Posted by Sarina Sit, AMD
AMD launched the 4th Generation of AMD EPYC™ processors in November of 2022. 4th Gen AMD EPYC processors include numerous hardware improvements over the prior generation, such as AVX-512 and VNNI instruction set extensions, that are well-suited for improving inference performance. However, hardware is only one piece of the puzzle; software is a crucial component for effectively taking advantage of the underlying hardware.
We are happy to announce the new availability of the TensorFlow-ZenDNN plug-in for TensorFlow v2.12 and above, which represents the ongoing and focused effort by AMD to improve the accessibility of ZenDNN optimizations for the community via framework upstreaming. This plug-in enables neural network inferencing on AMD EPYC CPUs with the AMD ZenDNN library.
ZenDNN, which is available open-source from GitHub, is a low-level AMD deep neural network library that includes basic neural network building blocks optimized for AMD EPYC CPUs. ZenDNN is purpose-built to help deep learning application and framework developers improve inference performance on AMD EPYC CPUs across an array of workloads, including computer vision, natural language processing, and recommender systems.
We have integrated ZenDNN into high-level AI frameworks for ease of use. Our prototype integration with TensorFlow, called TF-ZenDNN, is done by forking the TensorFlow repository at a specific version and directly modifying TensorFlow code. TF-ZenDNN is available as a binary package for direct integration from AMD's ZenDNN developer resources page (diagram 1 below), with installation instructions available in our TensorFlow + ZenDNN User Guide.
 |
| Diagram 1. The ZenDNN v4.0 binary package available on our ZenDNN developer resources page is referred to in this blog as our TF-ZenDNN direct integration version. |
TF-ZenDNN optimizes graphs at the network level and provides tuned primitive implementations at a library level, including Convolution, MatMul, Elementwise, and Pooling (Max and Average). We have seen performance benefits across a variety of neural network models, including the breadth of convolutional neural networks depicted by the orange line below in Graph 1. Optimizing Tencent's AI Applications with the ZenDNN AI Inference Library and TF-ZenDNN impact on TinyDefectNet demonstrates the high performance of ZenDNN and its integration with TensorFlow, respectively.
 |
| Graph 1. Performance uplift of the TensorFlow-ZenDNN plug-in v0.1 and TF-ZenDNN direct integration v4.0 compared to TF-vanilla (without ZenDNN). As optimizations continue to be added to the TensorFlow-ZenDNN plug-in, the extent of performance uplift is expected to compare to that of TF-ZenDNN direct integration. Please see endnotes ZD-045 through ZD-051 at the end of this blog. |
TF-ZenDNN direct integration, as in the binary form described in the section above, requires significant changes in the TensorFlow code. Upstreaming such changes to the TensorFlow repository would be cumbersome and unsustainable. TensorFlow v2.5 provides a PluggableDevice mechanism that enables modular, plug-and-play integration of device-specific code. AMD adopted PluggableDevice when implementing the TensorFlow-ZenDNN plug-in for AMD EPYC CPUs. TensorFlow-ZenDNN plug-in adds custom kernel implementations and operations specific to AMD EPYC CPUs to TensorFlow through its kernel and op registration C API (diagram 2 below).
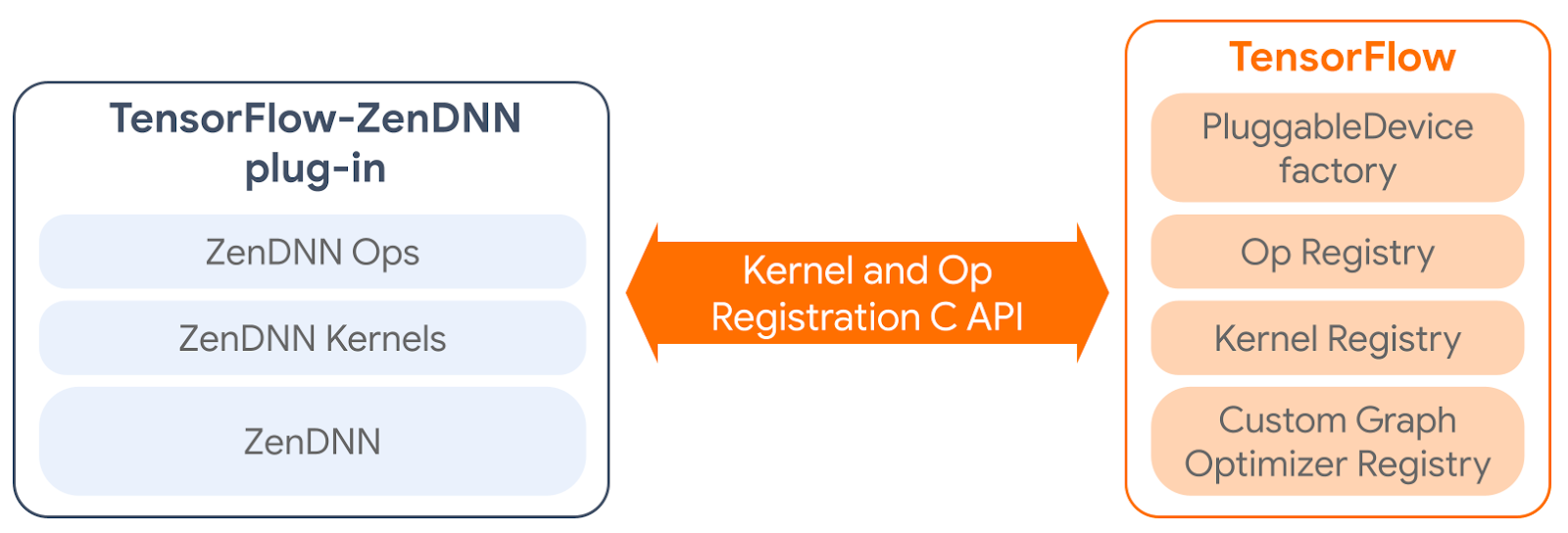 |
| Diagram 2. The TensorFlow-ZenDNN plug-in upstreamed into TFv2.12 enables the addition of custom kernels and operations developed by AMD for performance improvement on AMD EPYC processors. |
The main difference between the TensorFlow-ZenDNN plug-in and TF-ZenDNN direct integration is compatibility with standard TensorFlow packages. TF-ZenDNN direct integration is a standalone package which replaces standard TensorFlow packages. TensorFlow-ZenDNN plug-in is a supplemental package to be installed alongside standard TensorFlow packages starting from TF version 2.12 onwards.
From a TensorFlow developer’s perspective, the TensorFlow-ZenDNN plug-in approach simplifies the process of leveraging ZenDNN optimizations compared to the TF-ZenDNN direct integration approach. With TF-ZenDNN direct integration, the developer needs to download the foundational TensorFlow build and navigate separately to the AMD ZenDNN developer resources page to download the specific TF-ZenDNN binary for integration. In contrast, with the TensorFlow-ZenDNN plug-in approach, everything that a user needs to take advantage of ZenDNN resides on TensorFlow pages, as described further in the next section, “Step-by-Step Guide to using ZenDNN on AMD EPYC Processors''.
The TensorFlow-ZenDNN plug-in, in its first iteration (v0.1), currently offers 16 common ZenDNN ops, including Conv2D, MatMul, BatchMatMul, FusedBatchNorm, AvgPool, and MaxPool. Other ops that are not covered will fall back to TensorFlow’s native kernels. TensorFlow-ZenDNN plug-in provides competitive performance with TF-ZenDNN direct integration package for models such as ResNet, Inception, and VGG variants, as represented in Graph 1 above, with the blue bars representing TensorFlow-ZenDNN plug-in performance and the orange line representing TF-ZenDNN direct integration performance. However, TF-ZenDNN direct integration still outperforms the plug-in for other models, such as MobileNet and EfficientNet, because the plug-in does not yet support graph optimizations that are currently featured in TF-ZenDNN direct integration packages. We expect the performance to be closer once the TensorFlow-ZenDNN plug-in reaches feature parity with TF-ZenDNN direct integration.
Taking advantage of ZenDNN optimizations in TensorFlow is straightforward:
1. Download ZenDNN Plug-in CPU wheel file from the TensorFlow Community Supported Builds webpage.
2. Pip install the ZenDNN plug-in using the following commands:
3. Enable ZenDNN optimizations in your inference flow by setting the following environment variables:
To disable ZenDNN optimizations in your inference execution, you can set the corresponding ZenDNN environment variable to 0:
export TF_ENABLE_ZENDNN_OPTS=0.
TensorFlow-ZenDNN plug-in is supported with ZenDNN v3.3. Please see Chapter 5 of the TensorFlow-ZenDNN Plug-in User Guide for performance tuning guidelines.
For optimal inference performance, AMD recommends using the TF-ZenDNN direct integration binaries available on the AMD ZenDNN developer resources page.
TensorFlow v2.12 marks the first release of our TensorFlow-ZenDNN plug-in. AMD intends to continue improving the performance of the TensorFlow-ZenDNN plug-in on current- and future-generation AMD EPYC processors by supporting more ZenDNN ops, graph optimizations, and quantization in subsequent TensorFlow-ZenDNN plug-in releases. Such enhancements include a planned plug-in version transition from ZenDNN v3.3 to ZenDNN v4.0 to enable optimizations that take advantage of the AVX-512 and VNNI capability in 4th Gen EPYC processors.
With our aim of continuously improving the TensorFlow-ZenDNN plug-in for the community, we encourage TensorFlow developers to test this new TensorFlow-ZenDNN plug-in and share comments and concerns on our ZenDNN GitHub page. Technical support resources can also be reached via the following email address: zendnnsupport@amd.com.
We are excited to continue collaborating with TensorFlow to improve the ZenDNN experience for the wider TensorFlow developer community!
The development and upstreaming of the TensorFlow-ZenDNN plug-in is the work of many people from AMD and the TensorFlow team at Google.
From AMD: Chandra Kumar Ramasamy, Aakar Dwivedi, Savan Anadani, Arun Ramachandran, Avinash-Chandra Pandey, Ratan Prasad, Aditya Chatterjee, Alok Ranjan Srivastava, Prakash Raghavendra, Pradeep Kumar Sinha, Vincent Dee.
From Google: Penporn Koanantakool, Eugene Zhulenev, Douglas Yarrington.
ZD-045 through ZD-051:
Testing conducted by AMD Performance Labs as of Tuesday, February 7, 2023 on test systems comprising of:
AMD System: AMD Eng Sample of the AMD EPYC™ 9004 96-core processor, dual socket, with hyperthreading on, 2150 MHz CPU frequency (Max 3700 MHz), 768GB RAM, 768MB L3 Cache, NPS1 mode, Ubuntu® 20.04.5 LTS version, kernel version 5.4.0-131-generic, BIOS TQZ1000F, GCC/G++ version 11.1.0, GNU ID 2.31, Python 3.8.15. For no ZenDNN, Tensorflow 2.12. For the ZenDNN plug-in, AOCL BLIS 3.0.6, Tensorflow 2.12, ZenDNN version 3.3; for Direct Integration AOCL BLIS 4.0, Tensorflow Version 2.10, ZenDNN 4.0.
Tests run all from Unified Inference Frontend 1.1 (UIF1.1) model zoo:
Results may vary based on factors such as software versions and BIOS settings. ZD-045 thru ZD-051


março 29, 2023 — Posted by Sarina Sit, AMD AMD launched the 4th Generation of AMD EPYC™ processors in November of 2022. 4th Gen AMD EPYC processors include numerous hardware improvements over the prior generation, such as AVX-512 and VNNI instruction set extensions, that are well-suited for improving inference performance. However, hardware is only one piece of the puzzle; software is a crucial component for effe…





