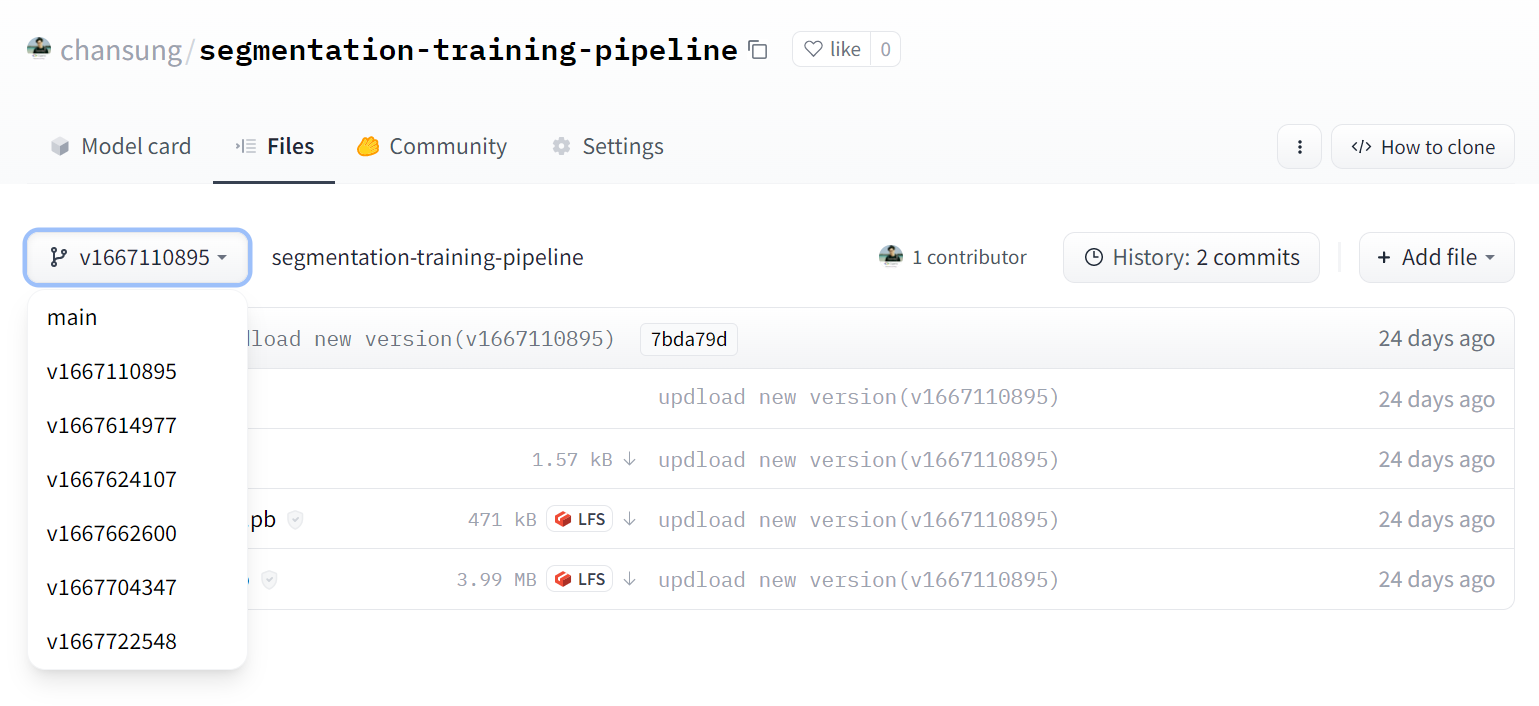 |
| Figure 3. Model versioning in Hugging Face Model Hub (original) |
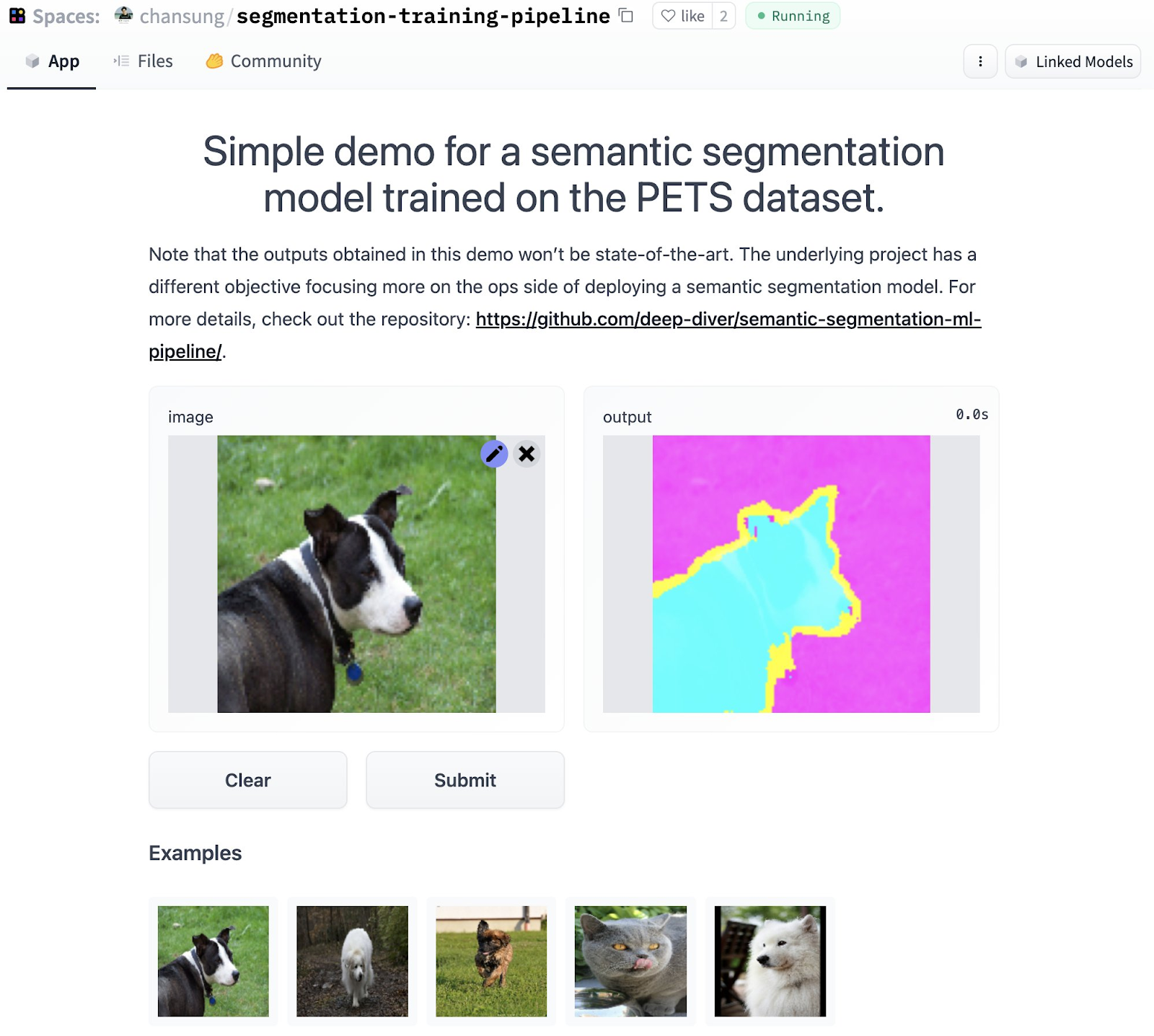 |
| Figure 4. Automatically published application in Hugging Face Space Hub (original) |
HFPusher has been contributed to the official TFX-Addons tfx-addons package. HFPusher will be available in version 0.4.0 and later in the tfx-addons package.
In the DevOps world, we usually run a number of tests on the changes introduced to ensure they’re valid enough to hit production. If the tests pass, the changes are merged and a new deployment is shipped automatically.
For an ML codebase, the changes are usually either related to data or model on a broad level. Validating these changes is quite application dependent but there could still be common grounds:
We focused on the first point in this project. We designed a GitHub Action workflow that can:
1. Google Cloud authentication and setup is done with google-github-actions/auth and google-github-actions/setup-gcloud GitHub Actions when a credential (JSON) is provided. In order to use appropriate credentials to the specified Google Cloud project ID, the workflow seeks for the credentials from GitHub Action Secret. Each credential is mapped to the name which is identical to the Google Cloud project ID.
2. Some of the sensitive information is replaced with envsubst command. In this project, it is required to provide a Hugging Face 🤗access token to the HFPusher component to create and update any repositories in Hugging Face 🤗 Hub. The access token is stored in GitHub Action Secret.
3. An environment variable enable_dataflow is set to "true" or "false" based on the specified parameter. By looking up the environment variable, the TFX pipeline conditionally defines dedicated parameters for Dataflow and passes them to ExampleGen and Transform components via with_beam_pipeline_args method.
4. The last part of the workflow compiles and runs the TFX pipeline on Vertex AI with the TFX CLIs as below. The tfx pipeline create CLI creates the pipeline and registers it to the local system. Furthermore, it is capable of building and pushing a Docker Image to Google Container Registry(GCR) based on a custom Dockerfile in the pipeline. Then tfx run create CLI runs the pipeline on Vertex AI with the specified Google Cloud Project ID and region.
In this case, we need to verify each PR if the suggested modification works well at the build and run times. Also, sometimes each collaborator wants to run the ML pipeline with their own Google Cloud account. Furthermore, it is better if we could conditionally delegate some heavy jobs in the ML pipeline to more dedicated Google Cloud services.
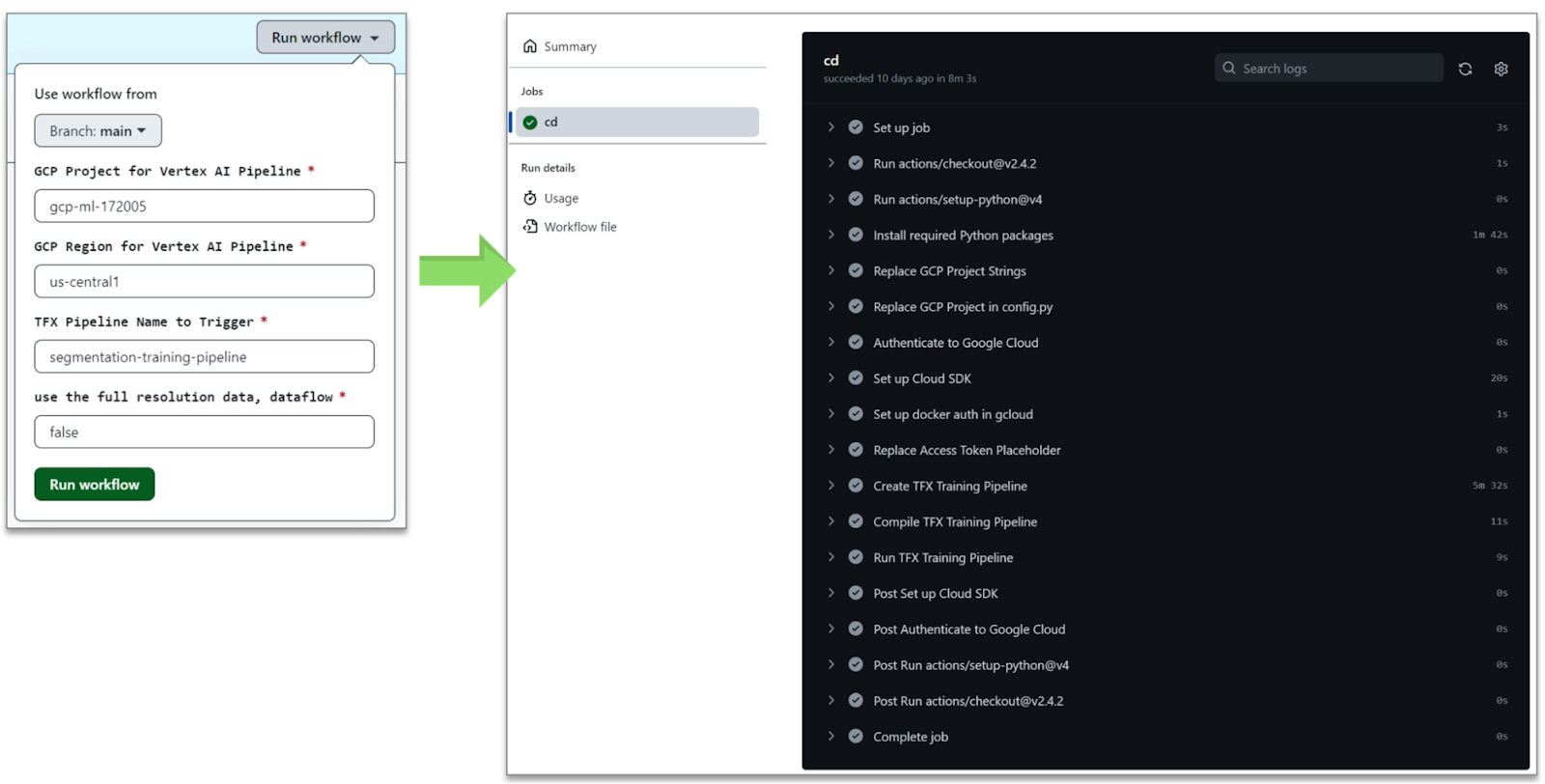 |
| Figure 5. GitHub Action for CI/CD of ML pipeline (original) |
As you may notice from Figure 5, the GitHub Action runs a workflow based on five different parameters - branch, Google Cloud project ID, cloud region, the name of TFX pipeline, and enabling the Dataflow integration.
In this post, we discussed how to build an end-to-end ML pipeline for semantic segmentation tasks. We leveraged TensorFlow, TFX, and Google Cloud services such as Dataflow and Vertex AI, GitHub Actions, and Hugging Face 🤗 Hub to develop a production-grade ML pipeline with external services along with semi-automatic CI/CD pipelines. We hope that you found this setup useful and reliable and that you will use this in your own ML pipeline projects.
As a future work, we will demonstrate a common MLOps scenario by extending this project. First, we’ll add more complexities to the data to simulate model performance degradation. Second, we’ll evaluate the currently deployed model to see if the model performance degradation actually happened. Last, we’ll verify the model performance is recovered after replacing the current model architecture with better ones such as DeepLabV3+ or SegFormer.
We are grateful to the ML Developer Programs team that provided Google Cloud credits to support our experiments. We thank Robert Crowe for providing us with helpful feedback and guidance. We also thank Merve Noyan who worked on integrating the model card utilities into the HFPusher component.

जनवरी 18, 2023 — Posted by Chansung Park, Sayak Paul (ML and Cloud GDEs) TensorFlow Extended (TFX) is a flexible framework allowing Machine Learning (ML) practitioners to iterate on production-grade ML workflows faster with reliability and resiliency. TFX’s power lies in its flexibility to run ML pipelines across different compatible orchestrators such as Kubeflow, Apache Airflow, Vertex AI Pipelines, etc., both …






{kind=link}