Posted by Marat Dukhan and Frank Barchard, Software Engineers

CPUs deliver the widest reach for ML inference and remain the default target for TensorFlow Lite. Consequently, improving CPU inference performance is a top priority, and we are excited to announce that we doubled floating-point inference performance in TensorFlow Lite’s XNNPack backend by enabling half-precision inference on ARM CPUs. This means that more AI powered features may be deployed to older and lower tier devices.
Traditionally, TensorFlow Lite supported two kinds of numerical computations in machine learning models: a) floating-point using IEEE 754 single-precision (32-bit) format and b) quantized using low-precision integers. While single-precision floating-point numbers provide maximum flexibility and ease of use, they come at the cost of 4X overhead in storage and memory and exhibit a performance overhead compared to 8-bit integer computations. In contrast, half-precision (FP16) floating-point numbers pose an interesting alternative balancing ease-of-use and performance: the processor needs to transfer twice fewer bytes and each vector operation produces twice more elements. By virtue of this property, FP16 inference paves the way for 2X speedup for floating-point models compared to the traditional FP32 way.
For a long time FP16 inference on CPUs primarily remained a research topic, as the lack of hardware support for FP16 computations limited production use-cases. However, around 2017 new mobile chipsets started to include support for native FP16 computations, and by now most mobile phones, both on the high-end and the low-end. Building upon this broad availability, we are pleased to announce the general availability for half-precision inference in TensorFlow Lite and XNNPack.
Half-precision inference has already been battle-tested in production across Google Assistant, Google Meet, YouTube, and ML Kit, and demonstrated close to 2X speedups across a wide range of neural network architectures and mobile devices. Below, we present benchmarks on nine public models covering common computer vision tasks:
These models were benchmarked on 5 popular mobile devices, including recent and older devices (Pixel 3a, Pixel 5a, Pixel 7, Galaxy M12 and Galaxy S22). The average speedup is shown below.
 |
| Single-threaded inference speedup with half-precision (FP16) inference compared to single-precision (FP32) across 5 mobile devices. Higher numbers are better. |
The same models were also benchmarked on three laptop computers (MacBook Air M1, Surface Pro X and Surface Pro 9)
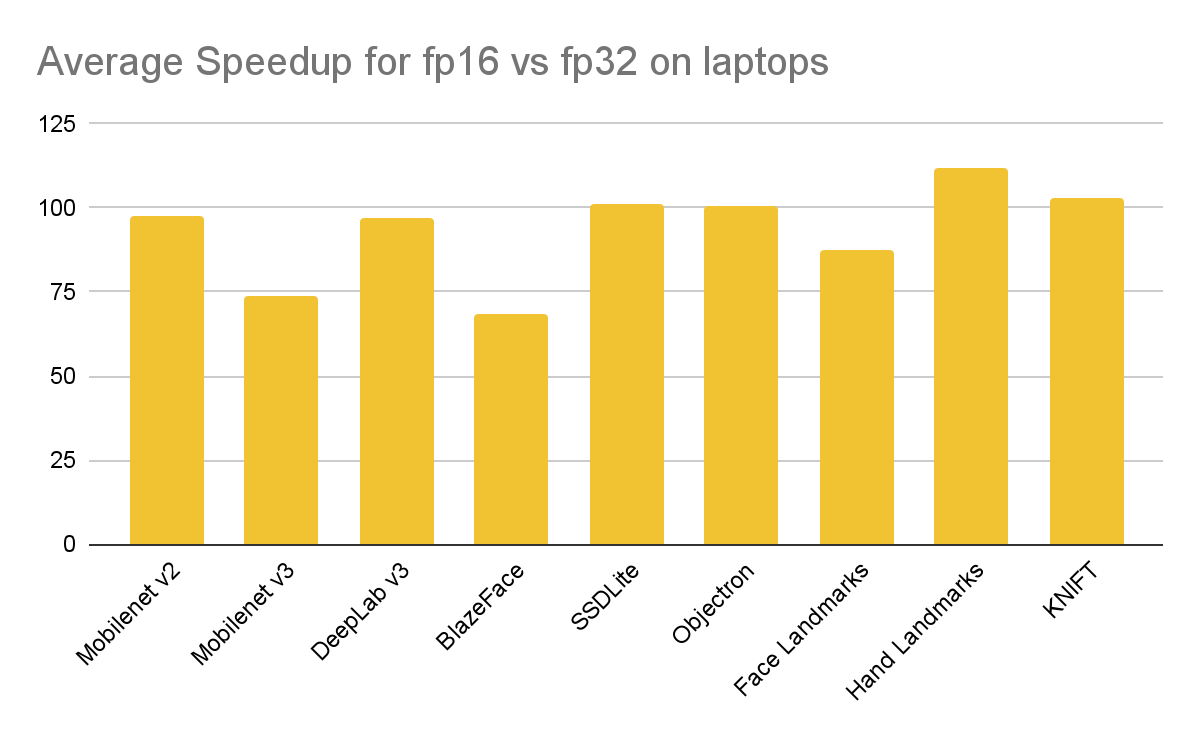 |
| Single-threaded inference speedup with half-precision (FP16) inference compared to single-precision (FP32) across 3 laptop computers. Higher numbers are better. |
Currently, the FP16-capable hardware supported in XNNPack is limited to ARM & ARM64 devices with ARMv8.2 FP16 arithmetics extension, which includes Android phones starting with Pixel 3, Galaxy S9 (Snapdragon SoC), Galaxy S10 (Exynos SoC), iOS devices with A11 or newer SoCs, all Apple Silicon Macs, and Windows ARM64 laptops based with Snapdragon 850 SoC or newer.
To benefit from the half-precision inference in XNNPack, the user must provide a floating-point (FP32) model with FP16 weights and special "reduced_precision_support" metadata to indicate model compatibility with FP16 inference. The metadata can be added during model conversion using the _experimental_supported_accumulation_type attribute of the tf.lite.TargetSpec object:
...
converter.target_spec.supported_types = [tf.float16]
converter.target_spec._experimental_supported_accumulation_type = tf.dtypes.float16
When the compatible model is delegated to XNNPack on a hardware with native support for FP16 computations, XNNPack will transparently replace FP32 operators with their FP16 equivalents, and insert additional operators to convert model inputs from FP32 to FP16 and convert model outputs back from FP16 to FP32. If the hardware is not capable of FP16 arithmetics, XNNPack will perform model inference with FP32 calculations. Therefore, a single model can be transparently deployed on both recent and legacy devices.
Additionally, the XNNPack delegate provides an option to force FP16 inference regardless of the model metadata. This option is intended for development workflows, and in particular for testing end-to-end accuracy of the model when FP16 inference is used. In addition to devices with native FP16 arithmetics support, forced FP16 inference is supported on x86/x86-64 devices with AVX2 extension in emulation mode: all elementary floating-point operations are computed in FP32, then converted to FP16 and back to FP32. Note that such simulation is slow and not a bit-exact equivalent to native FP16 inference, but simulates the effects of restricted mantissa precision and exponent range in the native FP16 arithmetics. To force FP16 inference, either build TensorFlow Lite with --define xnnpack_force_float_precision=fp16 Bazel option, or apply XNNPack delegate explicitly and add TFLITE_XNNPACK_DELEGATE_FLAG_FORCE_FP16 flag to the TfLiteXNNPackDelegateOptions.flags bitmask passed into the TfLiteXNNPackDelegateCreate call:
TfLiteXNNPackDelegateOptions xnnpack_options =
TfLiteXNNPackDelegateOptionsDefault();
...
xnnpack_options.flags |= TFLITE_XNNPACK_DELEGATE_FLAG_FORCE_FP16;
TfLiteDelegate* xnnpack_delegate =
TfLiteXNNPackDelegateCreate(&xnnpack_options);
XNNPack provides full feature parity between FP32 and FP16 operators: all operators that are supported for FP32 inference are also supported for FP16 inference, and vice versa. In particular, sparse inference operators are supported for FP16 inference on ARM processors. Therefore, users can combine the performance benefits of sparse and FP16 inference in the same model.
In addition to most ARM and ARM64 processors, the most recent Intel processors, code-named Sapphire Rapids, support native FP16 arithmetics via the AVX512-FP16 instruction set, and the recently announced AVX10 instruction set promises to make this capability widely available on x86 platform. We plan to optimize XNNPack for these instruction sets in a future release.
We would like to thank Alan Kelly, Zhi An Ng, Artsiom Ablavatski, Sachin Joglekar, T.J. Alumbaugh, Andrei Kulik, Jared Duke, Matthias Grundmann for contributions towards half-precision inference in TensorFlow Lite and XNNPack.


नवंबर 29, 2023 — Posted by Marat Dukhan and Frank Barchard, Software EngineersCPUs deliver the widest reach for ML inference and remain the default target for TensorFlow Lite. Consequently, improving CPU inference performance is a top priority, and we are excited to announce that we doubled floating-point inference performance in TensorFlow Lite’s XNNPack backend by enabling half-precision inference on ARM CPUs. …





